8 月 23 日消息,从社交媒体到虚拟现实,个性化图像生成因其在各种应用中的潜力而日益受到关注。传统方法通常需要针对每位用户进行大量调整,从而限制了效率和可扩展性,为此 meta 公司创新提出了“Imagine Yourself” AI 模型。
传统个性化图像生成方法挑战
目前的个性化图像生成方法通常依赖于为每个用户调整模型,这种方法效率低下,而且缺乏通用性。虽然较新的方法试图在不进行调整的情况下实现个性化,但它们往往过度拟合,导致复制粘贴效应。
Imagine Yourself 创新
Imagine Yourself 模型不需要针对特定用户微调,通过单一模式能够满足不同用户的需求。
该模型解决了现有方法的不足之处,如倾向于毫无变化地复制参考图像,从而为更通用、更方便用户的图像生成流程铺平了道路。
Imagine Yourself 在保存身份、视觉质量和及时对齐等关键领域表现出色,大大优于之前的模型。
该模型的主要组成部分包括:
生成合成配对数据以鼓励多样性; 整合了三个文本编码器和一个可训练视觉编码器的完全并行注意力架构; 以及一个从粗到细的多阶段微调过程这些创新技术使该模型能够生成高质量、多样化的图像,同时保持强大的身份保护和文本对齐功能。
Imagine Yourself 使用可训练的 CLIP 补丁编码器提取身份信息,并通过并行交叉注意模块将其与文本提示整合在一起,准确保存身份信息并对复杂的提示做出反应。
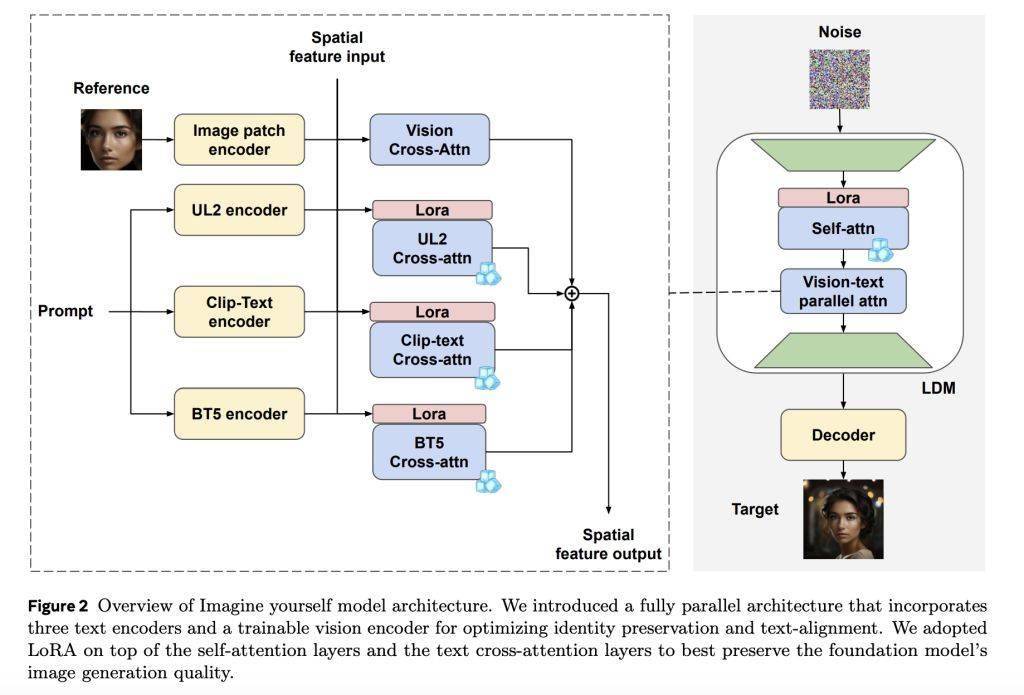
该模型使用低阶适配器(LoRA)仅对架构的特定部分进行微调,从而保持较高的视觉质量。
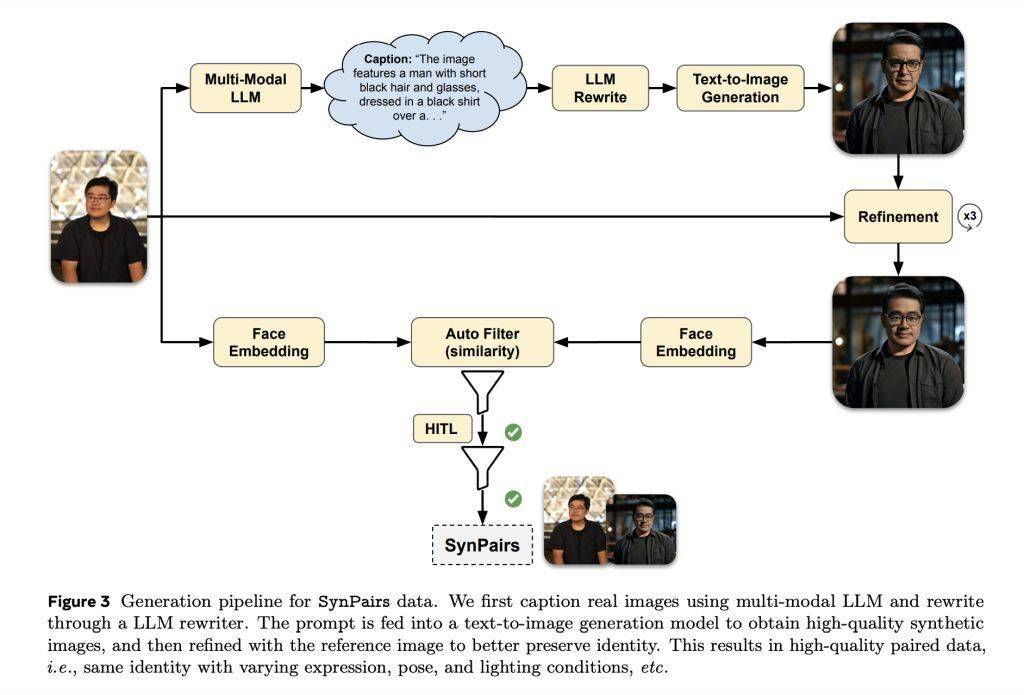
Imagine Yourself 的一个突出功能是生成合成配对(SynPairs)数据。通过创建包含表情、姿势和光照变化的高质量配对数据,该模型可以更有效地学习并产生多样化的输出结果。
值得注意的是,在处理复杂的提示词方面,与最先进的模型相比,它在文本对齐方面实现了 +27.8% 的显著改进。
研究人员使用一组 51 种不同身份和 65 个提示对 Imagine Yourself 进行了定量评估,生成了 3315 幅图像供人类评估。
该模型与最先进的(SOTA)adapter-based 模型和 control-based 模型进行了比对,重点关注视觉吸引力、身份保持和提示对齐等指标。
人工注释根据身份相似性、及时对齐和视觉吸引力对生成的图像进行评分。与 adapter-based 模型相比,Imagine Yourself 在提示对齐方面有了 45.1% 的显著提高,与基于控制的模型相比有了 30.8% 的提高,再次证明了它的优越性。
Imagine Yourself 模型是个性化图像生成领域的一大进步。该模型无需针对特定对象进行调整,并引入了合成配对数据生成和并行注意力架构等创新组件,从而解决了以往方法所面临的关键挑战。
附上参考地址








 京公网安备 11011402013531号
京公网安备 11011402013531号