《科创板日报》3月28日讯(编辑 宋子乔)随着OpenAI的图像生成功能完成重大升级,新的问题出现了。
OpenAI创始人Sam Altman表示:ChatGPT的文生图应用需求过高,我们的GPU“冒烟了”(melting,原为融化之意),在努力提高效率的同时,将暂时对ChatGPT生成图片的功能引入一些速率限制。
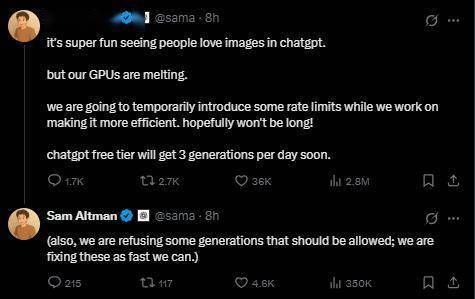
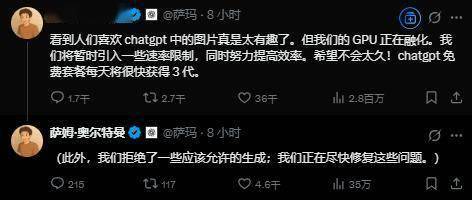
这意味着,OpenAI将对ChatGPT的图像生成功能实施临时限速,降低单位时间内的请求处理量,缓解GPU过载压力,并优先保障文本生成、对话等核心功能的稳定性,或许将暂时放缓图像生成的技术优化节奏。
此前3月26日,OpenAI推出基于GPT-4o模型的图像生成功能——Images in ChatGPT,用户可在ChatGPT及Sora平台直接通过自然语言指令生成、编辑图像,支持多轮迭代优化。这标志着ChatGPT正式将文本、图像、代码等多模态能力深度整合,实现从单一语言模型向全模态智能体的跨越。
该功能上线后,以“动动嘴就能P图”的便利迅速火爆,互联网平台上涌入大量由个人照片、知名梗图转变而来的“吉卜力”卡通风格图片。连Altman也感叹起该功能带来的泼天流量:“自己过去十年埋头苦干做AI,试图帮助实现超级智能来治愈癌症之类的事情。前7.5年几乎无人问津,接下来的两年半,做什么都会引来所有人的厌恶。然后某天醒来收到几百条消息,人们告诉你被画成了吉卜力风格的美少年。”
Sam Altman在社交平台上的新头像,生成自Images in ChatGPT

生成自Images in ChatGPT

生成自Images in ChatGPT
与此同时,由于图像生成功能的受欢迎程度远超预期,OpenAI原本计划本周向所有用户推送这项功能,但现在“被迫”推迟了向免费用户开放新功能的时间。
与作为扩散模型运行的DALL•E根本区别是,GPT-4o图像生成是原生嵌入在ChatGPT中的自回归模型。OpenAI根据在线图像和文本的联合分发来训练模型,使得模型可以学习图像与语言的关系,使其生成有用、一致且具备上下文感知的图像。
GPU就像一群超级快的“画师”,能同时处理大量计算任务,生成图片(如DALL•E、Stable Diffusion)需要AI逐像素计算,每一步都要处理海量数据。而让AI生成更精确、更高清的图像依赖于GPU的大规模并行计算。OpenAI提到,因为这个模型会创建更详细的图片,所以图像需要更长的渲染时间,通常会达到一分钟。
如此一来,文生图功能的用户越多,需要的GPU算力成倍增长。
解决方式主要有两种,更强的GPU或更高效的AI模型,前者走“力大砖飞”路线,后者寄希望于算法的优化,即通过改进AI算法让同样的GPU能处理更多任务(比如用更小的模型或压缩技术)。
作为AI领域的头部玩家,OpenAI背后的GPU储备自然是业内顶尖水准。根据技术咨询公司Omdia的分析,微软作为OpenAI的主要投资者,在2024年购买了约48.5万块英伟达的Hopper芯片,是其主要竞争对手meta的两倍,这使其成为英伟达GPU的最大买家。OpenAI的大模型正是用微软的Azure云基础设施进行训练。
可以说,OpenAI因新功能面临的问题,折射了AI多模态技术发展中的资源与需求平衡难题,一方面,AI应用对GPU等算力资源的需求依然庞大,另一方面,行业继续呼唤技术迭代,以求高效利用现有资源。
(科创板日报 宋子乔)








 京公网安备 11011402013531号
京公网安备 11011402013531号