8 月 30 日消息,通义千问团队今天对 Qwen-VL 模型进行更新,推出 Qwen2-VL。
Qwen2-VL 的一项关键架构改进是实现了动态分辨率支持(Naive Dynamic Resolution support)。与上一代模型 Qwen-VL 不同,Qwen2-VL 可以处理任意分辨率的图像,而无需将其分割成块,从而确保模型输入与图像固有信息之间的一致性。这种方法更接近地模仿人类的视觉感知,使模型能够处理任何清晰度或大小的图像。
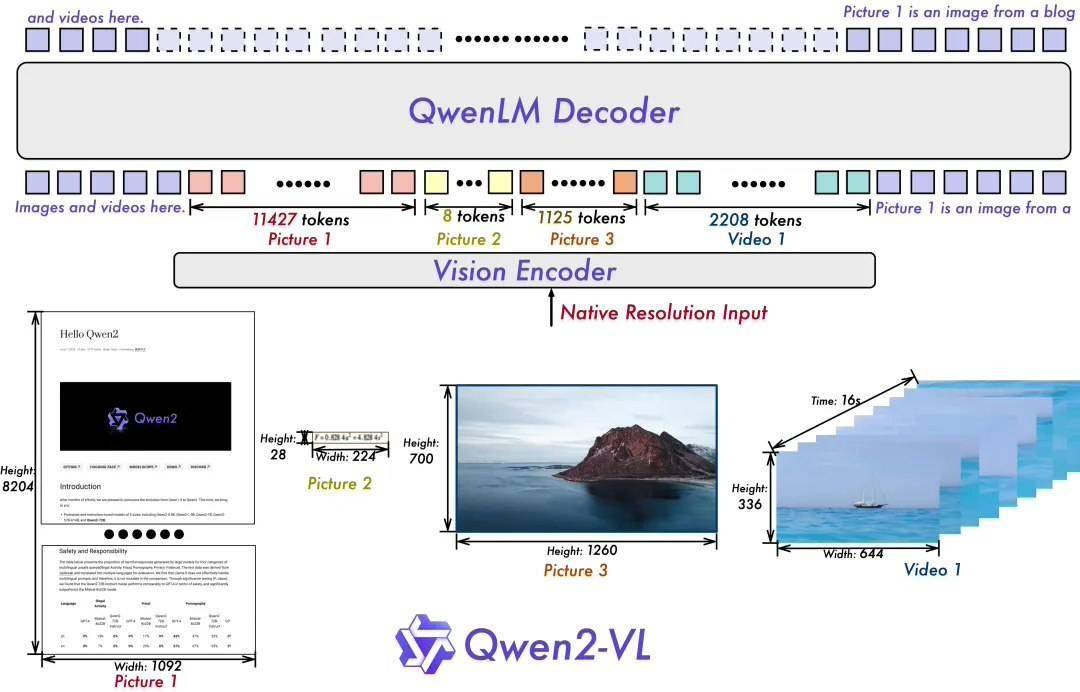
另一个关键架构增强是 Multimodal Rotary Position Embedding(M-ROPE)。通过将 original rotary embedding 分解为代表时间和空间(高度和宽度)信息的三个部分,M-ROPE 使 LLM 能够同时捕获和集成 1D 文本、2D 视觉和 3D 视频位置信息。这使 LLM 能够充当多模态处理器和推理器。
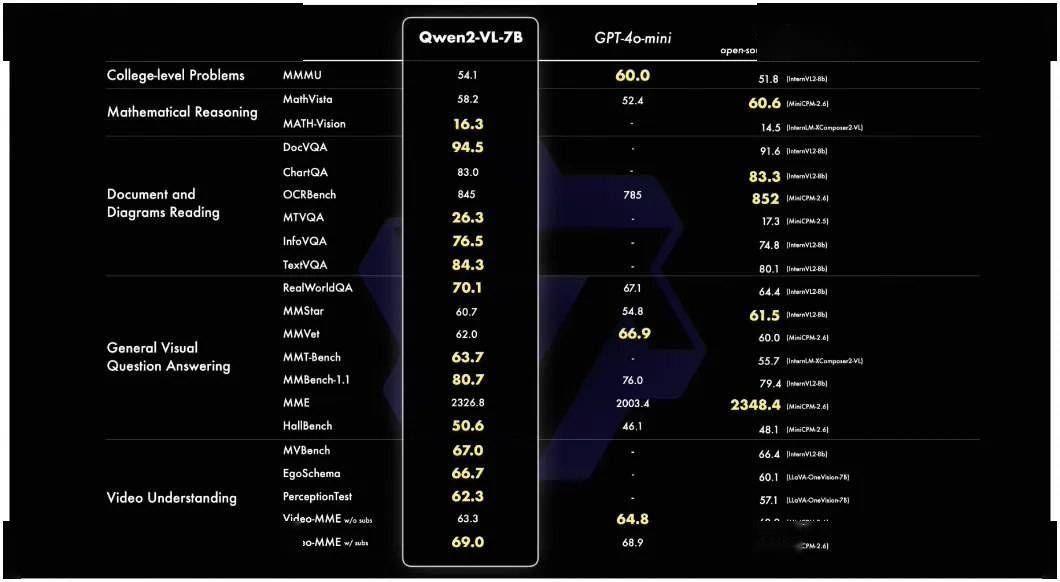
在 7B 规模下,Qwen2-VL-7B 保留了对图像、多图像和视频输入的支持,以更具成本效益的模型大小提供“具有竞争力”的性能。
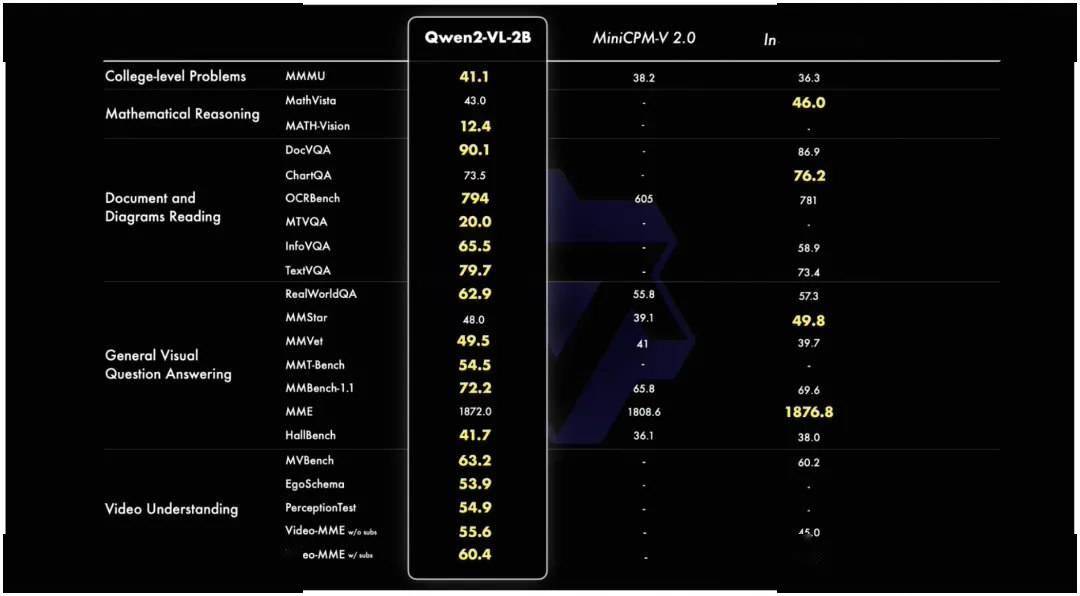
Qwen2-VL-2B 模型针对潜在的移动部署进行了优化。尽管参数量只有 2B,但官方表示该模型在图像、视频和多语言理解方面表现出色。
附模型链接如下:
Qwen2-VL-2B-Instruct:https://www.modelscope.cn/models/qwen/Qwen2-VL-2B-Instruct Qwen2-VL-7B-Instruct:https://www.modelscope.cn/models/qwen/Qwen2-VL-7B-Instruct






 京公网安备 11011402013531号
京公网安备 11011402013531号