
报道
编辑:编辑部
继5月的文件泄露事件后,谷歌的搜索引擎又被掀了个底朝天。不仅DeepMind发论文解释了Vizier系统的机制,博客作者Mario Fischer还对近百份文档做了彻底的调研分析,为我们还原了这个互联网巨兽的全貌。
谷歌发表的论文又开始揭自家技术的老底了。
DeepMind高级研究科学家Xingyou (Richard) Song等人最近发表的论文中,解释了谷歌Vizier服务背后的算法秘密。

作为一个运行过数百万次的黑盒优化器,Vizier帮助谷歌内部优化了很多研究和系统;同时,谷歌云和Vertex也上线了Vizier服务,帮助研究者和开发人员进行超参数调整或黑盒优化。
Song表示,与Ax/BoTorch、HEBO、Optuna、HyperOpt、SkOpt等其他行业基线相比,Vizier在很多用户场景中都有更稳健的表现,比如高维度、批查询、多目标问题等。
趁着论文发布,谷歌元老Jeff Dean也发推赞扬Vizier系统。

他提到的开源版Vizier已经托管在GitHub仓库上,有非常详细的文档说明,并且最近仍在持续维护更新。

仓库地址:https://github.com/google/vizier

OSS Vizier 的分布式客户端-服务器系统
虽然谷歌研究院早在2017年就发文讨论过整个Vizier系统,但内容远没有最新的这篇详实。
论文地址:https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf
这篇技术报告包含了大量研究工作的成果和用户反馈,在描述开源Vizier算法的实现细节和设计选择的同时,用标准化基准的实验表现了Vizier在多种实用模式上的稳健性和多功能性。
论文地址:https://arxiv.org/abs/2408.11527
其中,Vizier系统迭代过程的经验教训也被一一展示,这对学界和行业都有很大的借鉴意义,值得一观。
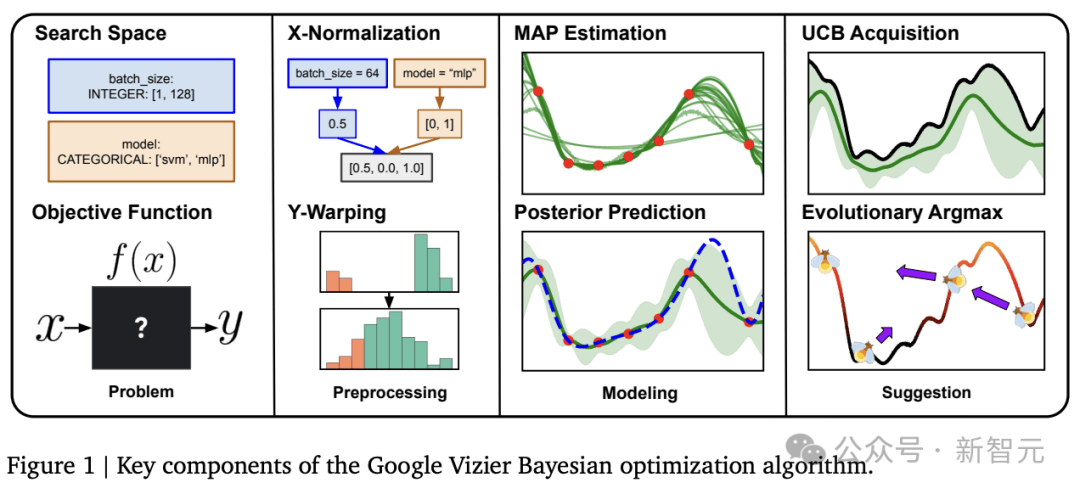
Vizier系统所用贝叶斯算法的核心组件
文章的主要贡献如下:
- 正式确认了Vizier当前版本的默认算法并解释其功能、设计选择,以及整个迭代过程中吸取的经验教训
- 在原始的C++实现基础上提供了开源的Python和JAX框架实现
- 使用行业通用基准进行测试,体现了Vizier在高维、分类、批量和多目标优化等模式下的稳健性
- 对零阶进化采集优化器(zeroth-order evolutionary acquisition optimizer)这个非常规的设计选择进行了消融实验,展示并讨论了其中的关键优势
论文作者列表中排名前二的是两个Richard——
Xingyou (Richard) Song曾在OpenAI担任强化学习泛化方面的研究员,2019年以高级研究科学家的身份加入Google Brain,并从2023年起担任DeepMind高级研究科学家,从事GenAI方面的工作。

Qiuyi (Richard) Zhang目前在DeepMind Vizier团队中工作,也是开源版Vizier的共同创建者,他的研究主要关注超参数优化、贝叶斯校准和理论机器学习方向,此外在AI对齐、反事实/公平性等方面也有涉足。

2014年,Zhang以优秀毕业生的身份从普林斯顿大学获得学士学位,之后在加州大学伯克利分校获得获得应用数学和计算机科学的博士学位。
搜索引擎机制大起底
作为绝对的行业巨头,谷歌很多未被披露的核心技术都让外界好奇已久,比如,搜索引擎。
十多年来超过90%的市场份额,让谷歌搜索成为了或许是整个互联网上最具影响力的系统,它决定了网站的生死存亡及网络内容的呈现形态。
但谷歌究竟是如何对网站进行排名的具体细节,从来都是「黑匣子」。
不像Vizier这类产品,搜索引擎既是谷歌的财富密码,也是看家技术,官方发论文披露是不可能的。
虽然也有媒体、研究人员以及从事搜索引擎优化工作的人士进行过种种猜测,但也只是盲人摸象。
旷日持久的谷歌反垄断诉讼最近宣布判决,美国的各级检察官搜罗了约500万页的文件,变成公开的呈堂证供。
然而,谷歌内部文档泄露和反垄断听证会的公开文件等等,并没有真正告诉我们排名的具体工作原理。
并且,由于机器学习的使用,自然搜索结果的结构非常复杂,以至于参与排名算法开发的谷歌员工也表示,他们并不能完全理解许多信号权重的相互作用,无法解释为什么某个结果会排在第一或第二。
5月27日,一位匿名消息人士(后证实为搜索引擎优化行业资深从业者Erfan Azimi)曾向SparkToro公司的CEO Rand Fishkin提供了一份2500页的谷歌搜索API泄露文档,揭示了谷歌搜索引擎内部排名算法的详细信息。

但这还不是全部。
专门报道搜索引擎行业的新闻网站Search Engine Land最近还发表了一篇博客,根据数千份泄露的谷歌法庭文件进行逆向工程,首次揭秘谷歌网络搜索排名的核心技术原理。

原文链接:https://searchengineland.com/how-google-search-ranking-works-445141
这篇博文是原作者在几周的工作中对近100份文档经过多次查看、分析、结构化、丢弃和重组之后才诞生的,虽然并不一定严格准确或面面俱到,但可以说是了解谷歌搜索引擎绝无仅有的全面且详细的资料。
作者的省流版结构示意图如下:
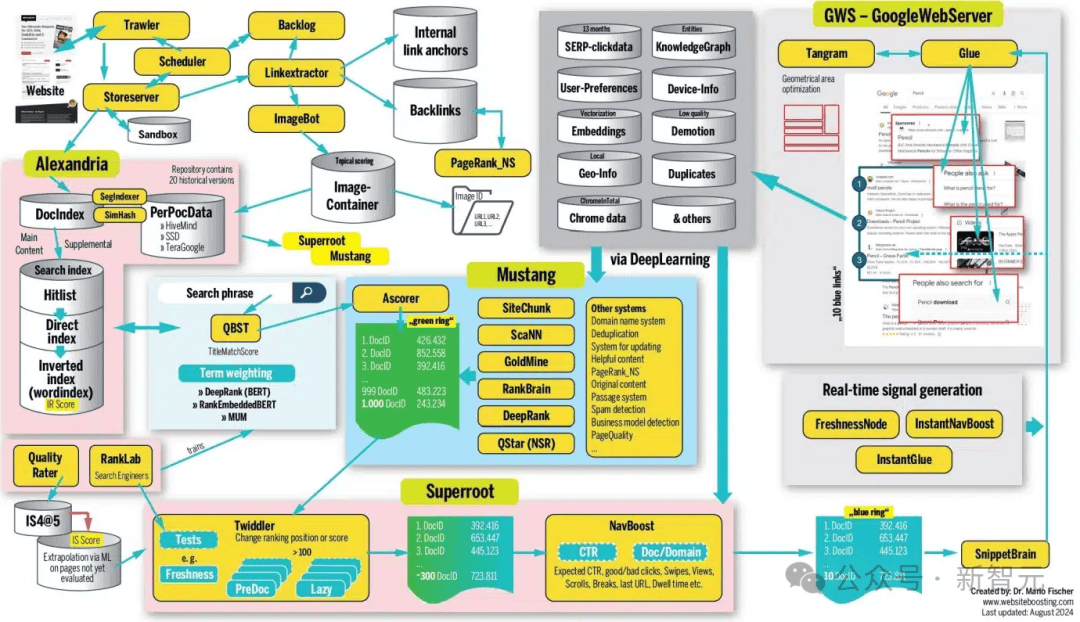
毫无疑问,谷歌搜索引擎是一个庞大而复杂的工程。从爬虫系统、存储库Alexandria、粗排名Mustang,再到过滤和细排名系统Superroot以及负责最终呈现页面的GWS,这些都会影响网站页面最终的呈现和曝光。
新文件:等待Googlebot访问
当一个新网站发布时,它不会立刻被谷歌索引,谷歌如何通过收集和更新网页信息呢?
第一步就是爬虫和数据收集,谷歌首先需要知道该网站URL的存在,网站地图的更新或放置URL链接可以让谷歌抓取到新网站。
并且,频繁被访问的页面链接能更快地引起谷歌的注意。
爬虫系统(trawler system)会抓取新内容,并记录何时重新访问URL以检查网站更新,这由一个称为调度器的组件管理。
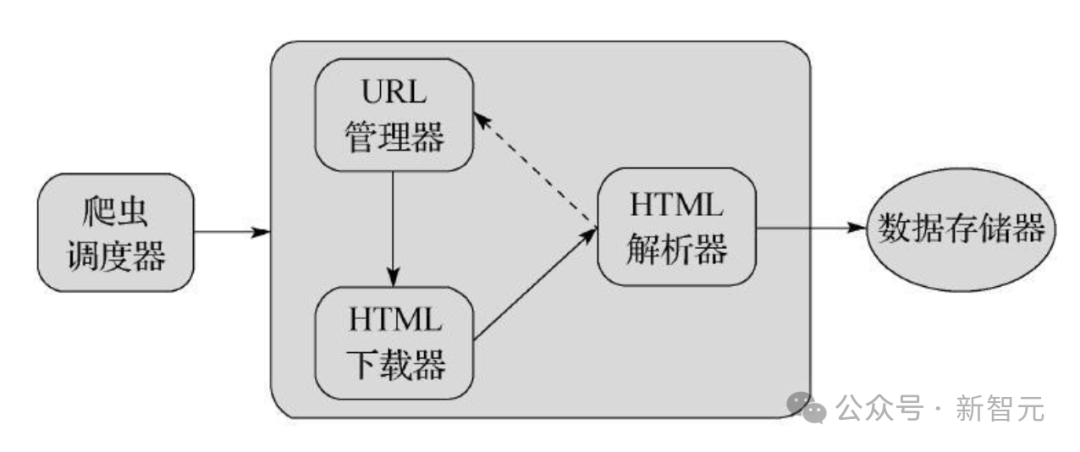
接着,存储服务器决定是否转发该URL或是否将其放到沙箱(sandbox)中。
谷歌之前一直否认沙箱的存在,但最近的泄露信息表明,(可疑的)垃圾网站和低价值网站也会被放入沙箱,谷歌显然会转发一些垃圾网站,可能是为了进一步分析内容和训练算法。
然后,图像链接被传输到ImageBot中,以便后续的搜索调用,有时会出现延迟的情况,ImageBot有分类功能,能够将相同或相似的图片放置在一个图像容器中。
爬虫系统似乎使用自己的PageRank来调整信息抓取频率,如果一个网站的流量更大,这个抓取频率就会增加(ClientTrafficFraction)。
Alexandria:谷歌索引系统
谷歌的索引系统被称为Alexandria,为每个网页内容分配唯一的DocID。如果出现内容重复的情况,则不会创建新的ID,而是将URL链接到已有的DocID。
谷歌会明确区分URL和文档:一个文档可以由多个包含相似内容的URL构成,包括不同语言版本,所有这些URL都由同一个DocID进行调用。
如果碰到不同域名的重复内容,谷歌会选择在搜索排名中会显示规范版本。这也解释了为什么其他的URL有时可能会有相似的排名。并且,所谓「规范」版本的URL也不是一锤子买卖,而是会随着时间发生变化。

Alexandria收集文档的URL
作者的文档在网上只有一个版本,因此它被系统赋予了自己的DocID。
有了DocID之后,文档的各个部分都会搜索出关键词并汇总到搜索索引(search index)中。「热词列表」(hit list)中汇总了每页多次出现的关键词,会先被发送到直接索引(direct index)中。
以作者的网页为例,由于其中多次出现「pencil」一词,在词汇索引(word index)中,DocID就列在「pencil」条目下。
算法会根据各种文本特征计算出文档中「铅笔」一词的IR(信息检索)分数并分配给DocID,稍后用于发布列表(Posting List)。
比如,文档中「pencil」一词被加粗,并包含在一级标题中(存储在AvrTermWeight中),这类信号都会增加IR得分。
谷歌会将重要的文档移至HiveMind,即主内存系统,同时使用快速SSD和传统HDD(称为TeraGoogle)来长期存储不需要快速访问的信息。
值得注意的是,专家估计,在最近的AI热潮之前,谷歌掌握了全球约半数的网络服务器。
一个庞大的互联集群网络能够让数百万个主存单元一起工作,一位谷歌工程师曾在一次会议上指出,理论上,谷歌的主存储器可以存储整个网络。
有趣的是,存储在HiveMind中的重要文档的链接以及反向链接似乎有更高的权重,而HDD(TeraGoogle)中的URL链接可能权重较低,甚至可能不被考虑。
每个DocID的附加信息和信号都以动态方式存储在PerDocData中,这个存储库保存了每个文档最近的20个版本(通过CrawlerChangerateURLHistory),许多系统在调整相关性时都会访问这些信息。
并且,谷歌有能力随着时间变化评估不同的版本。如果想要完全更改文档的内容或主题,理论上需要创建20个过渡版本来完全覆盖掉旧的版本。
这就是为什么恢复一个过期域名(一个曾经活跃,但之后由于破产或其他原因被放弃或出售的域名)不会保留原来域名的排名优势。
如果一个域名的Admin-C和其主题内容同时发生变化,机器可以轻松识别出这一点。
此时,谷歌会将所有信号置零,曾经有流量价值的旧域名不再提供任何优势,与全新注册的域名无异,接手旧域名并不意味着接手原本的流量和排名。

除了泄密事件之外,美国司法机构针对谷歌的听证会和审判的证据文件也是有用的研究来源,甚至包含内部电子邮件
QBST:有人在搜索「pencil」
当有人在谷歌中输入搜索词「pencil」时,QBST(Query based Salient Terms)开始工作。
QBST负责分析用户输入的搜索词,根据重要性和相关性为其中包含的各个词语分配不同的权重,并分别进行相关DocID的查询。
词汇加权过程相当复杂,涉及RankBrain、DeepRank(前身为BERT)和RankEmbeddedBERT等系统。
QBST对于SEO很重要,因为它会影响Google对搜索结果的排名,从而影响网站可以获得多少流量和可见度。
如果网站包含与用户查询匹配最常用的术语,QBST就会让网站排名更高。
经过QBST后,相关词汇如「pencil」,会被传递给Ascorer做进一步处理。
Ascorer:创建「绿环」
Ascorer从倒排索引(即词汇索引)中提取「pencil」条目下的前1000个DocID,按IR得分排名。
根据内部文件,这个列表称为「绿环」。在业内,这被称为发布列表(posting list)。
在我们关于「铅笔」例子中,相应文档在发布列表中排名第132位。如果没有其他系统的介入,这将是它的最终位次。
Superroot:「千里挑十」
Superroot负责对刚刚Mustang筛选出的1000个候选网页重新排名,将1000个DocID的「绿环」缩减为10个结果的「蓝环」。
这个任务具体由Twiddlers和NavBoost执行,其他系统可能也有参与,但由于信息不准确,具体细节尚不清楚。

Mustang生成1000个潜在结果,Superroot将其过滤为10个
Twiddlers:层层过滤
各种文件表明,谷歌使用了数百个Twiddler系统,我们可以将其视为类似于WordPress插件中的过滤器。
每个Twiddler都有自己特定的过滤目标,可以调整IR分数或者排名位次。
之所以用这种方式设计,是因为Twiddler相对容易创建,而且无需修改 Ascorer中复杂的排名算法。
排名算法的修改非常具有挑战性,因为涉及潜在的副作用,需要大量的规划和编程。相反,多个Twiddler并行或顺序操作,并不知道其他Twiddler的活动。
Twiddler基本可以分为两种类型:
-PreDoc Twiddlers可以处理几百个DocID的集合,因为它们几乎不需要额外的信息;
-相反,「Lazy」类型的Twiddler需要更多的信息,例如来自PerDocData数据库的信息,需要相对更长的时间和更复杂的过程。
因此,PreDocs先接收发布列表并减少网页条目,然后再使用较慢的「Lazy」类型的过滤器,两者结合使用大大节省了算力和时间。

两种类型的、超过100个Twiddler负责减少潜在的搜索结果数量并重新排序
经过测试,Twiddler有多种用途,开发者可以尝试使用新的过滤器、乘数或特定位置限制,甚至可以做到非常精准的操控,将一个特定的搜索结果排名到另一个结果的前面或后面。
谷歌的一份泄露的内部文件显示,某些Twiddler功能应仅由专家与核心搜索团队协商后使用。

如果您认为自己了解Twidder的工作原理,请相信我们:您不了解。我们也不确定自己是否了解
还有一些Twiddlers仅用于创建注释,并将这些注释添加到DocID中。
在COIVD期间,为什么你所在国家的卫生部门在COVID-19搜索中总是排在第一位?
那正是因为Twiddler会根据语言和地区,使用queriesForWhichOfficial来促进官方资源的精确分配。
虽然开发者无法控制Twiddler重新排序的结果,但了解其机制可以更好地解释排名波动和那些「无法解释的排名」。
质量评估员和RankLab实验室
全球范围内有数千名质量评估员负责为谷歌评估搜索结果,对新算法或过滤器进行上线前的测试。
谷歌表示,他们的评分仅供参考,不会直接影响排名。
这本质上是正确的,但他们的评分和投标票的确对排名产生了极大的间接影响。
评估员通常在移动设备上进行评估,从系统接收URL或搜索短语,并回答预设的问题。
例如,他们会被问到,「这篇内容作者和创作实践是否清晰?作者是否拥有该主题的专业知识?」
这些答案会被存储起来并用于训练机器学习算法,让算法能够更好地识别高质量、值得信赖的页面,和不太可靠的页面。
也就是说,人类评估者提供的结果成为深度学习算法的重要标准,谷歌搜索团队创建的排名标准反而没那么重要。
想象一下,什么样的网页会让人类评估者觉得可信?
如果某个网页包含作者的照片、全名和linkedIn链接,通常会显得令人信服。反之,缺乏这些特征的网页会被判定为不那么可信。
接着,神经网络将识别这一特征为关键因素,经过至少30天的积极测试运行,模型可能开始自动将此特征用作排名标准。
因此,具有作者照片、全名和linkedIn链接的页面可能会通过Twiddler机制获得排名提升,而缺乏这些特征的页面则会出现排名下降。
另外,根据谷歌泄露的信息,通过isAuthor属性和AuthorVectors属性(类似于「作者指纹识别」),可以让系统识别并区分出作者的独特用词和表达方式(即个人语言特征)。
评估员的评价被汇总成「信息满意度」(IS)分数。尽管有许多评估员参与,但IS评分仅适用于少数URL。
谷歌指出,许多没有被点击的文档可能也很重要。当系统无法进行推断时,文档会被自动发送给评估员并生成评分。
评估员相关的术语中提到了「黄金」,这表明某些文档可能有一个「黄金标准」,符合人类评估员的预期可能有助于文档达到「黄金」标准。
此外,一个或多个Twiddler系统可能会将符合「黄金标准」的DocID推进排名前十。
质量评估员通常不是谷歌的全职员工,而是隶属于外包公司。
相比之下,谷歌自己的专家在RankLab实验室中工作,负责进行实验、开发新的Twiddler以及进行评估和改进,看Twiddler能否提高结果质量还是仅仅只能过滤掉垃圾邮件。
经过验证并有效的Twiddler随后被集成到Mustang系统中,使用了复杂、互连且计算密集型的算法。
NavBoost:用户喜欢什么?
在Superroot中,另一个核心系统NavBoost在搜索结果排名方面也发挥着重要作用。

Navboost主要用于收集用户与搜索结果交互的数据,特别是他们对不同查询结果的点击量。
尽管谷歌官方否认将用户点击数据用于排名,但联邦贸易委员会(FTC)披露的一封内部电子邮件指示,点击数据的处理方式必须保密。
谷歌对此进行否认涉及两方面的原因。
首先,站在用户的角度来看,谷歌作为搜索平台无时无刻监视用户的在线活动,这会引起媒体对于隐私问题的愤怒。
但站在谷歌的角度来看,使用点击数据是为了获得具有统计意义的数据指标,而不是监控单个用户。
FTC文件确认了点击数据将会影响排名,并频繁提到NavBoost系统(在2023年4月18日的听证会上提到54次),2012年的一次官方听证会也证明了这一点。

自2012年8月起,官方明确表示点击数据会影响排名
搜索结果页面上的各种用户行为,包括搜索、点击、重复搜索和重复点击,以及网站或网页的流量都会影响排名。
对用户隐私的担忧只是原因之一。另一种担忧是,通过点击数据和流量进行评估,可能会鼓励垃圾邮件发送者和骗子使用机器人系统伪造流量来操纵排名。
谷歌也有反制这种情况的方法,例如通过多方面的评估将用户点击区分为不良点击和良好点击。
所使用的指标包括在目标页面的停留时间、在什么时间段查看网页、搜索的起始页面、用户搜索历史中最近一次「良好点击」的记录等等。
对于每个在搜索结果页面(SERPs)中的排名,都有一个平均预期点击率(CTR)作为基准线。
例如,根据Johannes Beus在今年柏林CAMPIXX大会上的分析指出,自然搜索结果的第1位平均获得26.2%的点击,第2位获得15.5%的点击。
如果一个CTR显著低于预期的比率,NavBoost系统会记录下这一差距,并相应地调整DocID的排名。
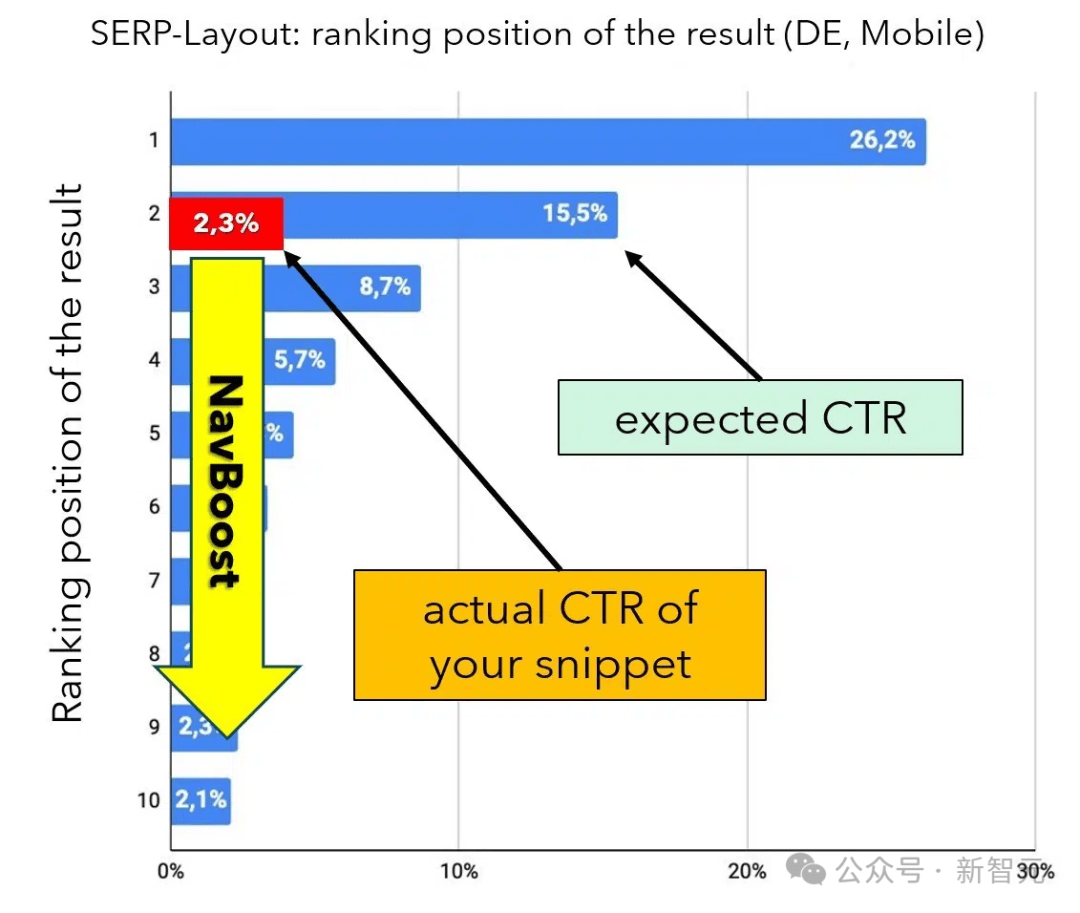
如果「expected_CRT」与实际值偏差较大,则排名会相应调整
用户的点击量基本上代表了用户对结果相关性的意见,包括标题、描述和域名。
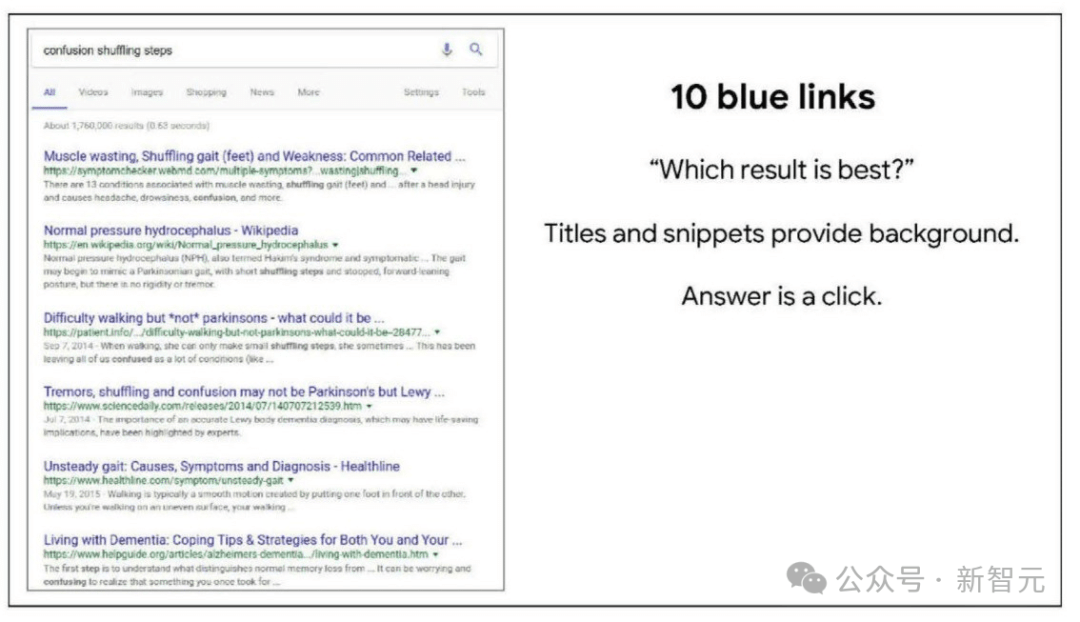
根据SEO专家和数据分析师的报告,当全面监控点击率时,他们注意到了以下现象:
如果一个文档在搜索查询中进入前10名,而CTR显著低于预期,可以观察到排名将在几天内下降(取决于搜索量)。
相反,如果CTR相对于排名来说高得多,排名通常会上升。如果CTR较差,网站需要在短时间内调整和优化标题和内容描述,以便获得更多的点击。
计算和更新PageRank是耗时且计算密集的,这就是使用PageRank_NS指标的原因。NS代表「最近的种子」,一组相关页面共享一个PageRank值,该值暂时或永久地应用于新页面。
谷歌在一次听证会上就如何提供最新信息树立了一个良好典范。例如,当用户搜索「斯坦利杯」时,搜索结果通常会显示一个水杯。
然而,当斯坦利杯冰球比赛正在进行时,NavBoost会调整结果以优先显示关于比赛的实时信息。
根据最新发现,文档的点击指标包含了13个月的数据,有一个月的重叠,以便与前一年进行比较。
出乎意料的是,谷歌实际上并没有提供太多个性化的搜索结果。测试结果已经表明,对用户行为进行建模并调整,比评估单个用户的个人偏好更能带来优质的结果。
然而,个人偏好,例如对搜索和视频内容的偏好,仍然包含在个性化结果中。
GWS:搜索的结尾和开端
谷歌网络服务器(GWS)负责呈现搜索结果页面(SERP),包括10个「蓝色链接」,以及广告、图片、Google地图视图、「People also ask」和其他元素。

FreshnessNode、InstantGlue(在24小时内反应,延迟约10分钟)和InstantNavBoost等这些组件可以在页面显示前的最后时刻调整排名。
FreshnessNode可以实时监测用户搜索行为的变化,并根据这些变化调整排名,确保搜索结果与最新的搜索意图匹配。
InstantNavBoost和InstantGlue在最终呈现搜索结果之前,对排名进行最后的调整,例如根据突发新闻和热门话题调整排名等。
因此,要想取得高排名,一个优秀的文档内容还得加上正确的SEO措施。
排名可能会受到多种因素的影响,包括搜索行为的变化、其他文档的出现和实时信息的更新。因此,必须认识到,拥有高质量的内容和做好SEO只是动态排名格局中的一部分。
谷歌的John Mueller强调,排名下降通常并不意味着内容质量不佳,用户行为的变化或其他因素可能会改变结果的表现。
例如,如果用户开始偏好更简短的文本,NavBoost将自动相应地调整排名。然而,Alexandria系统或Ascorer中的IR分数是保持不变的。
这告诉我们,必须在更广泛的意义上理解SEO。如果文档内容与用户搜索意图不一致,仅仅优化标题或内容是无效的。
参考资料:
https://searchengineland.com/how-google-search-ranking-works-445141
https://arxiv.org/abs/2408.11527








 京公网安备 11011402013531号
京公网安备 11011402013531号