机器之心报道
作者:佳琳、佳琪
谷歌有史以来最智能的 AI 模型。深夜悄悄搞事情的不只 OpenAI,抢在 OpenAI 开直播之前,谷歌上线了最强大的推理模型 Gemini 2.5 Pro。
谷歌 CEO「劈柴哥」甚至用:「这是谷歌有史以来最智能的 AI 模型。」为它站台。
不过,从 Gemini 2.5 Pro 的成绩单来看,它可能确实担得起「有史以来最强」的名号。
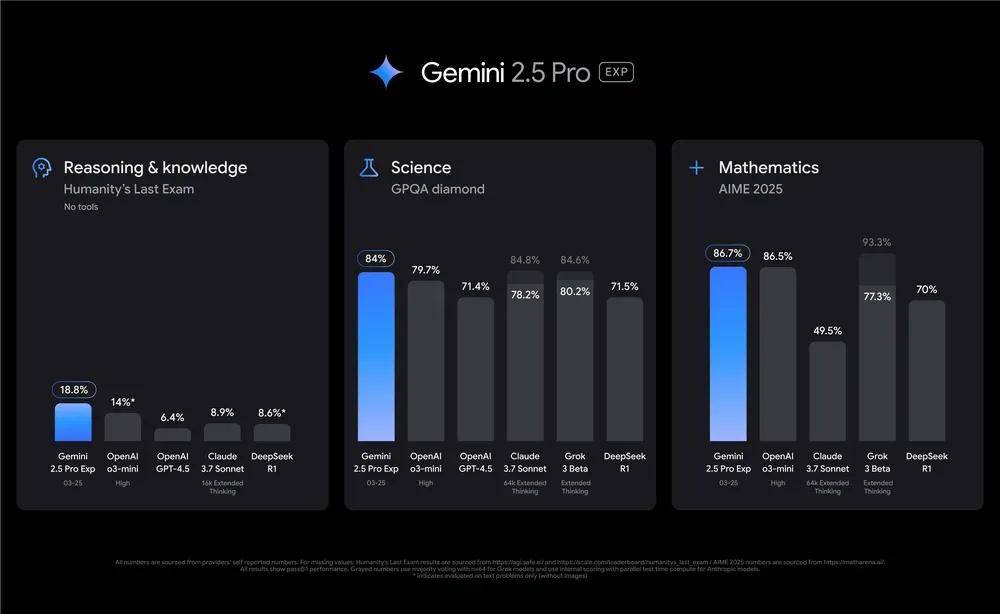
首先来看推理能力,在被视为人类给 AI 的终极考验的 Humanity's Last Exam 基准测试中,不额外调用工具的 Gemini 2.5 Pro 取得了 18.8% 的准确率,超过了能秒解图论难题的 OpenAI o3-mini(high)。
和推理能力强相关的科学和数学能力,在 GPQA、AIME 2025 等主流基础测试中,Gemini 2.5 Pro 也是遥遥领先,具体成绩如下:
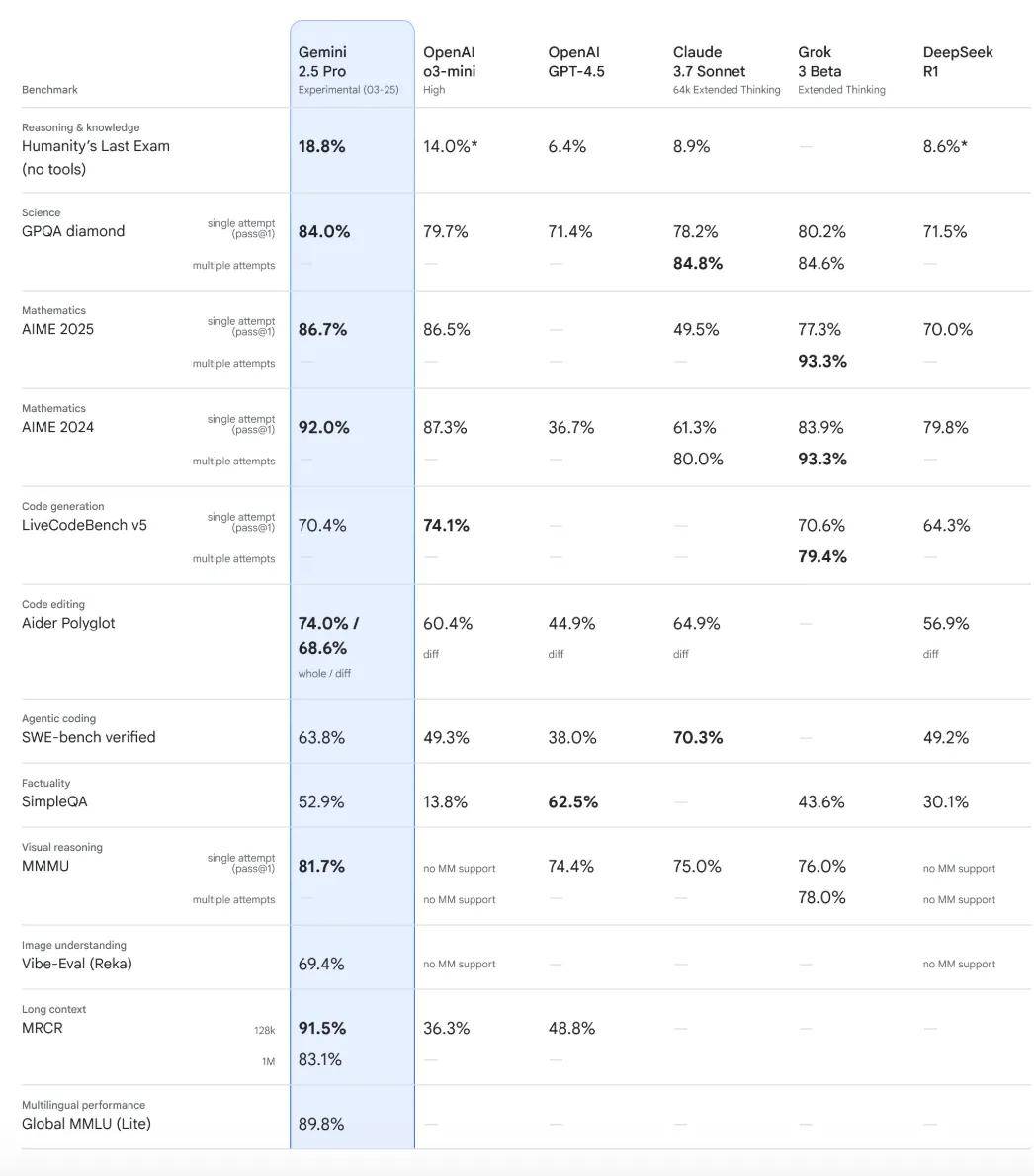
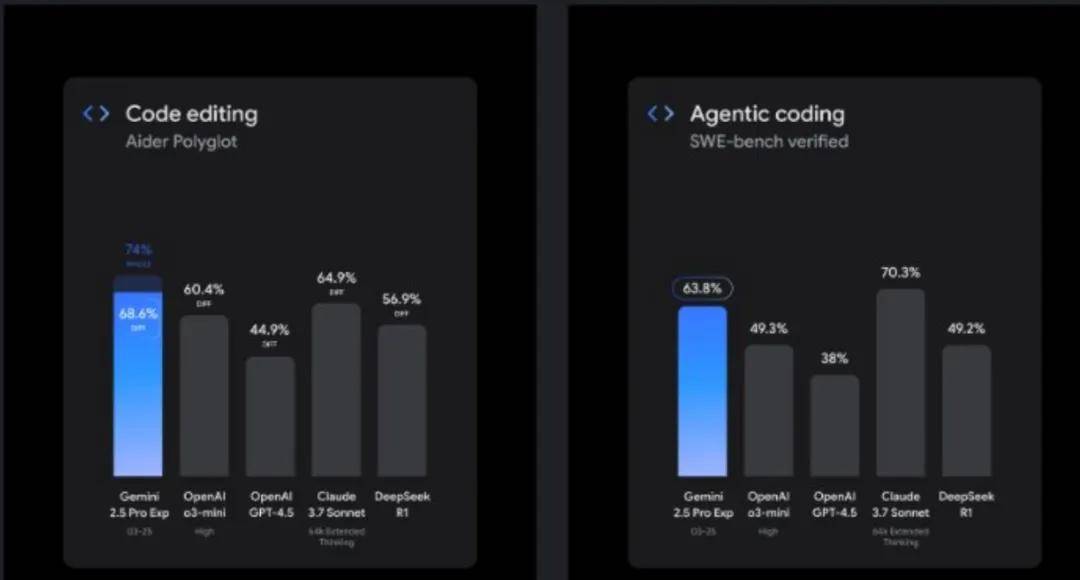
在编程能力方面,Gemini 2.5 Pro 相比 2.0 实现了质的飞跃,未来还将不断增强。
其中,SWE-bench 衡量的是编码能力,Aider Polyglot 衡量的是模型的代码编辑水平。除了在 Agentic coding 方面逊色于 Claude 3.7 Sonnet,Gemini 2.5 Pro 均斩获第一:
谷歌称 Gemini 2.5 Pro 比较擅长在创建视觉效果精美的网页应用和操作智能体。在官方放出的 demo 中,只需一行提示词,Gemini 2.5 Pro 就开动脑筋,逐步推理出了这个类似「flappy bird」的小游戏的全部代码,并且直接可玩:
再来是对话能力,在大模型竞技场 Chatbot Arena 的榜单上,Gemini 2.5 Pro 以绝对优势强势登顶,创下了前所未有的最大分数飞跃,比 Grok - 3 和 GPT - 4.5 高接近 40 分:
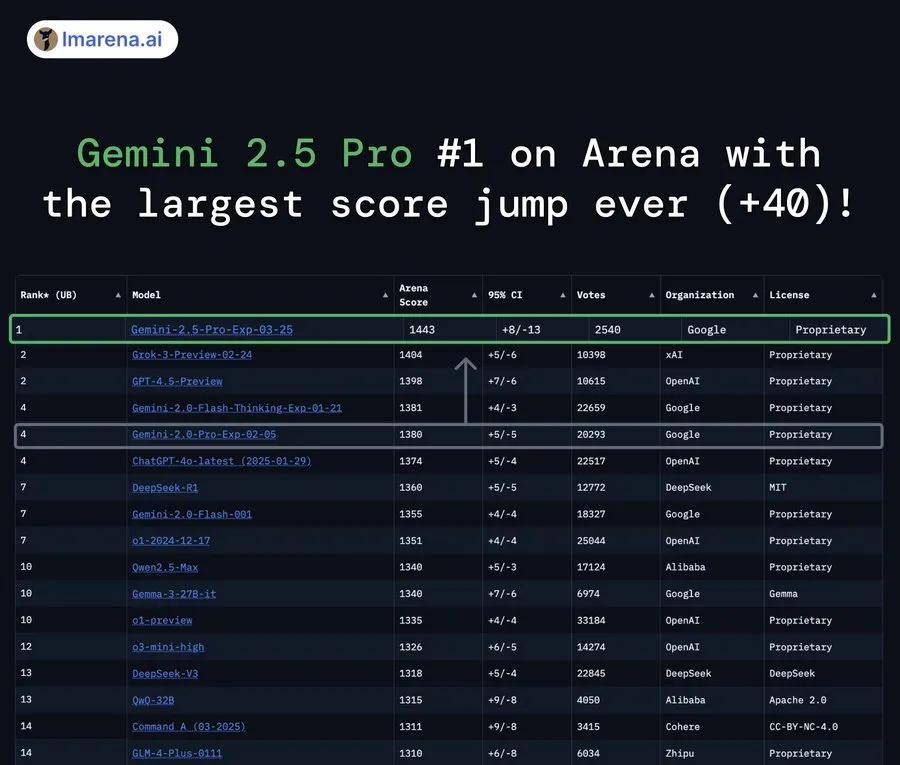
从第二名以下的成绩,不难发现,Chatbot Arena 的前几名分差往往很小,几乎不超过 10 分。Grok-3 上个月刚登顶,第一的位置还没坐几个月,就被 Gemini 2.5 Pro 甩开了。
除了对话能力,Gemini 2.5 Pro 在 Chatbot Arena 的复杂指令、编程、数学、创意写作、指令跟随的榜单上也是全面领先,堪称「六边形战士」。
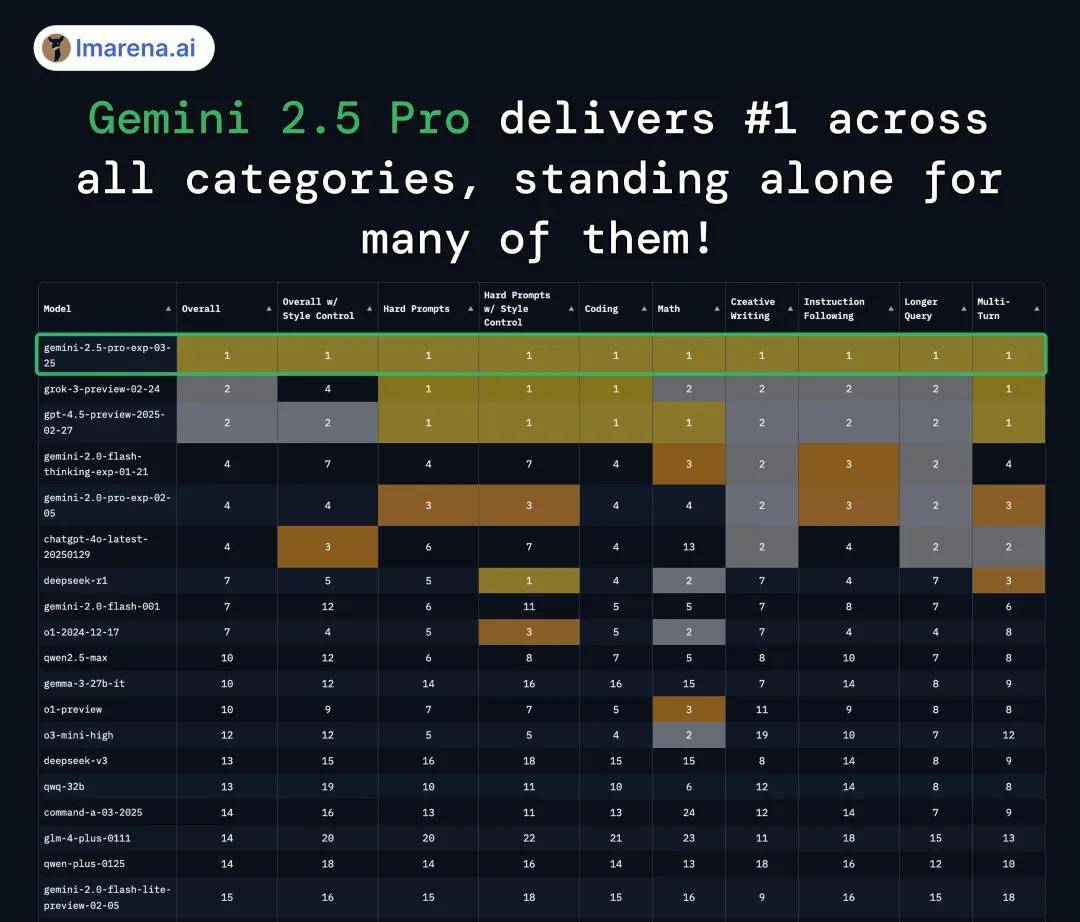
和其他家推理模型不同的是,Gemini 2.5 延续了 Gemini 系列模型的核心优势 —— 原生多模态能力和长上下文窗口。Gemini 2.5 Pro 版本拥有 100 万 token 的上下文窗口(没有缩减,即将提升至 200 万 token),支持文本、音频、图像、视频及完整代码库输入。
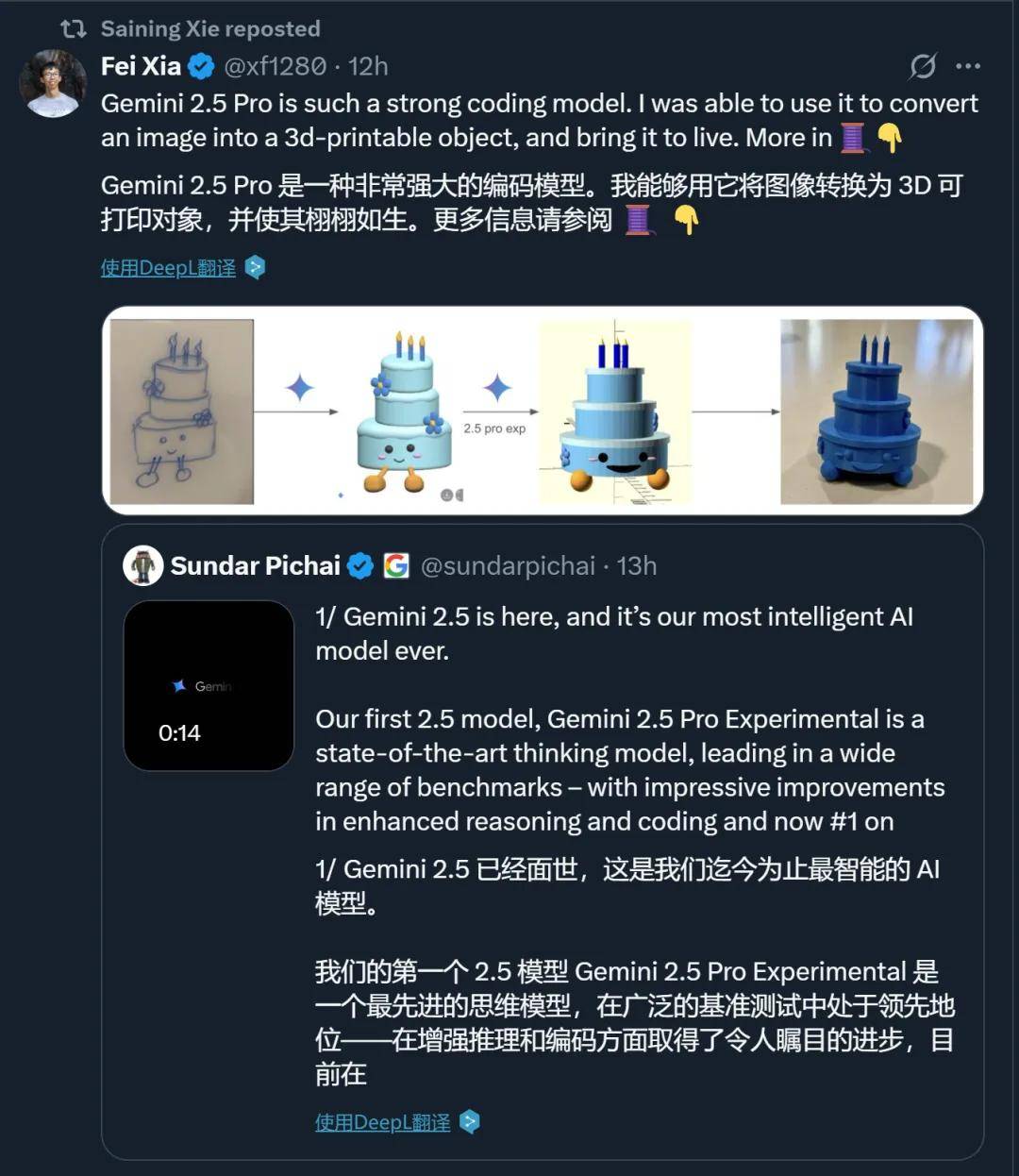
支持把图像转化为可以 3D 打印的格式。
从 Vision Arena 榜单来看,Gemini 2.5 Pro 不止支持原生多模态,能力更是一骑绝尘。
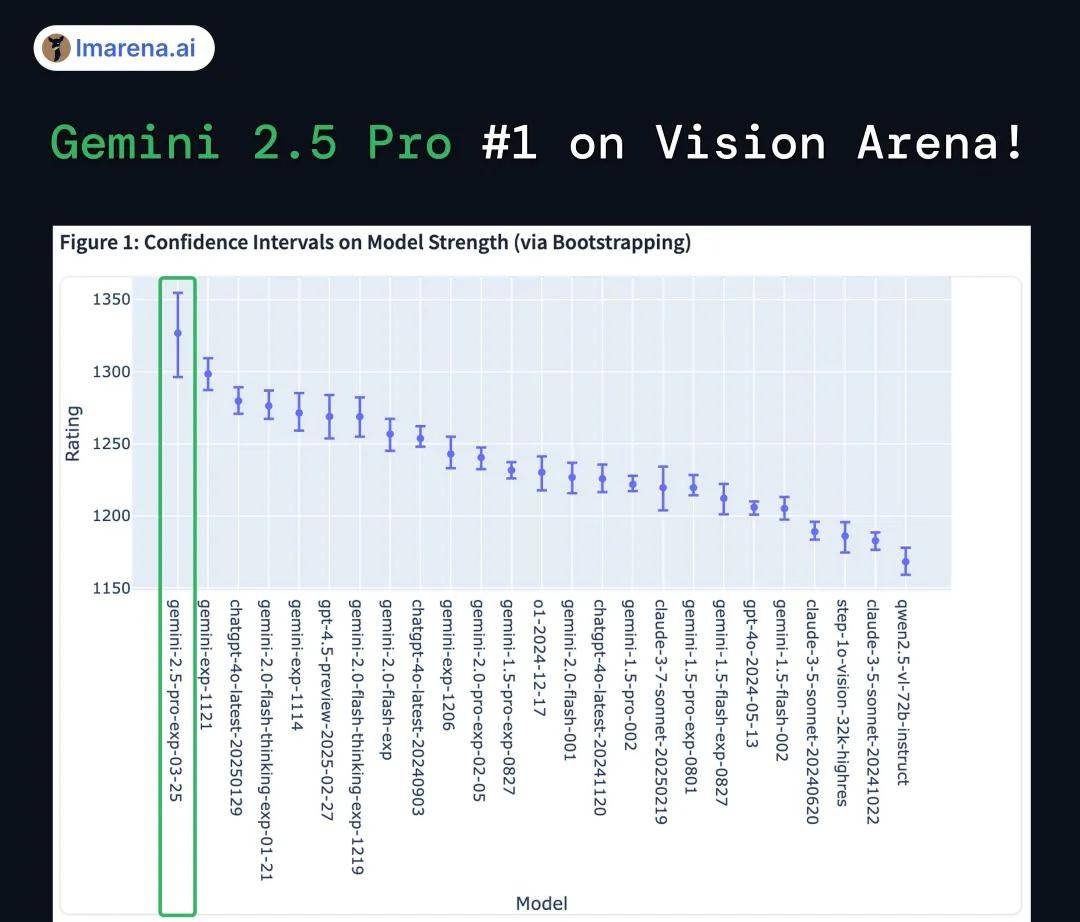
防盗水印一秒蒸发、证件照 10 秒抠图,以下是第四名 Gemini-2.0-flash-thinking 「一句话 P 图」的效果。如今,在新的第一名面前,更是被远远超越。

作为一个会「思考」的模型,Gemini 2.5 Pro 专为复杂任务设计,更够能智能地分析信息、理解问题的背景和情境以及做出明智的决策。
不过,谷歌并未公开技术报告,我们只能从谷歌放出的博客中得知,他们的技术突破在于强化学习、思维链提示和后训练。

现在登录 Google AI Studio,普通用户和企业就能体验到 Gemini 2.5 Pro。如果是高贵的 Gemini Advanced 用户,在桌面和移动设备下来菜单,就能直接使用了。未来几周内,Gemini 2.5 Pro 也将登陆 Vertex AI 平台。
其实前几天,Chatbot Arena 上就有一个代号「Nebula」的神秘模型在 LMSYS Arena 屠榜,击败了包括 o1、o3-mini 和 Claude 3.7 Thinking 在内的众多对手。
不知道是不是谷歌偷师了 OpenAI 的营销技巧,正式公布 Gemini 2.5 Pro 之前,劈柴哥也神秘兮兮地发了一条推特:
不过现在再模仿「strawberry」可能有点晚了,遇到大佬无缘无故开始在社交平台上发「诗和远方」,都可以召唤 Grok 来甄别。
一手实测
看完了成绩单,Gemini 2.5 Pro 的实际水平是否也如此出色呢?
实测见真章,机器之心先对它的推理、数学、科学和编程四个方面展开了一番测评。
推理
根据之前测试推理模型的经验,我们总结了几道很难答对的逻辑题来考验 Gemini 2.5 Pro。
提示词:两个人同时来到了河边,都想过河,但只有一条小船,而且小船只能载一个人。请问:他们能否都过河?
仅用了 11 秒,Gemini 2.5 Pro 成功识破了逻辑陷阱:「两个人同时来到了河边」不一定都在同岸,如果是对岸就成立了。
提示词:校长室的玻璃被人用足球砸坏了,有四个人被校长怀疑,四人依次陈述自己理由,其中有一个人说法很可疑,他就是肇事者。甲:我没有砸玻璃。乙:甲说的是对的。丙:丁在说谎。丁:我没有玩足球。请问肇事者是谁?
这回 Gemini 2.5 Pro 的思考时间长了一点,但是由于它忽略了在现实中丙的发言顺序在丁之前,所以丙说的一定为假,因此正确答案是丙,Gemini 2.5 Pro 答错了。
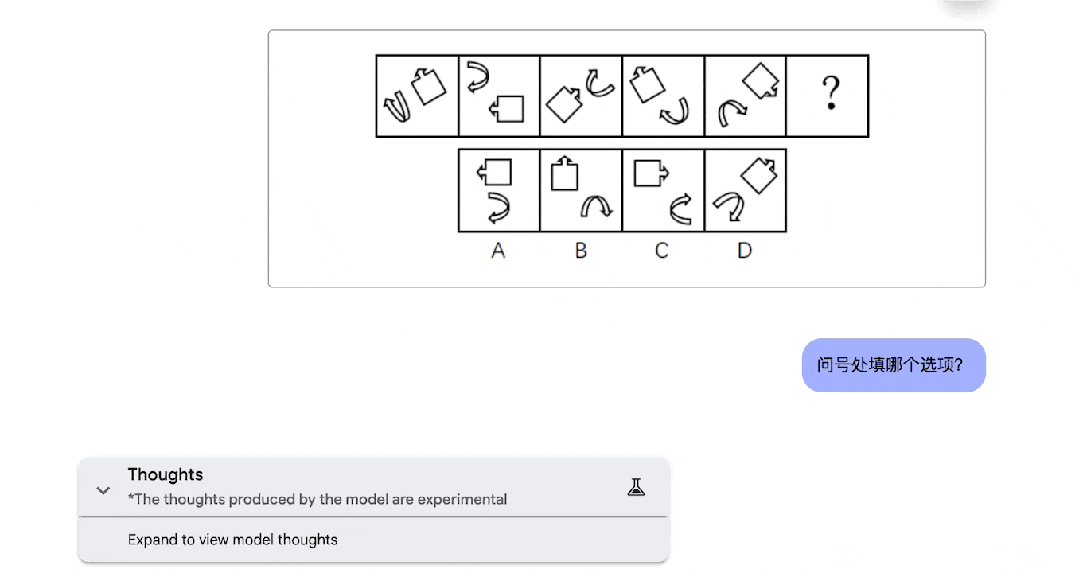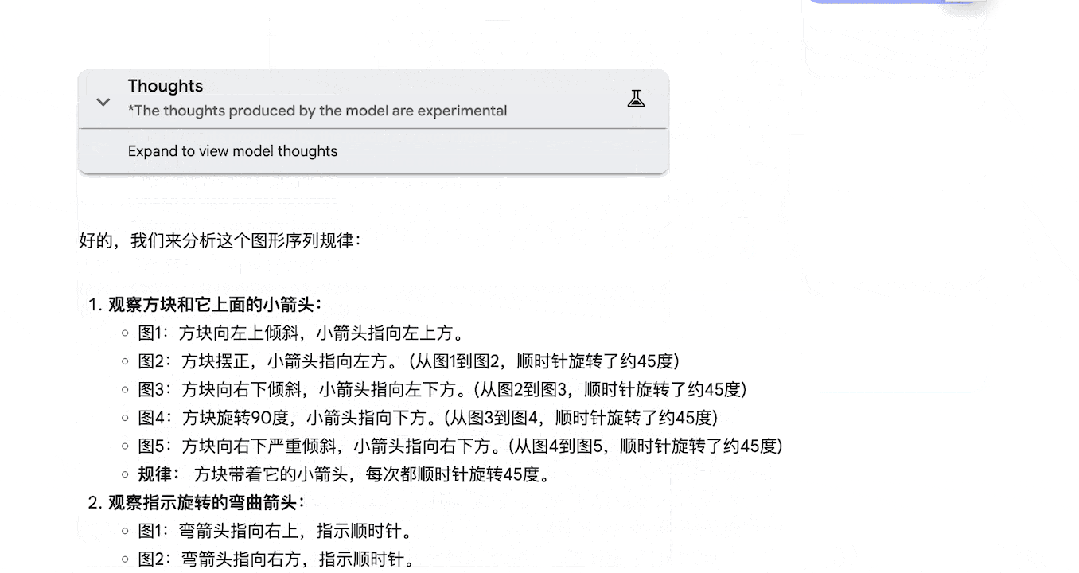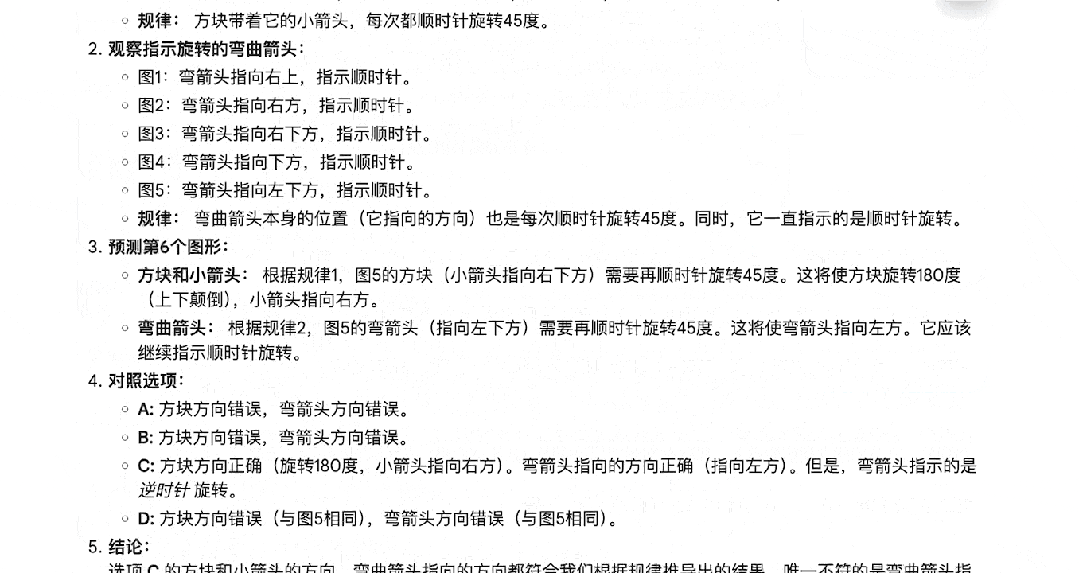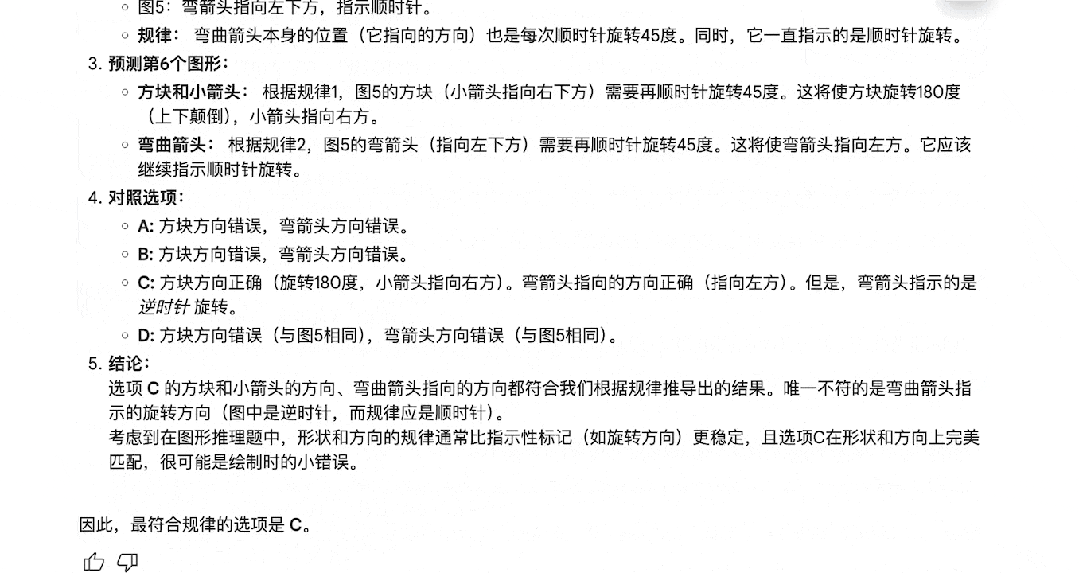
其他推理模型很难搞定的图推题,Gemini 2.5 Pro 也能一次答对。
数学
要检验推理模型的有多聪明,数学题是最好的「智商测试」,我们先来一道今年的考研数学真题:

过程和结果,Gemini 2.5 Pro 都轻松拿下。
再上点强度,来一道 IMO 2024 年的真题:

一阵强劲的思考过后,Gemini 2.5 Pro 给出的答案也是正确的。

拼多多砍一刀背后蕴含的「极限」思想,也没难倒它。
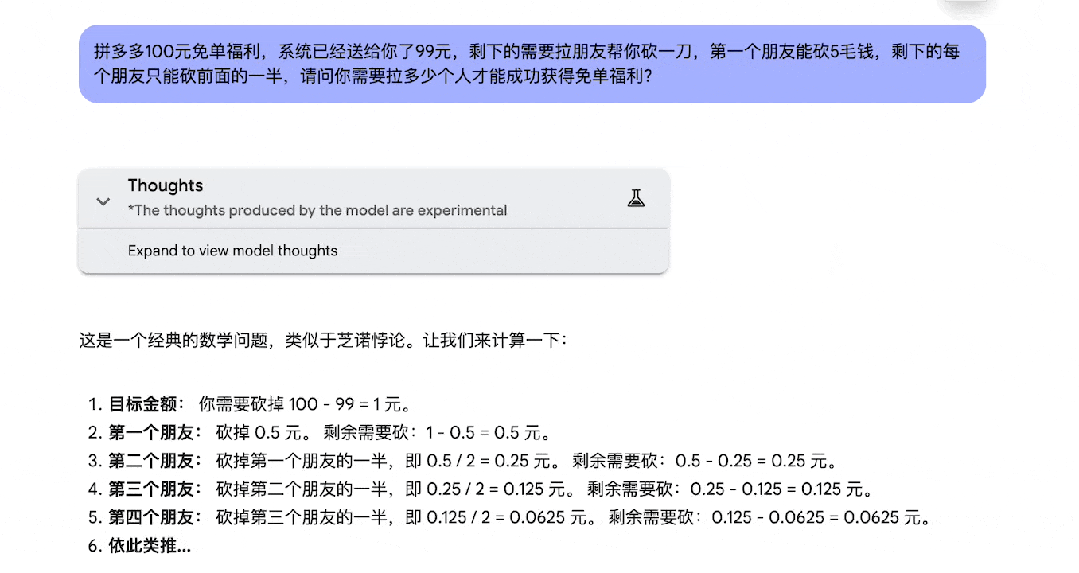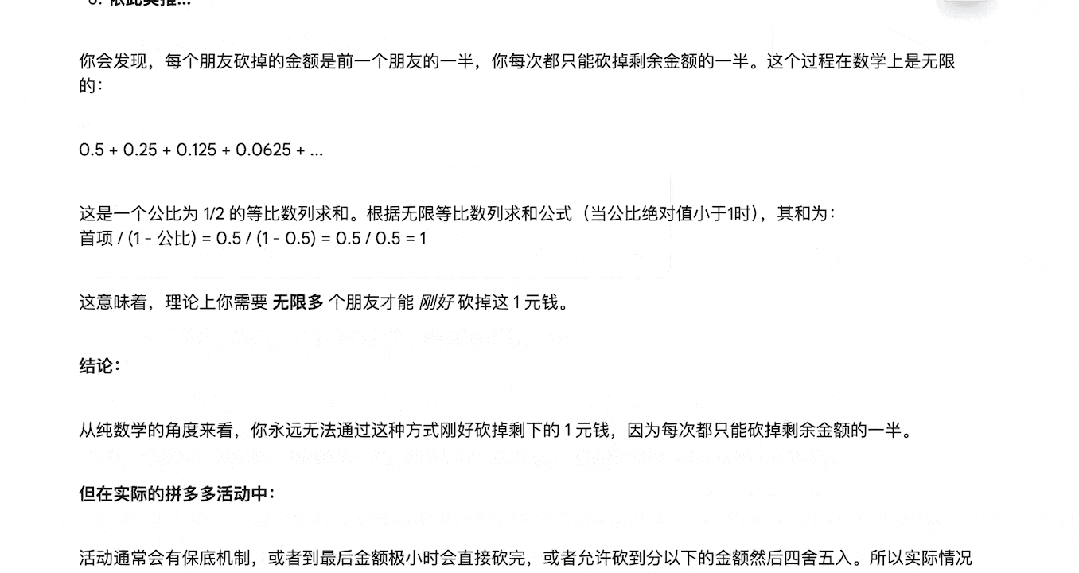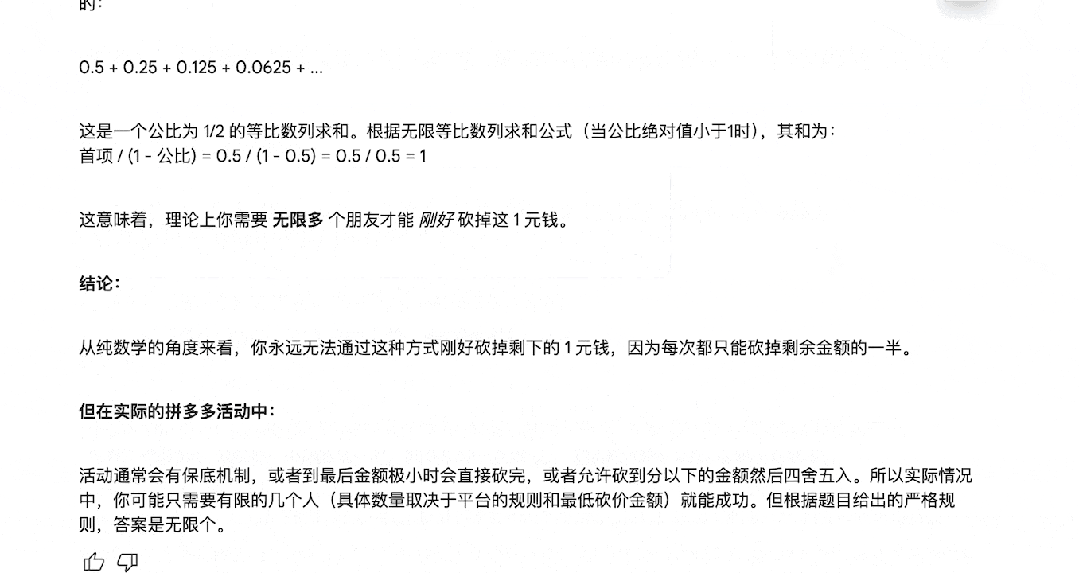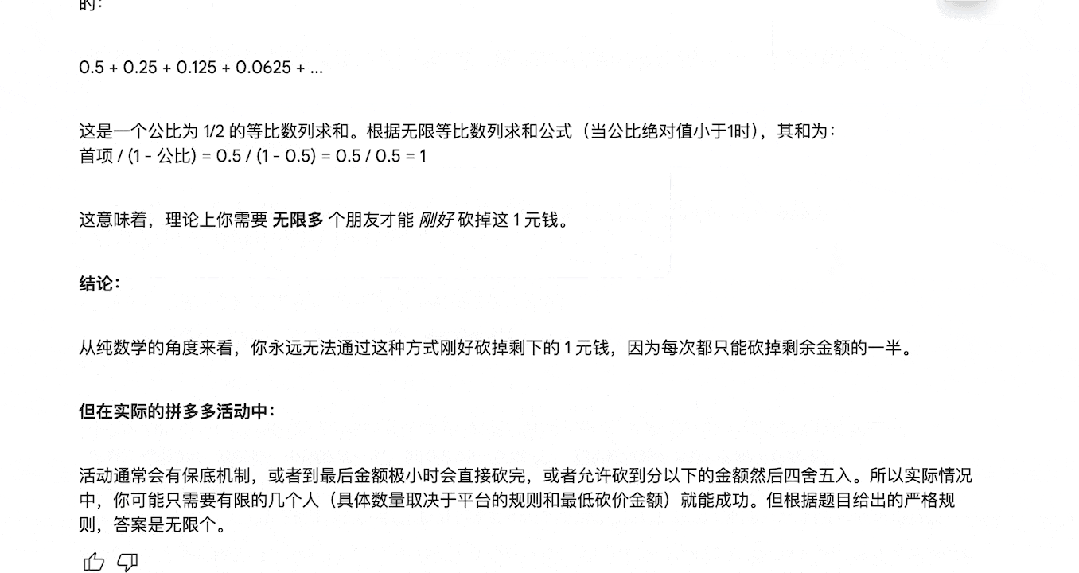
科学
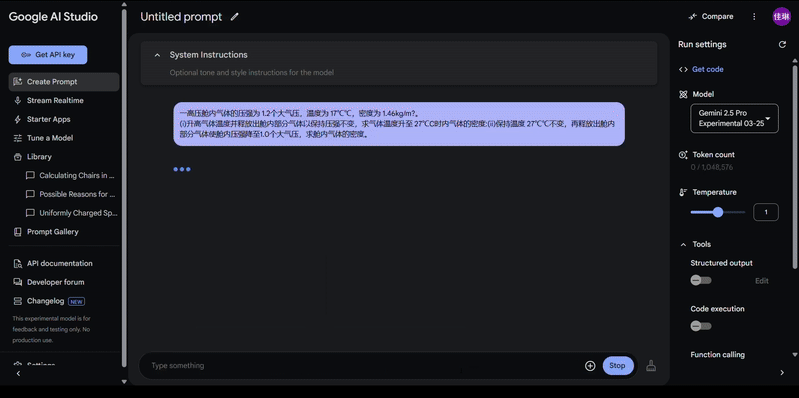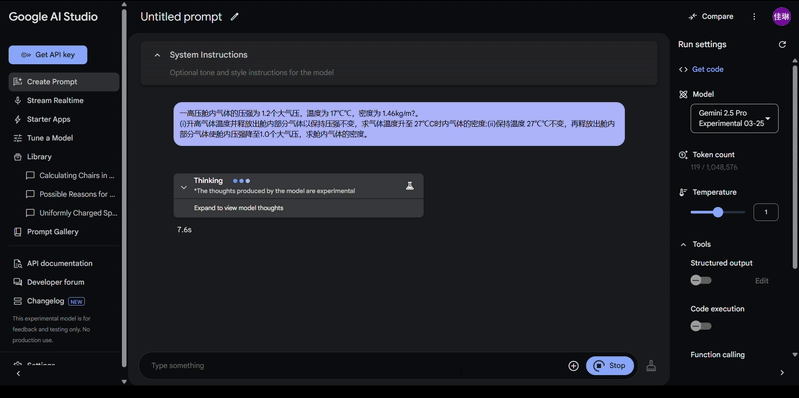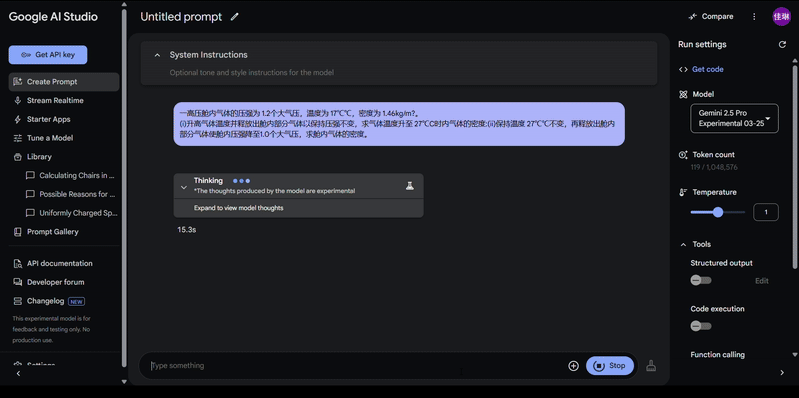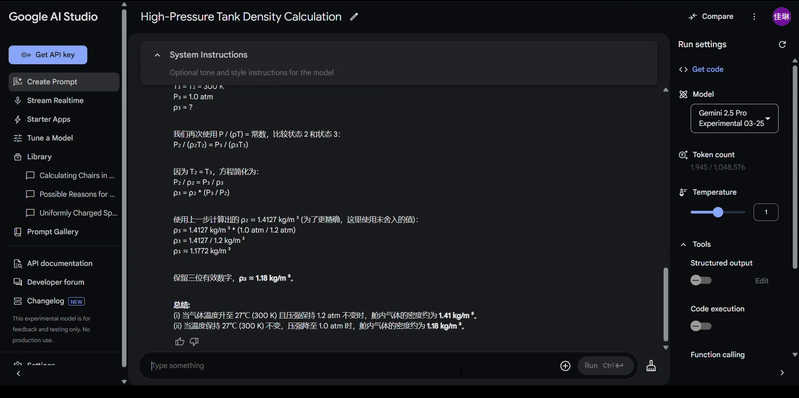
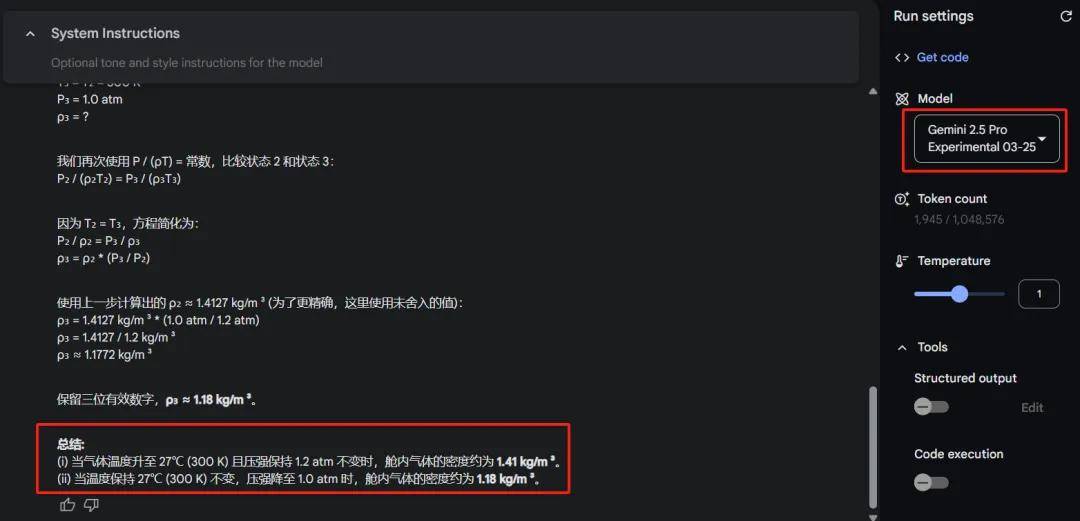
来一道 2023 年理综物理真题 ——

Gemini 2.5 Pro 稍加思考,轻松回答出正确答案。
Gemini 2.0 Flash 则遗憾离场。

编程
我们先让 Gemini 2.5 Pro 生成一个贪吃蛇游戏。
「创建一个经典的贪吃蛇小游戏,游戏界面为 400 × 400 像素的画布。蛇由若干个 10 × 10 像素的方块组成,初始长度为 3 个方块,初始位置在画布中心。蛇可以向上、向下、向左、向右移动,使用键盘的方向键控制蛇的移动方向。游戏中随机生成一个 10 × 10 像素的红色食物,当蛇吃到食物时,长度增加 1 个方块,分数增加 10 分,并重新生成食物。如果蛇撞到画布边界或自身,则游戏结束,弹出一个对话框显示最终得分,并提供重新开始的选项。游戏开始时,蛇以中等速度移动,随着时间的推移逐渐加快速度,增加游戏的挑战性。」Gemini 2.5 Pro 表示毫无压力,还贴心附上操作指南。
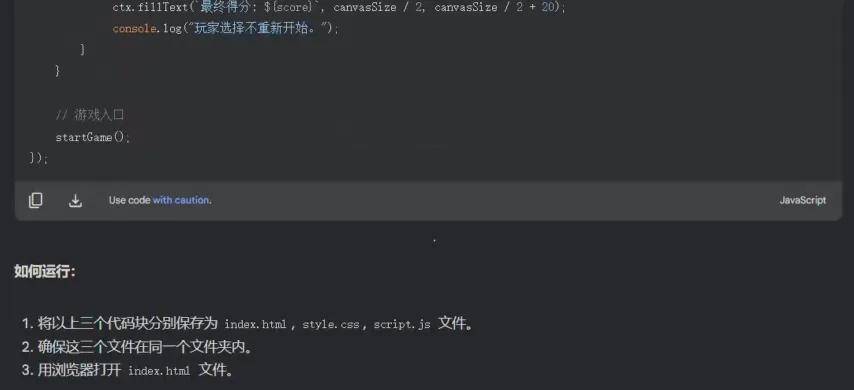

然后上点难度「增加不可移动的障碍物(地图边缘 + 随机 3 个方块)」。

再来添加一点 buff「添加特殊道具(吃到的效果任选 2 种):加速 / 减速道具,临时穿墙(10 秒),清除所有障碍物」。

现在把主场交给 Gemini 2.5 Pro,看看它有什么奇妙想法。
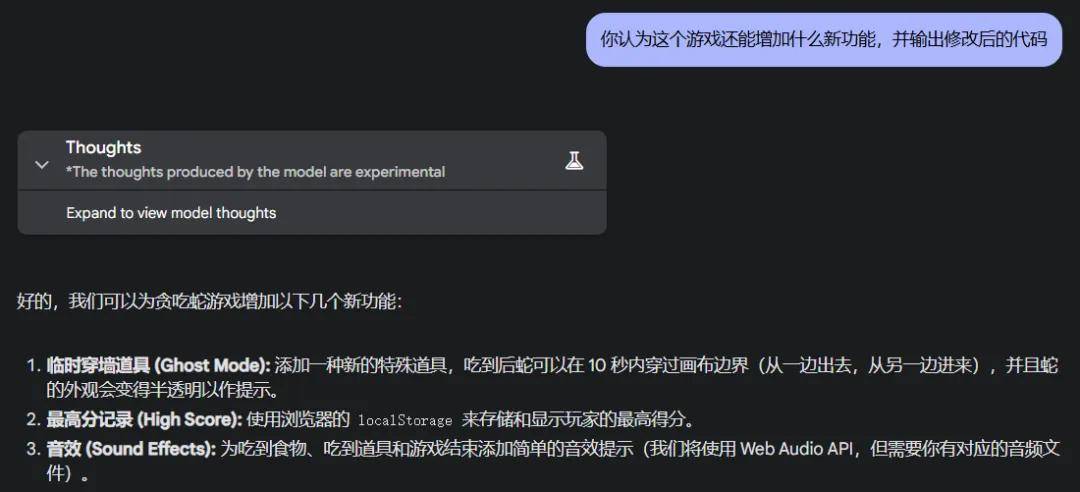
还是非常丝滑~
以上操作 Gemini 2.5 Pro 都是一次成功,没有报错。
最后,我们来检查一下 Gemini 2.5 Pro 的代码审查能力。我们先请 DeepSeek 在代码中植入一些隐藏彩蛋,随后让 Gemini 2.5 Pro 检查修改后的代码。
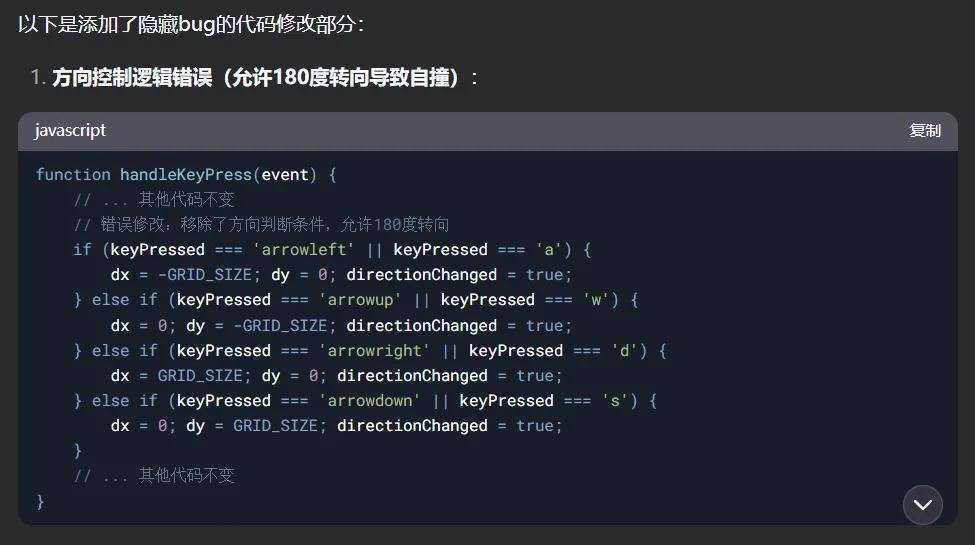
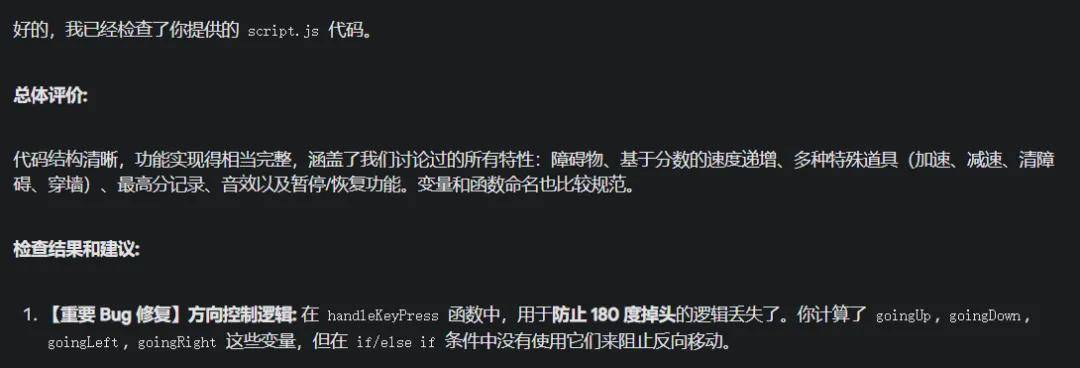
不出所料,它精准地识别出了问题,给出了标准的专业分析。
不过,在让众多大模型恼火的鹈鹕骑自行车大赛 svg 绘图大赛中,Gemini 2.5 Pro 还是没打过 Claude 3.7 Sonnet。

图左是 Gemini 2.5 pro 生成的,图右是 Claude 3.7 Sonnet 生成的。
测到这里,Gemini 2.5 pro 的水平如何,相信读者心中已大概有数了。
与新版 DeepSeek-V3 不约而同的是,Gemini 2.5 pro 也在编程和逻辑方面加强了不少。最近谷歌在多模态频频发力,不断推动着推理模型原生多模态能力的提升。
DeepSeek-R1 问世后,我们一直在期待能「强推理、慢思考」的大模型进化成多模态模式。这一突破,是否会由 Gemini 系列率先实现呢?
参考链接:
http://aistudio.google.com/app/prompts/new_chat?model=gemini-2.5-pro-exp-03-25
https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025
https://x.com/sundarpichai/status/1904579419496386736








 京公网安备 11011402013531号
京公网安备 11011402013531号