
作者 | 程茜
编辑 | 漠影
3月22日报道,昨夜,腾讯正式将混元大模型系列的深度思考模型升级为混元-T1正式版。
T1是腾讯自研的强推理模型,吐字速度达到60~80token/s,在实际生成效果表现中远快于DeepSeek-R1。

该模型的前身是,今年2月中旬混元团队在腾讯元宝APP上线的基于混元中等规模底座的混元T1-Preview(Hunyuan-Thinker-1-Preview)推理模型。
相比于T1-Preview,T1正式版基于腾讯混元3月初发布的业界首个超大规模Hybrid-Transformer-Mamba MoE大模型TurboS快思考基座,通过大规模后训练扩展了推理能力,并进一步对齐人类偏好,这也是工业界首次将混合Mamba架构无损应用于超大型推理模型。
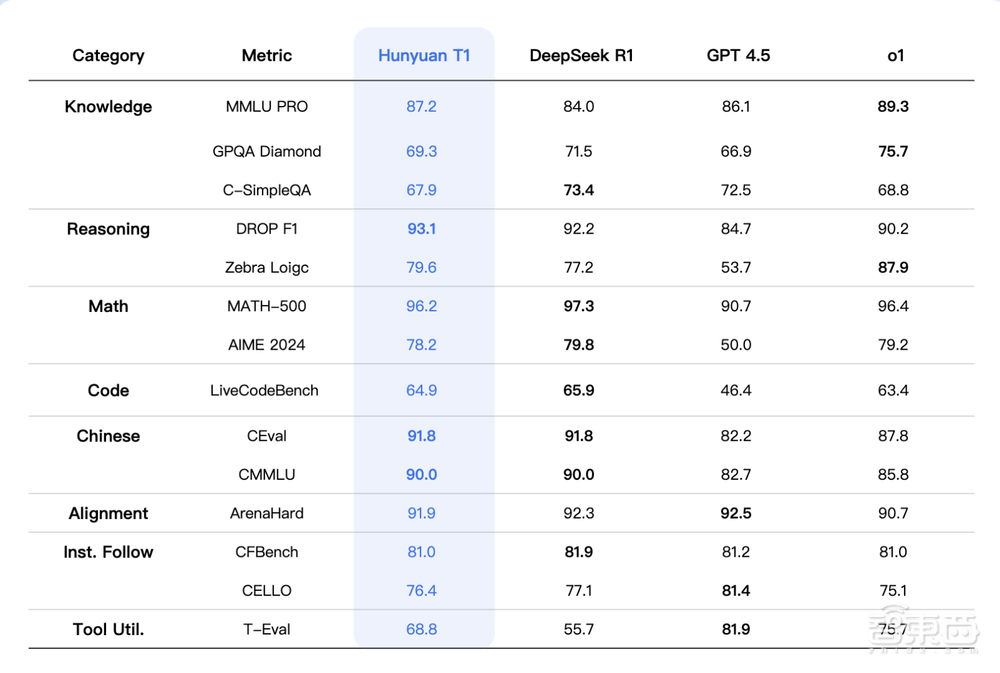
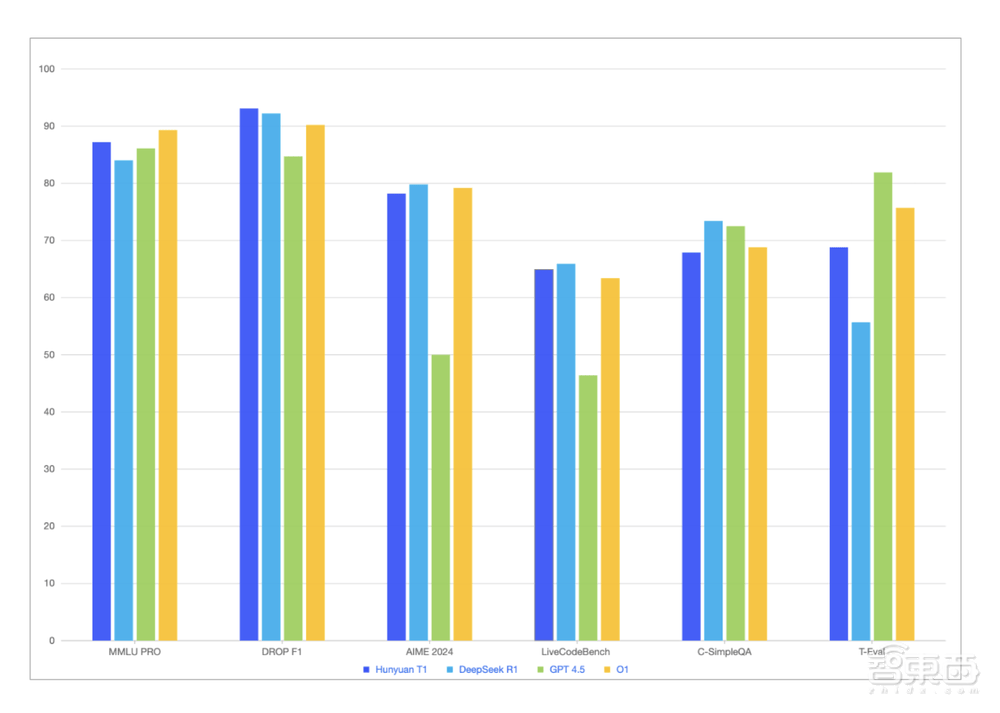
T1在多个公开数据集的评测结果显示,在MMLU-pro、Ceval、AIME、Zebra Loigc等中英文知识和竞赛级数学、逻辑推理指标上基本持平或略超R1。
目前,T1已在腾讯云官网上线,输入价格为每百万tokens 1元,输出价格为每百万tokens 4元,输出价格为DeepSeek标准时段的1/4,与DeepSeek优惠时段一致。
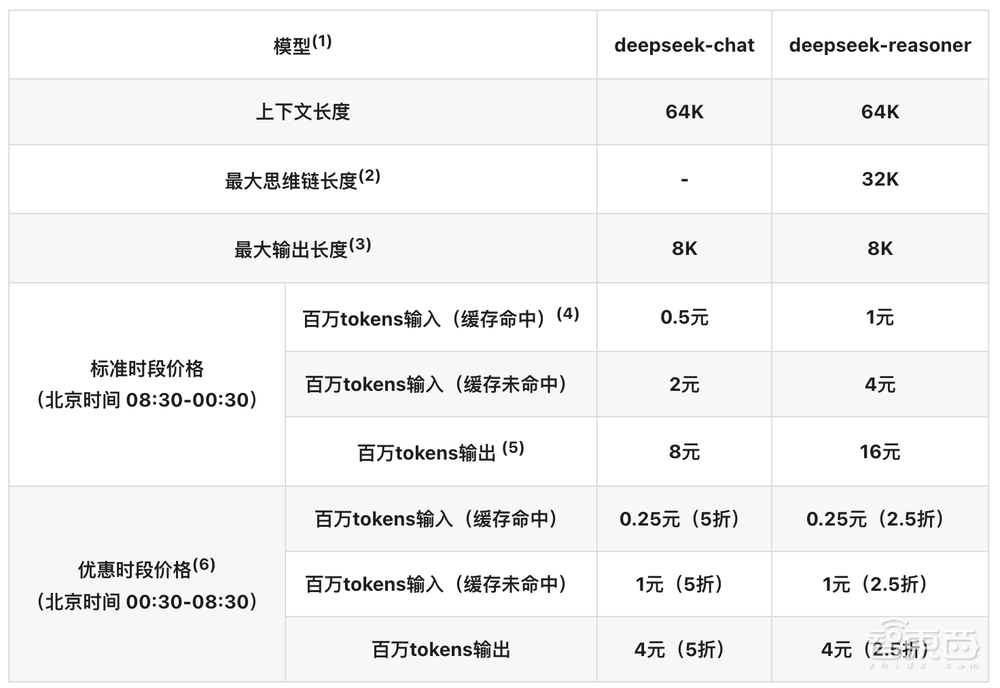
▲DeepSeek API价格
Hugging Face地址:https://huggingface.co/spaces/tencent/Hunyuan-T1
GitHub地址:https://github.com/Tencent/llm.hunyuan.T1
一、生成速度超DeepSeek-R1,复杂指令、长文摘要、角色扮演均能胜任
在知识问答场景,腾讯混元研究团队展现了T1和DeepSeek生成效果的对比。
第一个提示词是“醋酸乙酯能与水混合吗”。可以看到T1和DeepSeek-R1整体生成结果的长度、结果都相近,不过T1的生成速度明显更快。
第二大考验难题是关于理科数学推理,这一问题中对于模型的限制条件更多,其思维过程更长。从输出结果来看,T1和DeepSeek-R1生成的结论一致,速度仍然是T1更快。
第三大难题考验的是复杂指令跟随能力。让T1对出下联,提示词中给出的上联是“深深浅浅溪流水”。这其中的难点在于,模型要遵循一致的三点水偏旁、前四个字是AABB结构。T1的思考过程中,准确分析出了上联的特点,并在经过多次错误尝试后给出了答案:“洋洋洒洒波涛涌”。
第四大难题是通用任务,其提示词为开放问题“生成一个朋友圈文案,主题是漫漫人生路”,这之中并没有给出明确的风格指令要求,属于开放性问题。
T1还可以作为生产力工具,提升用户的工作效率,下一个Demo演示的是T1长文总结摘要的能力。
提示词时“针对微软收购暴雪的4000字左右新闻报道,要求T1总结一下文章内容”。在输出结果中,T1不仅总结了文章的主要内容,还提炼出新闻报道中的多个关键数字。

最后一个演示是关于模型的角色扮演能力。提示词为“请扮演李白,语气符合李白特征,猜一个字谜:告状无效”。T1的思考过程重点分析了字谜,得出结果为“皓”后,按照李白的口吻输出了答案并赋诗一首。
二、多项测试集结果对标R1,沿用混元Turbo S创新架构
混元-T1除了在各类公开Benchmark、如MMLU-pro、Ceval、AIME、Zebra Loigc等中英文知识和竞赛级数学、逻辑推理指标上基本持平或略超R1外,在腾讯内部人工体验集评估上也能对标,其中文创指令遵循、文本摘要、Agent能力方面略胜于R1。
在测试基座模型对于广泛知识理解的记忆和泛化能力的数据集MMLU-PRO上,T1得分仅次于o1,在Ceval、AIME、Zebra Logic等中英文知识及竞赛级数学、逻辑推理的公开基准测试中,T1的表现与R1基本持平或略超R1。
从技术角度来看,混元T1正式版沿用了混元Turbo S的创新架构,采用Hybrid-Mamba-Transformer融合模式,这也是工业界首次将混合Mamba架构无损应用于超大型推理模型。这一架构能降低传统Transformer架构的计算复杂度,减少KV-Cache内存占用,降低训练和推理成本。
在长文本推理方面,TurboS的长文捕捉能力可以有效解决长文推理中的上下文丢失和长距离信息依赖难题。Mamba架构可专门优化长序列处理能力,并通过高效计算方式在保证长文本信息捕捉能力的同时,降低计算资源的消耗,使得模型相同部署条件下、解码速度快2倍。
模型后训练阶段,腾讯混元研究团队将96.7%的算力投入到强化学习训练,重点围绕纯推理能力的提升以及对齐人类偏好的优化。
数据方面,T1的高质量prompt收集主要集中于复杂指令多样性和不同难度分级的数据。研究人员基于世界理科难题,收集了涵盖数学/逻辑推理/科学/代码等的数据集,包含从基础数学推理到复杂科学问题解决的问题,然后结合ground- truth的真实反馈,确保模型在面对各种推理任务时的表现。
训练方案上,T1采用课程学习的方式逐步提升数据难度,同时阶梯式扩展模型上下文长度,使得模型推理能力提升的同时学会高效利用token进行推理。
研究人员在训练策略方面,参考了经典强化学习的数据回放、阶段性策略重置等策略,提升了模型训练长期稳定性50%以上。
在对齐人类偏好阶段,其采用self-rewarding(基于T1- preview 的早期版本对模型输出进行综合评价、打分)+reward mode的统一奖励系统反馈方案,指导模型进行自我提升。
结语:腾讯混元模型迭代加速
腾讯混元模型系列今年进入快速迭代期,其陆续推出腾讯混元深度思考模型T1和自研快思考模型Turbo S。此前,混元Turbo S在技术突破方面实现了首字时延降低44%,并已应用于腾讯元宝等腾讯内部产品。
此次发布的腾讯混元深度思考模型T1预览版也早已上线腾讯元宝,可以看出,腾讯内部业务和场景已经全面接入混元系列大模型能力,如腾讯元宝、腾讯云、QQ、微信读书、腾讯新闻、腾讯客服等。
在此基础上,腾讯混元团队正在探索新的研究思路,找到降低大模型幻觉、降低训练成本等的新解题思路。









 京公网安备 11011402013531号
京公网安备 11011402013531号