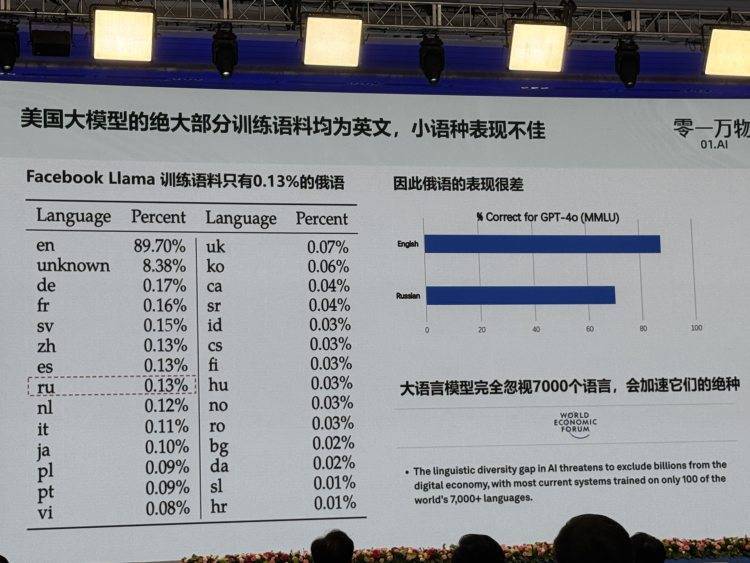
3月29日下午,在2025中关村论坛举行的“未来人工智能先锋论坛”上,创新工场董事长兼零一万物CEO李开复做了《全球视角下的生成式AI展望》主题演讲。他谈道,美国大模型的绝大部分训练语料为英文,小语种表现不佳,“大语言模型完全忽视了7000个语言,会加速它们的绝种”。

李开复举例介绍,Facebook LIama训练语料当中,只有0.13%的俄语。“因此俄罗斯语的使用结果是不好的。如果你去看一下东南亚或者中东、中亚甚至非洲国家,他们几乎更难使用大模型。这样将会加速这些语言的绝种,因为大模型语言是不能使用这些语言的。”
他谈道,康奈尔大学的一份研究显示,美国大模型的价值观基本上就等于欧美的价值观,另外其他地区的价值观和他们是有偏差的。非常有必要让每个国家能够有机会调出自己的模型,用自己的语言、自己的价值观来推动大模型的发展。“零一万物目前正在推出一些小语种的模型,希望能够和相关国家地区合作,让大模型全球发展更加公平。”
在演讲中,李开复还对DeepSeek引发的变革进行了解读。他认为,DeepSeek开源推理模型的思考训练过程,进一步缩小了这一领域和美国的差距;开源模型能力追赶上闭源模型,进一步推进SOTA模型的商品化;DeepSeek高效的工程效率,和OpenAI天量级融资的底层逻辑针锋相对。“同时,DeepSeek Moment大幅加速大模型在中国的全面落地。”
李开复最后谈道,尽管DeepSeek模型很强,但企业落地还需要解决安全部署、应用实践和行业定制这三大方面的问题,通过快速实现私有化安全部署,针对行业场景推进应用,在应用中,让大模型的自我进化能力进一步增强。
李开复还表示,在AI技术井喷的浪潮下,2025年会是AI应用大规模落地的元年。他说,过去两年大模型能力不断提升,在回答问题的能力上已经远超人类;新技术持续突破,数字化AI与真实物理世界将进一步融合。“另外,大模型的推理成本一年下降十倍,AI 2.0普惠点将加速产业渗透。相较云计算,AI 2.0应用层的爆发周期将缩短到两年内。”
记者 杨昕华









 京公网安备 11011402013531号
京公网安备 11011402013531号