全能创新架构:Qwen团队提出了一种全新的Thinker-Talker架构,这是一种端到端的多模态模型,旨在支持文本/图像/音频/视频的跨模态理解,同时以流式方式生成文本和自然语音响应。Qwen提出了一种新的位置编码技术,称为TMRoPE(Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步。
实时音视频交互:架构旨在支持完全实时交互,支持分块输入和即时输出。
自然流畅的语音生成:在语音生成的自然性和稳定性方面超越了许多现有的流式和非流式替代方案。
全模态性能优势:在同等规模的单模态模型进行基准测试时,表现出卓越的性能。Qwen2.5-Omni在音频能力上优于类似大小的Qwen2-Audio,并与Qwen2.5-VL-7B保持同等水平。
卓越的端到端语音指令跟随能力:Qwen2.5-Omni在端到端语音指令跟随方面表现出与文本输入处理相媲美的效果,在MMLU通用知识理解和GSM8K数学推理等基准测试中表现优异。
Qwen2.5-Omni采用Thinker-Talker双核架构。Thinker模块如同大脑,负责处理文本、音频、视频等多模态输入,生成高层语义表征及对应文本内容;Talker 模块则类似发声器官,以流式方式接收 Thinker实时输出的语义表征与文本,流畅合成离散语音单元。Thinker 基于 Transformer 解码器架构,融合音频/图像编码器进行特征提取;Talker则采用双轨自回归 Transformer 解码器设计,在训练和推理过程中直接接收来自 Thinker 的高维表征,并共享全部历史上下文信息,形成端到端的统一模型架构。

模型架构图
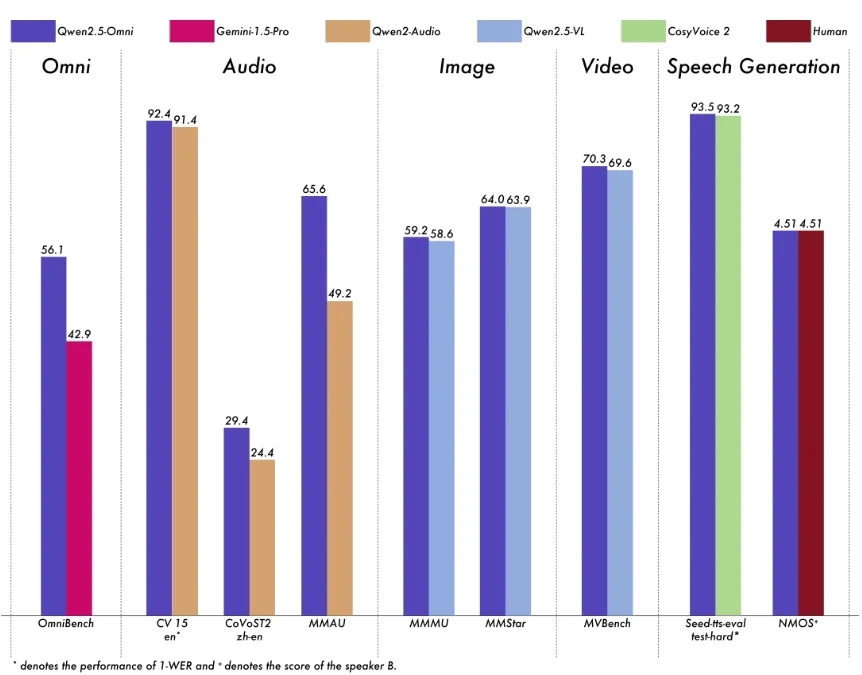
模型性能方面,Qwen2.5-Omni在包括图像,音频,音视频等各种模态下的表现都优于类似大小的单模态模型以及封闭源模型,例如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro。
在多模态任务OmniBench,Qwen2.5-Omni达到了SOTA的表现。此外,在单模态任务中,Qwen2.5-Omni在多个领域中表现优异,包括语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然听感)。
该模型现已在 Hugging Face、ModelScope、DashScope 和 GitHub上开源开放。









 京公网安备 11011402013531号
京公网安备 11011402013531号