(本文转载自PaperWeekly)
©PaperWeekly 原创 ·作者 |林廷恩
单位 |阿里通义实验室算法研究员
研究方向 |自然语言处理
想象一下,一个 AI 不仅能学习,还能自我改进,变得越来越聪明。这不是科幻小说,而是我们正在见证的现实。大语言模型(LLM)如今正在通过自进化的智能飞轮,不断提升其输出的质量和可靠性。这意味着它们能够适应新的信息和环境,提供更可靠、更有效的帮助。那么,这一切是如何实现的呢?

论文标题:
A Survey on Self-Evolution of Large Language Models
大语言模型的自进化研究综述
论文作者:
林廷恩,武玉川,李永彬
论文链接:
https://arxiv.org/abs/2404.14387
Repo链接:
https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM
背景
随着 AI 领域迎来了大语言模型的爆发,如 ChatGPT、Gemini、LLaMA 和 Qwen 等模型在语言理解和生成方面取得了巨大成就。然而,当前的训练方法需要大量人类监督和外部指导,不仅昂贵,而且在处理复杂任务时逐渐遇到瓶颈。为了解决这些问题,科学家们逐渐关注到一个令人兴奋的新方向:自进化。

1.1 什么是自进化?
简单来说,自进化就是让人工智能像人类一样,通过自己的经验不断学习和提升自己。就像玩游戏一样,从初学者到高手,靠的就是不断的练习和自我提升。
1.2 为什么自进化很重要?
传统的大语言模型需要大量的人类帮助才能提升性能,然而,这样的方法不仅费时费力,而且成本高昂。而自进化的方法则让 AI 可以自主学习,不再依赖大量的人类监督。例如,AlphaGo 曾通过学习 3000 万局棋谱成为围棋高手,但 AlphaZero 仅仅依靠自我对弈,通过三天时间就超越了 AlphaGo,达到了超人类水平。

1.3 自进化带来的突破
科学家们已经在自进化方面取得了一些令人惊叹的成果。例如,DeepMind 的 AMIE 系统在诊断准确性方面超过了初级保健医生,而微软的 WizardLM-2 模型则超越了初版的 GPT-4。这些成功案例表明,自进化不仅是新的训练方法,更是一种可以超越现有数据和人类限制的途径。
1.4 自进化:大语言模型的“智能飞轮”
传统的 AI 训练就像跑一段路,但自进化更像是跑一个循环,不断回到起点变得更强。我们称之为“智能飞轮”,它包括四个阶段:获取经验、改进经验、迭代更新和评估。这四个阶段就像一个完整的进化循环,让大语言模型能够不断迭代和提升自己的能力。
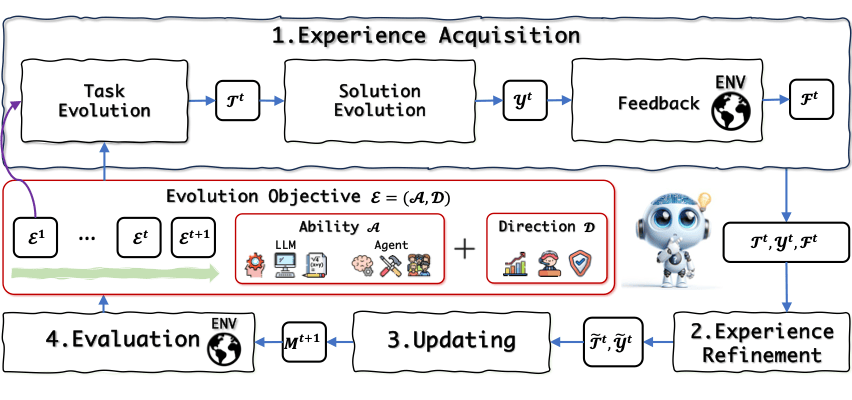
1.5 自进化的四大阶段
1.5.1 获取经验:模型的学习旅程
模型就像一名求知若渴的人,先确定学习目标,然后获取新任务。在完成这些任务的过程中,模型不仅获得正确答案,还从周围环境中收集反馈,积累宝贵的经验。
1.5.2 改进经验:反思与修正
在获取经验后,模型会对这些经验进行反思和修正。就像学生复习功课一样,模型会剔除错误和不完美的数据,确保掌握的信息更加准确和高效。这一步骤帮助模型不断优化自己的知识库,就像人通过反复练习来提高成绩一样。
1.5.3 迭代更新:不断提升
有了改进后的经验,模型就开始更新自己,将新知识整合到现有的框架中。通过这种方式,模型始终保持在最新状态,不断提升自己的性能,以适应新的挑战,逐步提高自己的能力。
1.5.4 评估:衡量与改进
最后,模型会通过各种评估指标来衡量自己的表现。这一阶段的结果为后续的进化设定了新的目标,形成一个自我完善的闭环过程。通过不断的评估和反馈,模型能够识别出自己的不足,并在下一个迭代周期中进行改进,实现持续的自我提升。就像人通过考试和反馈,发现自己的弱点,并在下一次学习中努力改进。
1.6 自进化的进化目标

就像人类设定个人目标一样,进化目标引导模型的发展,由进化能力和进化方向所组成:
进化能力:包括基于大模型与智能体的能力:
基于大模型的能力:
指令跟随:模型能够准确理解并执行用户的指令。 推理:具备逻辑推理和问题解决的能力。 数学:在数学运算和问题解决中的表现。 编码:在编程和代码生成方面的能力。 角色扮演:模拟和参与不同角色对话的表现。基于智能体的能力:
规划:为未来行动制定策略和准备,并创建一系列步骤以实现特定目标。 工具使用:在环境中使用各种工具(如 API)来执行任务或解决问题。 具身控制:在环境中管理和协调其物理形态的能力。包括移动和物体操作。 沟通协作:传达信息和理解信息的技能,包括心智理论能力建模。进化方向:提高模型的特定能力或特性:
改进性能:提升整体输出质量和准确性。 适应反馈:根据用户反馈自我调整和改进。 更新知识库:保持知识库的最新和全面性。 安全性:确保输出内容安全、无害。 减少偏见:尽量消除输出中的偏见,提供公正客观的回答。下面,我们将详细介绍自进化的技术路线,具体如下:

获取经验
获取经验是推动自进化的第一步。这一过程既包括探索,也包括利用现有知识。让我们一同揭开这个过程,看看 LLM 是如何通过任务进化、答案进化和反馈获取来变得更聪明的。
2.1 任务进化
任务进化是启动整个进化过程的关键步骤,模型首先根据进化目标来获取任务。任务进化的方法可以分为基于外部知识、不基于外部知识和基于选择的三种。
基于外部知识的任务进化:AI 利用外部知识生成相关任务,确保任务的真实和有效。例如,Ditto 使用像 Wikidata 和 Wikipedia 这样的知识库生成对话任务,而 UltraChat 则从非结构化语料中生成问题或指令。 不基于外部知识的任务进化:AI 通过自身的能力生成新任务,增加任务的多样性。例如,Self-Instruct 方法通过自我生成指令来创建新任务,而 Evol-Instruct 则通过扩展指令的复杂性和多样性来实现这一目标。 基于选择的任务进化:AI 从现有任务中选择最相关的任务,而不是生成新任务,从而简化进化过程。Diverse-Evol 方法通过采样策略从任务池中选择多样化的任务,提升 AI 的指令遵循能力。2.2 答案进化
获得任务后,AI 通过不同策略来解决这些任务,答案进化分为正向和负向两种方法。
正向答案进化:
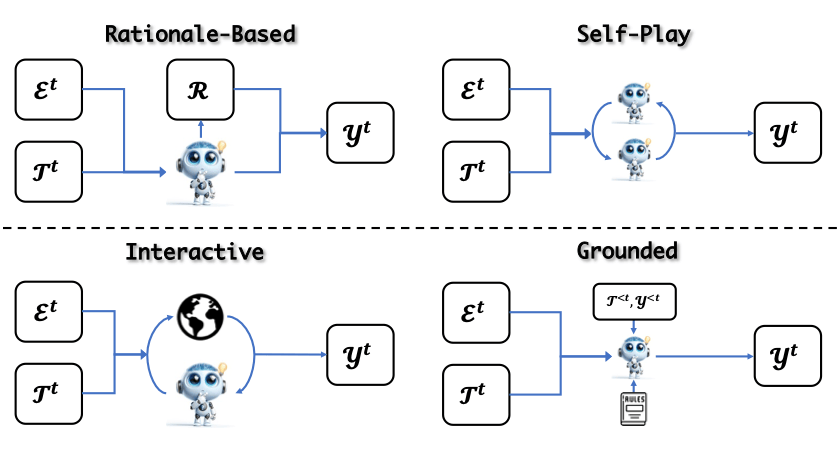
负向答案进化:此类方法通过识别和收集不符合预期的模型行为,改善偏好对齐和安全性,可分为以下两类:

2.3 获取反馈
反馈在 AI 自进化中扮演着至关重要的角色,帮助 AI 证明解决方案的正确性并促进技能更新。主要分为两类:
获取模型反馈:AI 基于自身提供反馈内容,包括打分与评语。例如,Self-Alignment 引入自我评估模块和知识调优策略,提高AI在知识密集型任务中的事实准确性。获取环境反馈:常见于可以直接执行解决方案的任务中,反馈来源包括代码解释器、工具执行等。例如,Self-Debugging 利用测试用例的执行结果作为反馈,使 AI 能够自我诊断和修正代码错误,显著提高编程任务性能。
改进经验
在获得经验后,大语言模型可以通过自我改进经验来提高其输出的质量和可靠性。这种方法分为两大类:过滤(Filtering)和纠正(Correcting)。
3.1 基于过滤的改进经验
通过过滤策略,模型只会使用最可靠和高质量的数据进行更新。目前,主要有两种过滤策略:
基于指标的:利用反馈或预定义指标进行筛选。比如,ReST^{EM} 通过多次采样数据、生成答案并使用反馈进行过滤,不依赖大量人工数据,逐步提高模型推理效果。 不基于指标的:通过内部一致性或模型特有标准进行评估,提高灵活性和适应性。例如,Universal Self-Consistency 提出了一种通用一致性方法,在数学推理、代码生成等领域显著提高大模型效果。3.2 基于纠正的改进经验
基于模型来迭代改进其经验。现有的纠正策略分为两种:
基于评语的:通过评语发现潜在错误或次优输出,并提出解决方案,引导模型改进。Self-Refine 通过迭代反馈和改进输出,在对话、代码生成等任务中效果显著提升。不基于评语的:直接利用客观信息进行纠正,避免潜在偏见影响。STaR 利用少量带有思维链的示例和大量无思维链的数据集,逐步提升模型的复杂推理能力。
更新
在改进经验的基础上,我们可以利用这些数据进行模型的迭代更新。主要方法分为两种:基于权重(In-Weight)和基于上下文(In-context)的迭代更新。
4.1 基于权重的迭代更新
在自我进化的训练过程中,核心挑战在于提升整体能力并防止灾难性遗忘。主要有三种策略:
基于重放的:将新数据混入旧数据,防止遗忘以前的知识。例如,AMIE 融合已有医疗知识问答和生成的模拟医疗对话,提高诊断准确性。 基于正则约束的:限制模型更新,防止与原始行为出现重大偏差。例如,WARM 通过微调多个奖励模型并加权平均,降低强化学习中的风险。 基于架构的:利用额外的参数或模型进行更新。例如,EvoLLM 提出自进化的模型融合方法,使模型具备跨领域能力。4.2 基于上下文的迭代更新
除了更新模型参数外,还可以利用 LLM 的上下文学习能力,实现快速自适应更新,常见于 Agent 应用中。主要方法有两种:
基于外部记忆的:通过外部模块收集和检索经验,在不更新模型参数的情况下实现更好的结果。例如,TRAN 从过去失败经验中总结规则,提高后续问题解决正确率。基于工作记忆的:利用过去经验,通过更新内部记忆流来提升效果。例如,Reflexion 通过反馈和反思,迭代增强 Agent 效果。
评估
准确自动地评估模型性能,并为后续改进提供方向,是个重要但缺乏研究的领域。评估方法主要有两种:
量化评估:通过具体数字或分数来评估。例如,LLM-as-a-Judge 用大语言模型评价其他模型,评估方法与人类评判一致性接近 80%。
质化评估:通过分析模型的不足之处提供更深入的评估。例如,Chateval 通过多智能体辩论,潜在能帮助指导后续迭代目标。
未来挑战与展望
随着大语言模型自进化的发展,当前工作也面临着诸多挑战:
自进化目标:多样性与层次性
目前的进化目标还不够全面。大模型已应用于各行各业,我们需要一个覆盖更多实际任务的自进化框架,提升多样性,让它适应更广泛的应用。
自主性等级

自进化框架的自主性程度可以分为低、中、高三类:
低自主性:用户预定义进化目标,设计进化管道,模型根据设计框架完成自进化。 中自主性:用户仅设定进化目标,模型独立构建每个模块,实现自进化。 高自主性:模型诊断自身缺陷,设定进化目标并设计具体模块,实现完全自主的自进化。大多数现有研究仍处于低自主性水平,需要专家设计具体模块,随着自进化框架的发展,中高自主性的研究亟需更多关注。
经验获取与改进:从经验到理论
自进化研究多依赖经验,缺乏理论支持,机制尚不明确。需要更多理论探索,确保自进化有效改进。
迭代更新:稳定性与可塑性
我们需要在保持已有知识稳定性和适应新任务的可塑性之间找到平衡,现有方法效果有限,需寻找高效稳定的迭代更新方法。
评估:系统化和动态进化
开发动态评测集,以适应不断进化的模型,避免静态评测集过时或被模型记住。
安全性和超级对齐

随着大模型智能水平逐步超越人类,确保其与人类伦理和价值观对齐至关重要。OpenAI 的 Superalignment 计划正致力于此。
结语
大语言模型的自进化能力正在引领人工智能领域的变革,参考人类学习过程,克服现有训练范式对人工标注和教师模型的依赖,显著提高性能和应用广泛性。我们通过详细介绍自进化框架、获取经验、改进经验、迭代更新、评估及未来挑战,提供了全面的理解和最新的研究进展。未来,随着自进化框架的不断发展和完善,人工智能系统将具备更强的适应能力和智能水平,有望在复杂的实际任务中不断超越人类表现。
版块介绍 — 技术之辩
我们聚焦于AI及更广泛科技领域的前沿动态,追踪人工智能芯片与模型的技术演进,不仅分享最新研究成果,更开启技术伦理、发展趋势的深度辩论。每一次探讨,都是对未来可能性的一次勇敢探索,让思想的火花在这里碰撞,照亮技术前行的道路。
Reading
1、开源模型越来越落后?meta甩出全新Llama 3应战
2、通义千问一周年,开源狂飙路上的抉择与思考|魔搭深度访谈
3、Claude 3拒答率优化:大模型从拒答到负责任回答的演进之路
4、清华经管研究证明:生成式AI工具显著提升人机协同效能
- END -








 京公网安备 11011402013531号
京公网安备 11011402013531号