AI重构化学工业的“复杂方程式”
化学工业,作为现代工业的基石,从未缺席每一次技术革新带来的潜能释放。
当前,大模型技术的发展方兴未艾。化工行业正在积极从中寻找助力,但常规大模型在垂直领域表现不佳,领域知识的缺乏、机理推导能力差等,导致化工行业拥抱大模型的尝试,屡屡受阻。如何将人工智能的“未来感”转化为化工产业的“生产力”,如何将AI发展的两大方向:大模型与AI for Science高效结合成为当务之急。
2025年3月,作为人工智能在化工行业应用的领跑者,凭借多年行业积淀,再次以破局者之姿交出答卷——「国工化工大模型」正式发布。「国工化工大模型」完美融合了大模型技术与多年沉淀的AI化学能力,让化学反应从“实验室盲盒”进阶为“可计算的科学”,积极推动化学研究从经验科学、计算科学向AI科学的转变,用AI技术为化学工业书写“化繁为简”的新范式。
l「国工化工大模型」的核心能力:从“问答助手”到“机理专家”
「国工化工大模型」改变了大模型的“文科生”设定,朝着“理科生”深度进化。大模型技术与AI for Science领域的垂直能力深度融合,针对具体问题进行识别后,联动调用「合成推演」、「催化剂设计」、「分子动力学及计算化学描述符构效关系计算」、「构效关系计算」、「产物预测」、「量热预测」、「实验/工艺优化」、「高分子配方与性能预测」、「谱图逆分析」等15种垂直领域模型进行协同分析,真正实现大模型在化工场景的“深度思考”。
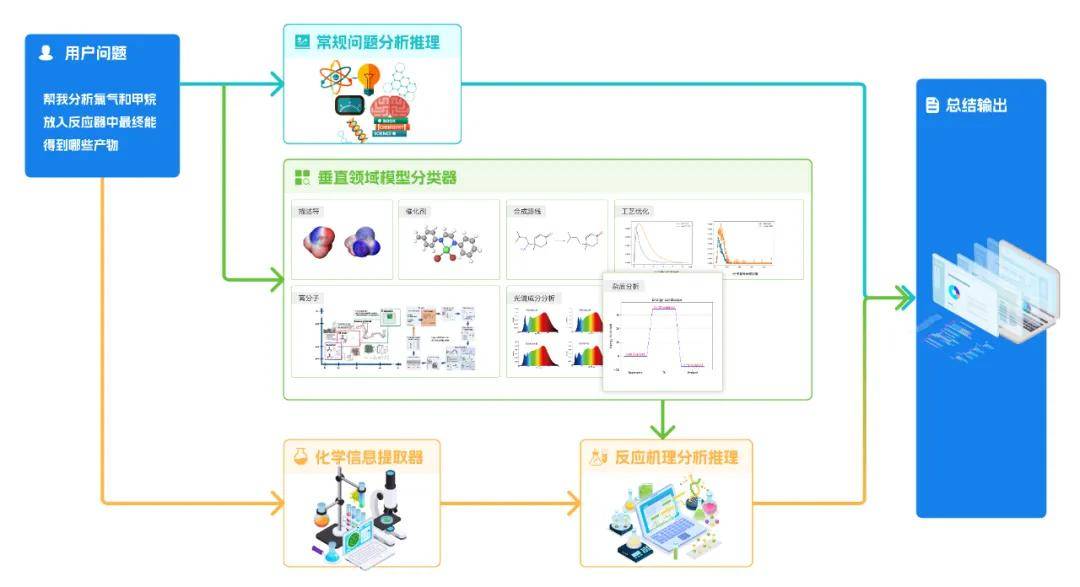
图:大模型多路分析
合成推演:利用合成规则预测反应路线图,从目标产物回溯到起始原料,推荐有机化合物的逆向合成路线,可推荐出文献中尚无报道且具有潜力的合成路线,辅助探索最优合成方案。催化剂设计:针对特定反应类型的催化剂,通过输入催化剂结构,对催化性能进行预测,为催化剂的实验开发指明清晰的方向;反之,输入所期望的催化性能以及相关的实验信息,能够为催化剂结构的修饰、改进、设计提供重要的依据和思路,从而得到最可能对应此催化性能的催化剂结构。分子动力学及计算化学描述符构效关系计算:「国工化工大模型」可根据输入的实验数据,进行各类分子动力学描述符的计算,并能够建立描述符与宏观性质的构效关系,自动生成“结构-性能”的预测模型。反应预测:「国工化工大模型」针对输入的有机反应的反应物和可能的反应条件,可完成从反应物到过渡态、中间体、以及最终反应产物的模拟计算,并且可以通过对多种反应模式的探索,构建起复杂的有机反应网络,预测反应可能产生的副产物、杂质等。量热预测:针对包含反应过程量热问题,输入反应物和反应条件后,「国工化工大模型」可以根据反应本身和不同的反应条件来给出反应装置中随时间的量热变化,对物理过程模拟准确,但对含有化学过程的量热很难预测。实验/工艺优化:针对组合因素和多指标的优化任务进行分析,快速探索最佳指标对应参数配置,给出实验条件、工艺参数,减少试验次数,提高研发效率。高分子配方与性能预测:通过机器学习和深度学习技术,对大量材料数据进行分析和挖掘,寻找新的材料组合或优化材料配方、预测高分子材料的物理、化学和机械性能,探索新的配方空间,发现传统方法难以发现的高分子材料,推动材料科学的创新。谱图逆分析: 谱图逆分析是一项利用海量分子光谱数据构建强大表征模型的技术。不仅能实现对相似分子的精准计算与匹配,还能深入解析复杂混合物,准确预测其组分构成,并进一步推断混合物的关键性质。通过对光谱数据的深度挖掘和智能分析,谱图逆分析为化学、材料科学等领域的研究提供了强有力的工具,极大地加速了新材料的研发和复杂混合物的解析过程。l「国工化工大模型」的行业优势:从“聊天机器人”到“科研分析师”
化工知识强化:「国工化工大模型」已完成百万篇专业化学文献的知识库构建,并结合行业最领先的数据集完成训练,天然具备化工行业知识属性,在行业术语、专业概念、学科理论等方面的理解和分析能力显著提升,回答时生成的文本具备更强逻辑性、准确性,更符合行业规范。
同时,在复杂化工问题的推理和分析上,「国工化工大模型」能够结合行业前沿知识,向用户提供更新颖的解决方案、更具洞察力的建议和可行性研究方向。
问题识别与能力联想:针对用户输入的问题,「国工化工大模型」将自动识别其中的化合物名称、化学式、配方组分与比例等关键数据,通过语义分析自动进行问题联想,并罗列对用户有帮助的分析选项。
科研模态扩展:「国工化工大模型」的分析回答将不在局限于简单文本模态。针对不同的机理问题的分析回答时,「国工化工大模型」多种科研模态的图表形态进行结果展示,包括:「合成路线图」、「分子3D结构」、「反应势能面图」、「过渡态回放动画」、「能量变化曲线」、「反应演变动画」、「配方表」、「相关度分析图」等50种不同科研模态进行结果展示。

图:多模态科研分析师
l「国工化工大模型」的私域安全:从“数据小偷”到“私有智囊”
「国工化工大模型」定位于为化工细分行业的提供定制训练、企业内私有化部署。意在解决公共大模型在企业侧数据私有化训练、企业内部系统集成等问题,让化工企业不再是大模型技术的“用户”,真正成为大模型的“训练师”和“驾驭者”,拥有企业自身可掌控的大模型平台。
数据安全性:以私有化的方式运行在企业内部,不再将研发、生产、运营等保密数据上传到公有云环境,有效保护企业的数据和商业秘密,降低数据泄露风险。可集成性:企业通过无缝集成企业内信息化系统,自动整合企业内部数据资源进行训练自有大模型的训练,实现数据库问答,给出智能化决策意见。可驾驭性:企业可利用不断产生的新数据对私有大模型进行自主训练和优化,模型能力将更加符合企业自身业务特点、精准满足企业自身需求,打造企业可驾驭的专属模型。未来,化学工业的“基石”地位不会动摇。当化学工业与量子计算、AI深度融合,其内涵也正在发生根本性转变,化学工业将从“大规模制造”转向“精准创造”、从“经验驱动”转向“数据智能”。
致力于陪伴国内化工企业走出实验的试错沼泽,开拓化工行业本该拥有的——“数据”与“算法”的智能沃土。
l问答示例:
计算化学描述符 humo 和lumo,与 OLED 行业中的外部量子效率(EQE)有什么关系?










 京公网安备 11011402013531号
京公网安备 11011402013531号