
出品 |
作者 | 梁昌均
编辑 | 杨锦
没有发布会、没有李彦宏,百度近日低调发布两款大模型——文心4.5和深度推理模型文心X1,免费。
两年前的3月,百度发布了对标ChatGPT的文心一言。这是全球大厂中首个生成式AI产品,也让外界看到百度相对迅速的先手布局。
不过,百度后来采取的收费策略,缺乏突出亮点的产品性能,以及模型迭代放缓,文心一言(APP端为文小言)并未出圈。相较后起之秀,如豆包、Kimi等更是逊色。
DeepSeek的爆火让百度反思起内部AI战略。早前,百度宣布文心一言不再收费,同时还会开源新一代模型。按照计划,文心大模型4.5将在6月30日起开源。
同时,行业还掀起新的大模型技术竞赛——以OpenAI、DeepSeek为代表的企业在深度推理模型开启竞争,压力给到百度。
经历了两年多的大模型技术浪潮,百度AI成色如何?
连发两款模型“补课”
这次更新的文心4.5,相较文心4.0-Turbo过去了8个月,相较文心4.0过去了15个月,百度到底拿出了什么压箱底的技术实力?
按百度说法,文心4.5定位新一代原生多模态基础大模型,在多个基准测试中超过GPT-4o,得分最高的则是DocVQA,该基准主要测试文档图像的问答能力。
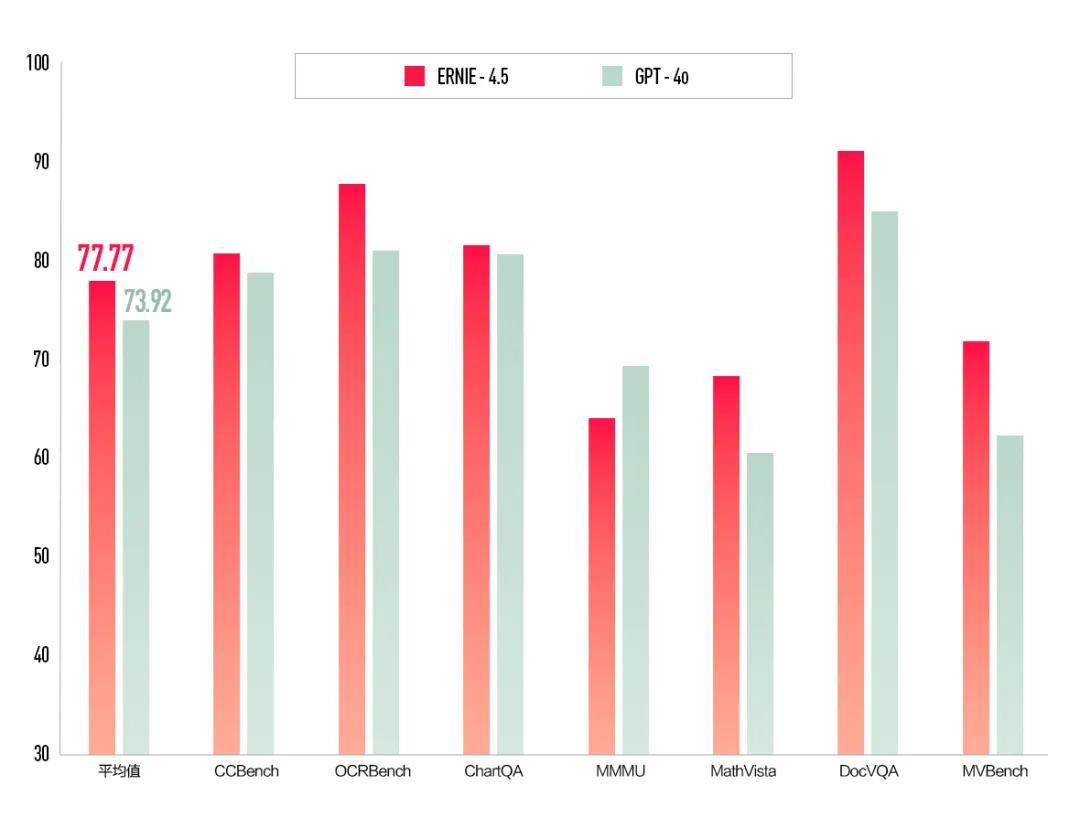
在文本能力方面,文心4.5则在多个主流基准测试中超过DeepSeek-V3、GPT-4o,部分基准(如大规模多任务语言理解基准MMLU-Pro、生物、物理和化学学科基准GPQA、代码生成基准Humaneval+)得分则不及GPT-4.5,但综合成绩超过GPT-4.5。
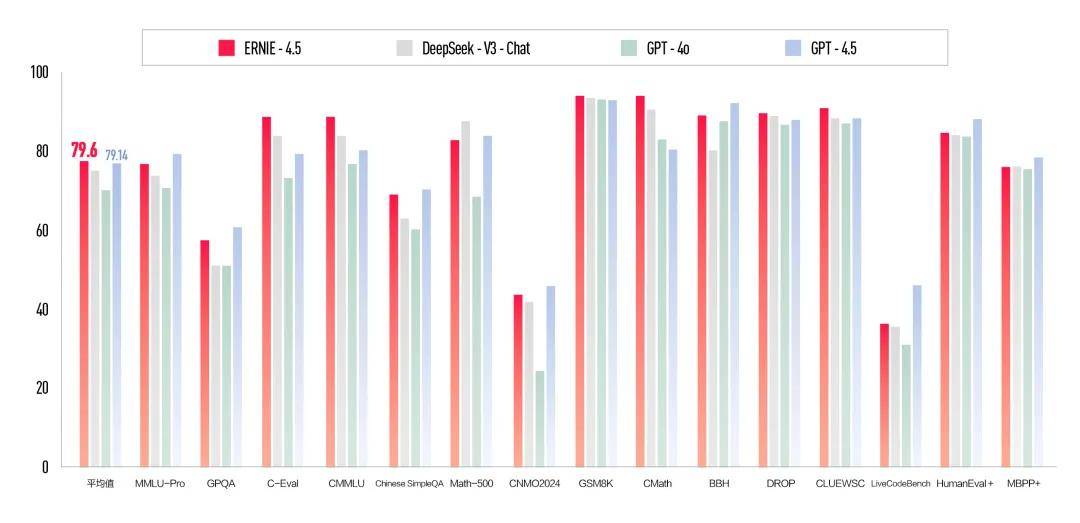
在具体能力方面,文心4.5支持文字、图片、音频、视频等多模态内容的上传和理解,相较文心4.0-Turbo新增视频、语音输入和联网搜索功能(网页版)。

百度还首次推出深度推理模型文心X1。虽然相较OpenAI发布o1已经过去半年,但百度还是打出自己的差异化特色——支持多模态(包括图像理解和图像生成),并能调用工具。
百度表示,文心大模型X1性能对标DeepSeek-R1,具备长思维链,擅长中文问答、文学创作、逻辑推理等。不过,百度并未公布有关基准测试和DeepSeek-R1、o1等同类模型的对比。
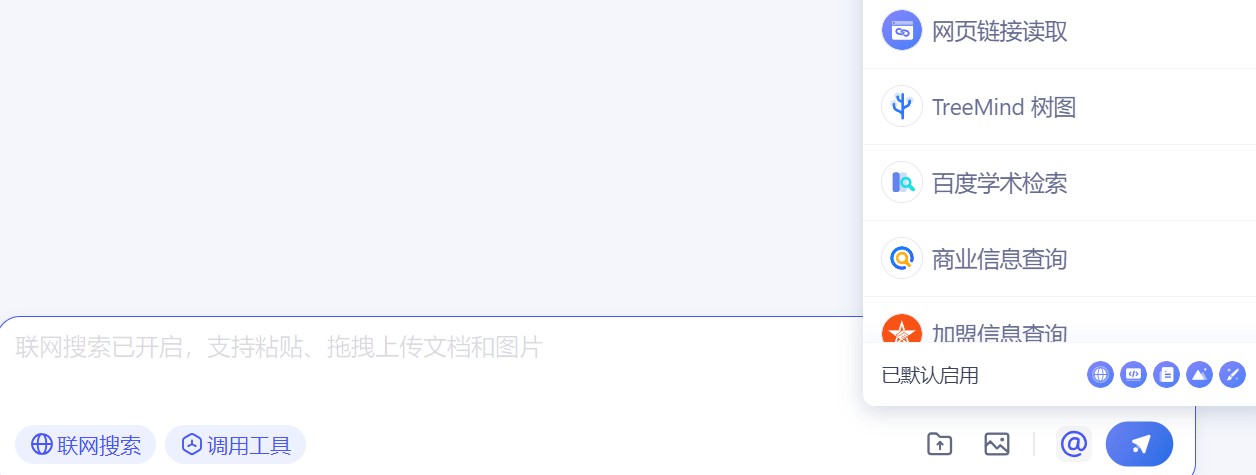
注意到,文心大模型X1默认启用联网搜索、代码解释器、文档问答、图片理解、AI绘图等工具,还有网页链接读取、TreeMind树图、百度学术检索、商业信息查询、加盟信息查询、词云生成等工具供使用。
目前,这两款模型均已在文心一言官网免费上线,文小言APP则将两者合二为一。同时,这两款模型面向企业和开发者也有较大价格优势。
文心4.5的API输入价格为4元/百万tokens,输出为16元/百万tokens,相较文心4.0-Trubo综合价格下降78%。
同时,该价格约为GPT-4.5的1%,GPT-4o价格的五分之一,且均为DeepSeek-V3(标准时段)的一半。但相较通义、豆包主力模型,文心4.5还是贵出好几倍。
文心X1的输入价格为2元/百万tokens,输出为8元/百万tokens,均为DeepSeek-R1(标准时段)的一半。同时,相较OpenAI的o1价格优势更大,不到其2%。
和DeepSeek对比有优有劣
说了这么多,百度最新模型到底如何?首先看看此前难倒不少模型的测试。对于9.11和9.8哪个大的问题,文心X1则表示首先需要明确数字的具体含义,并考虑了多种可能,最终从作为小数、日期和时间进行了比较。

DeepSeek则没有想这么多,直接视为数值进行比较,给出了正确答案,并写出了非常清晰的步骤解析。

接下来看看语言生成能力。“啄木鸟公司被今年315晚会点名,假如你现在是他们公司的公关,需要写一封公关声明,用自嘲的风格,你会怎么写?”这个有一定难度,要求用自嘲风格写,很容易翻车,大模型能胜任吗?

作为消费者,看完这两份声明,会更容易接受哪个呢?不过,这种危机公关可能并不适合用自嘲的风格,但从要求的风格看,文心X1自黑程度感觉比DeepSeek狠,但却把本该严肃的道歉信写得过于“活泼”。

文心X1还具备多模态和调用工具能力,以百度去年四季度财报为例,要求这两个模型提取四季度的营收、净利润等关键数据,并用图表形式呈现。这个任务挺复杂,涉及到图片的内容识别、文本翻译,以及图表生成。
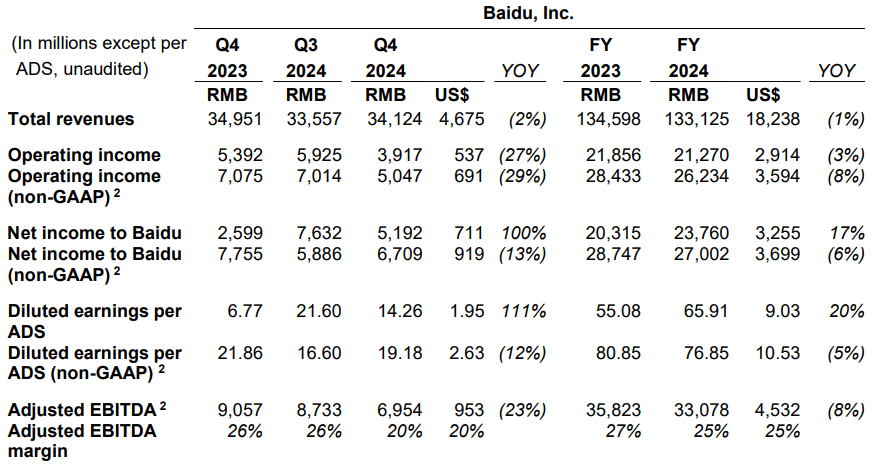
文心X1则在思考和行动过程中调取了图片理解,对图片进行识别,然后调用代码解释器,用python写了生成图表的代码。
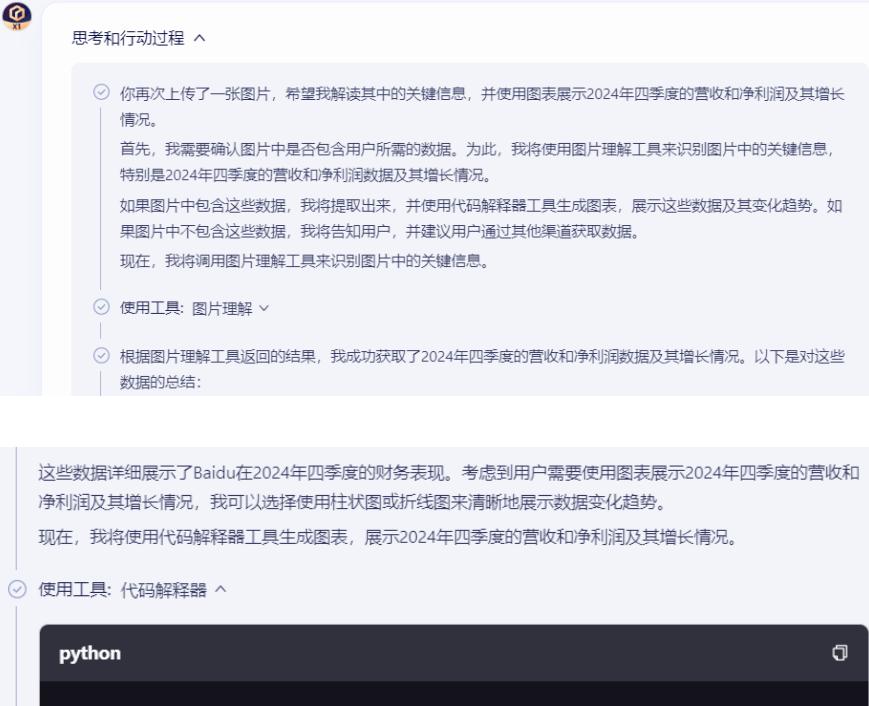
最终文心X1输出了这张图片的数据解读,从营收数据、净利润数据和其它关键信息进行了罗列。不过,认真对比后发现不少错误,比如去年四季度营收数据的环比变化,实际略有增长,净利润数据则搞错GAAP和非GAAP和相应的增长情况。

最终生成的图表,则把营收、净利润及其增长情况进行了“一锅炖”,没有分门别类,进行清晰地对比呈现。
再来看看DeepSeek的表现,首先用表格清晰地展示了四季度营收、净利润及其增长情况,并将原来的单位百万转换成亿,更符合阅读习惯,而且全文输出的数据基本没有错误,还补充了对增降变化的分析。整体来看,图片识别理解和内容归纳能力相对文心X1更好。

不过,由于DeepSeek并没有图像生成能力,因此无法输出可视化图表,但给出了设计逻辑,把营收和净利润数据设计为柱状图,把增速设计为折线图,思维相当清晰。
此外,文心X1还具有树图功能,适用于复杂的逻辑关系。比如《红楼梦》中的人物非常之多,贾宝玉作为核心,可以说有着非常复杂的人际关系网,这时候就可以让X1来进行梳理,可以选择TreeMind 树图,它就会生成贾宝玉的人际关系网。如果不满意,还可以点击编辑。
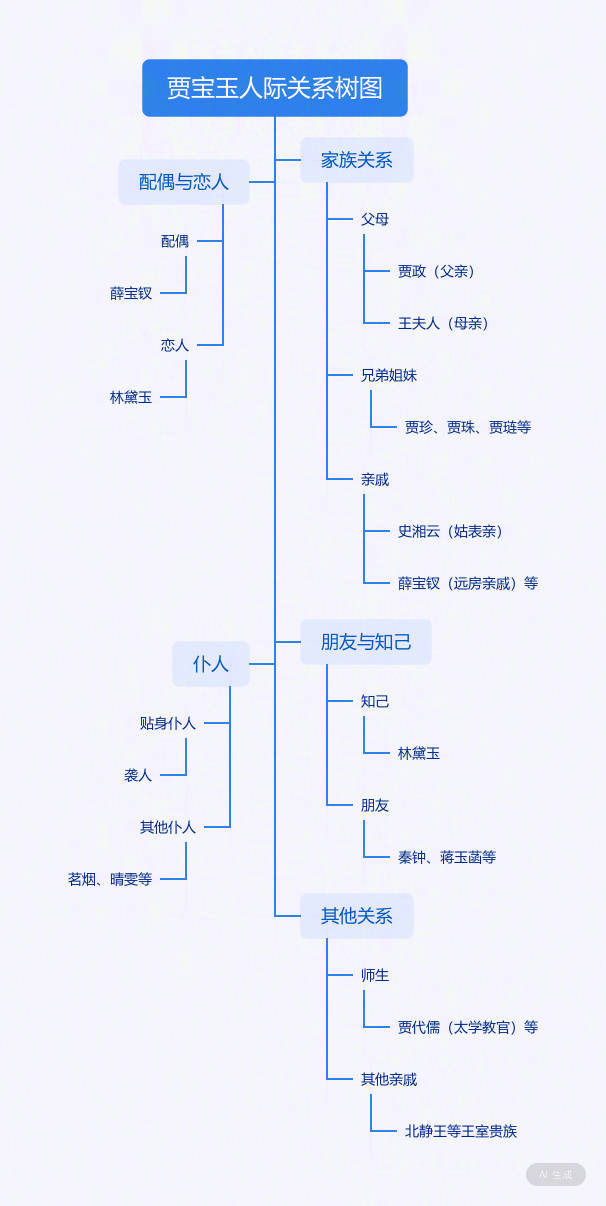
从这些初步测试来看,虽然文心X1号称对标DeepSeek-R1,但它在某些方面,比如图片识别理解、思维过程逻辑等方面稍有逊色,但它具备图像生成、工具调用等功能,一定程度有点Agent的感觉了。
不过,某种程度看,这些工具更像是文心X1的“外挂”,且导向百度旗下的其它产品,比如百度学术检索、商业信息查询、加盟信息查询,分别指向百度学术、爱企查、加盟星等产品。
百度AI想翻身还要再等等
在百度发布这两款模型后,反响一般。有使用过的AI业内人士表示,百度的这两款模型并没有特别大的惊艳之处。还有人批评称,文心4.5像个半成品。
不过,这在海外引发了一些讨论。知名风投机构Benchmark合伙人Bill Gurley转发百度推文评论到:“美国AI公司应将100%的时间用于开发和创新,而不是在华盛顿特区游说寻求保护以躲避竞争。”
他说的可能是OpenAI这样的公司,此前该公司发文攻击DeepSeek,称其模型会带来“重大风险”,并要求美国政府采取行动。
百度原计划文心4.5要等到6月底才会开源。目前,百度仅初步透露了多个层面的技术优化,包括注意力机制、模型架构、模型幻觉等方面。
据介绍,文心4.5采用自研的FlashMask动态注意力掩码,降低了计算冗余和存储开销,可提升模型长序列建模能力和训练效率,优化了长文处理能力和多轮交互表现。
这和DeepSeek-V3在Transformer框架之上,通过MLA(多头潜在注意力)降低算力成本,有着异曲同工之处。
作为多模态大模型,文心4.5还采用了多模态异构专家扩展技术,这是一种将多模态数据处理与混合专家模型(MoE)相结合的架构。
在多模态训练中,文本、图像、视频等不同模态对模型参数更新速度或幅度存在不均衡的情况,可能导致某些模态形成主导,其它模型贡献较弱,从而影响模型训练效果和最终性能。
文心4.5通过引入MoE架构,根据不同模态建立专家模型,并设计自适应模态感知的损失函数,动态调整不同模态的权重(降低过高模态的权重,提高过低模态的权重),从而解决不均衡问题,提升多模态融合能力。
对注意力算法和MOE架构的优化已经成为业内关注的方向之一。此前,豆包大模型团队就开源了一项针对MoE架构的关键优化技术,可将大模型训练效率提升1.7倍,成本节省40%。
视频上传和理解,是文心4.5区别其它多数大模型的差异化能力,如GPT-4o支持实时视频通话,并不支持视频上传。拥有这类能力的还有阿里通义模型,其支持单个最大6G的视频,而文心4.5仅支持12M的单个视频,在高分辨率的情况下可能只有10秒左右。
对于图片和视频的理解,文心4.5则采用了时空维度表征压缩技术,提升对多模态数据的训练效率。比如,对于视频数据,可以降低帧率(时间维度)和分辨率(空间维度),从而减少数据规模和复杂度,提升训练效率。
在推理模型方面,文心X1则采用递进式强化学习(不断调整和优化对模型进行反馈)、基于思维链和行动链的端到端训练等关键调优技术,大幅降低推理成本。
目前,国内外都在探索强化学习的潜力。阿里此前推出的QwQ-32B,就借助大规模强化学习,实现整体性能比肩DeepSeek-R1,并实现可在消费级PC上部署。
对于有着研发、资金,以及基础设施和应用生态优势的百度来说,面对新一轮的大模型技术竞赛,还需要提高技术进步的速度。
“坚决投入大模型和生成式人工智能的技术研发。”这是李彦宏此前的多次表态。但在态度背后,百度还需要交出达到外界期待的兑现成果。
今年下半年,百度将推出文心5.0。届时,百度是否会像OpenAI一样,推动多模态大模型和推理模型的融合,值得关注。






 京公网安备 11011402013531号
京公网安备 11011402013531号