中科视语在具身智能领域再获突破!此前,中科视语发布了PhysVLM——首个开源机器人物理空间具身大模型。该模型突破了传统模型普遍存在的局限,通过多模态感知、动态环境建模与自主决策规划的深度融合,PhysVLM成功赋予机器人在复杂物理空间中类人级的操作能力。
当前,中科视语再次取得关键进展,发布首个开源轻量化具身决策深度推理大模型——LightPlanner,通过创新的层次化决策框架,成功突破边缘设备上 “轻量与智能不可兼得” 的行业难题,为机器人在物流、制造、服务等场景的规模化部署奠定了技术基础,持续引领具身智能技术的创新与发展。
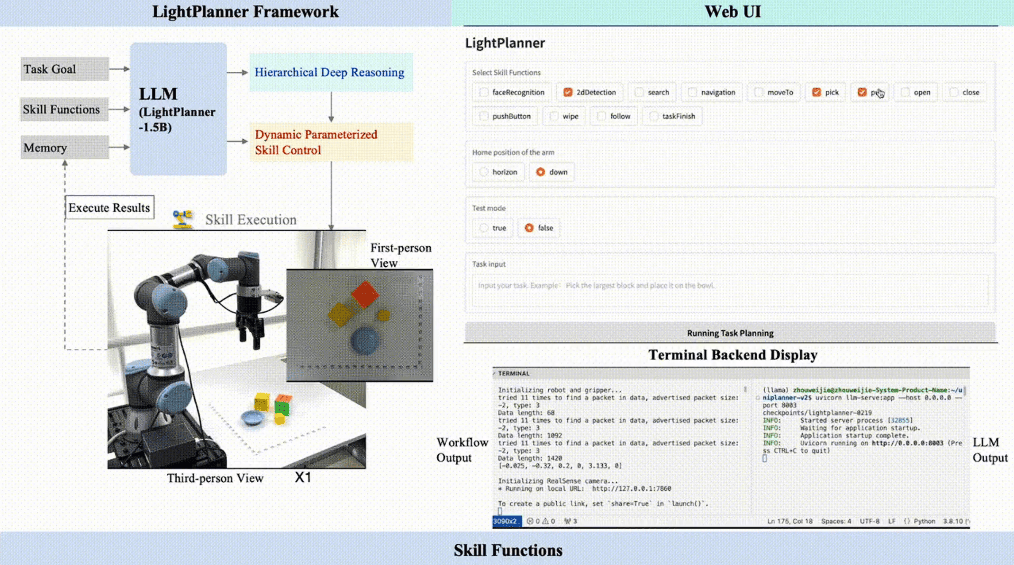
让边缘端机器人“既能思考又能行动”
传统大语言模型(LLM)在具身任务中展现了强大的语义理解能力,但其庞大的参数规模难以在边缘设备上高效运行。轻量级模型虽解决了算力限制,却因缺乏复杂推理能力,如在 “抓取最大积木” 等需动态逻辑判断的任务中表现乏力。这一“推理能力瓶颈”已成为制约轻量级具身智能系统规模化应用的核心障碍。
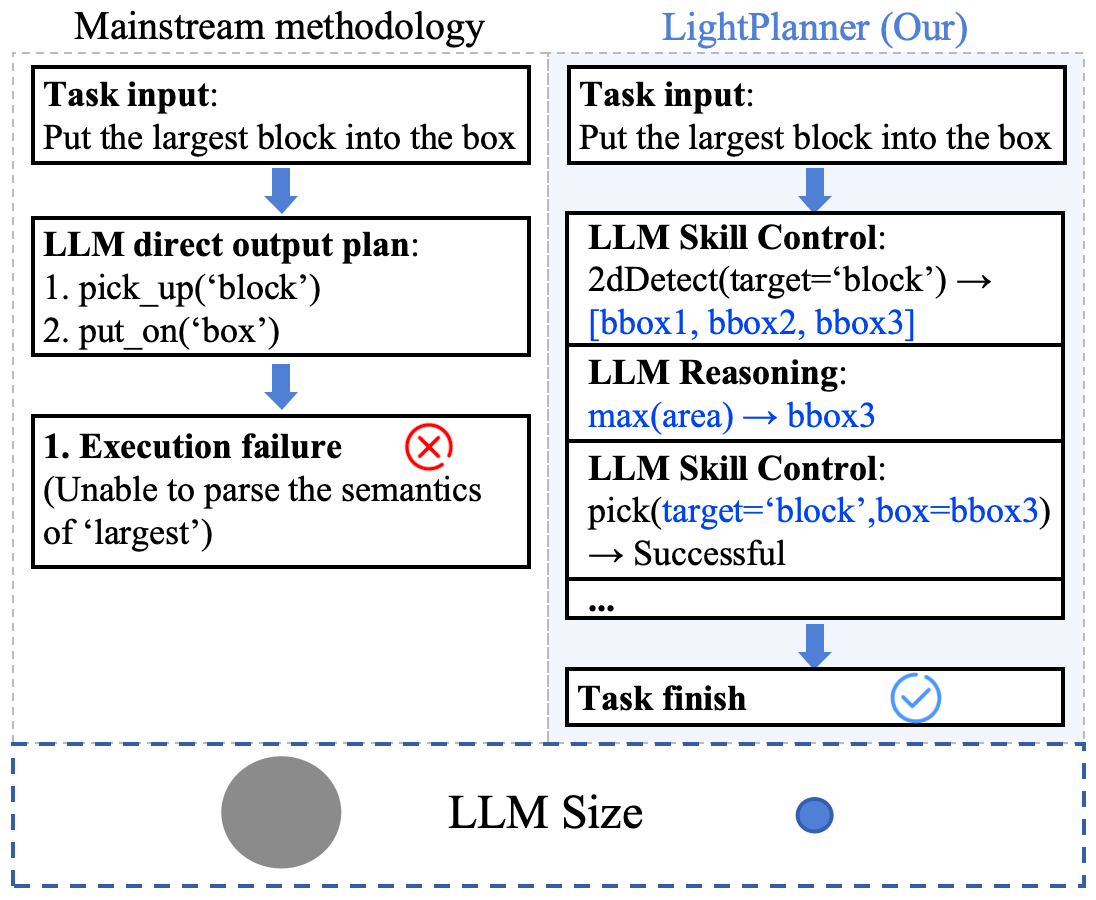
图1: LightPlanner与主流任务规划方法的对比
针对这一挑战,中科视语提出了首个具身规划决策的轻量化深度推理大模型——LightPlanner。借鉴DeepSeek-R1在复杂任务推理中的成功经验,LightPlanner通过创新的层次化深度推理和动态参数化技能控制方法,充分释放了多种规格轻量级LLM的推理能力,以提升其在复杂任务规划中的性能。LightPlanner在机器人规划决策任务中复现了类似DeepSeek-R1的“回溯、反思、纠错”行为,从而显著提高了任务规划的准确性和系统的鲁棒性。

图2: LightPlanner在决策推理时出现的“回溯、反思、纠错”行为
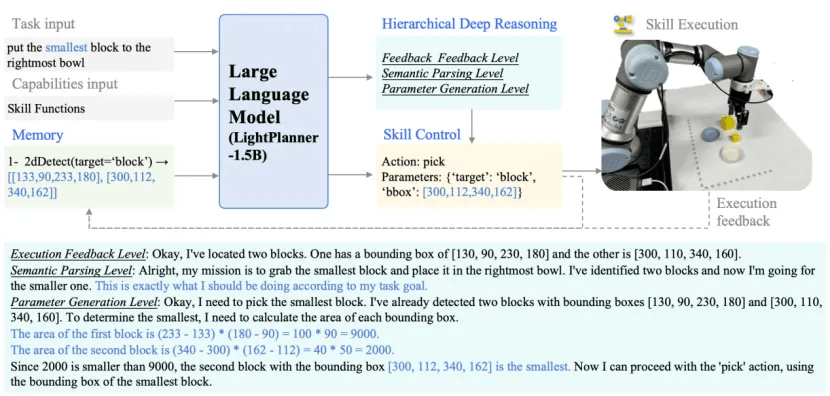
图3: LightPlanner框架,生成层次化深度推理与动态技能控制
LightPlanner三大核心创新突破
● 层次化深度推理
模拟人类决策逻辑,在每一步执行前触发三层验证:
· 执行反馈:通过历史记忆动态修正偏差,实现 “错误自愈”;
· 语义一致性:确保子动作与全局任务目标对齐;
· 参数有效性:实时计算抓取对象的空间位置等连续参数,提升动作精度。
● 参数化动态技能链
突破固定技能模板限制,通过上下文感知的函数调用机制,动态解析指令中的动态参数(如 “最大积木” 需实时计算面积并定位),使得系统能够执行需要视觉或空间推理的复杂具身任务。
● 边缘设备友好架构
在大模型的输入端引入一个动态更新的历史行动记忆模块,结合迭代式上下文管理,显著降低显存占用。在长期任务规划中,平均显存占用不超过3.9G(未量化),满足边缘端设备的部署需求。当前设备已支持Nvidia jetson 系列边缘计算设备,以及瑞芯微、算能、华为Atlas等国产化边缘计算设备
开源生态:4万级数据集+轻量模型,加速产业落地
为推动技术普惠,团队同步开源了:
开源量化模型:模型提供0.9到2.7g多种量化版本,凭借其卓越性能与实用价值,近期在Hugging Face平台热度飙升,单周下载总量已突破300次。
LightPlan-40K 数据集:首个具身决策深度推理数据集,覆盖动作序列长度为2-13的不同复杂度任务,总计包含4万个带有层次化深度推理的动作决策步骤,其中精选2.3万条高质量数据作为训练集。
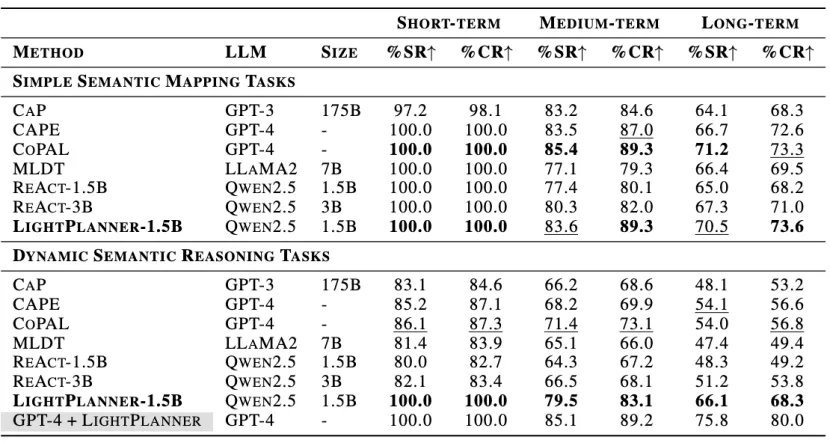
表1: 不同复杂度的任务中的性能表现
我们基于LightPlan-40K数据集训练了LightPlanner模型。实验结果显示,在真实世界环境中的具身决策规划任务中,尽管LightPlanner的参数数量最少,仅为1.5B,但其任务成功率最高。在需要空间语义推理的任务中,其成功率比ReAct高出14.9%。此外,实验还展示了LightPlanner在边缘设备上的运行潜力,突显其在资源受限环境中的适用性。

图4: LightPlanner在Jetson Xavier Orin上的部署展示






 京公网安备 11011402013531号
京公网安备 11011402013531号