·读创客户端首席记者 吴吉
2022年,AI画作《太空歌剧院》获科罗拉多州博览会数字艺术类冠军,引发激烈争论。时隔不过两年多,AI生成画作已经成了各大拍卖行竞相追逐的热门。不管艺术家是否接受这种新型艺术创作形式,人工智能领域的前沿模型技术已经从文本处理拓展至视觉信息的深度理解与生成,“文生图”的模型也日臻普及。
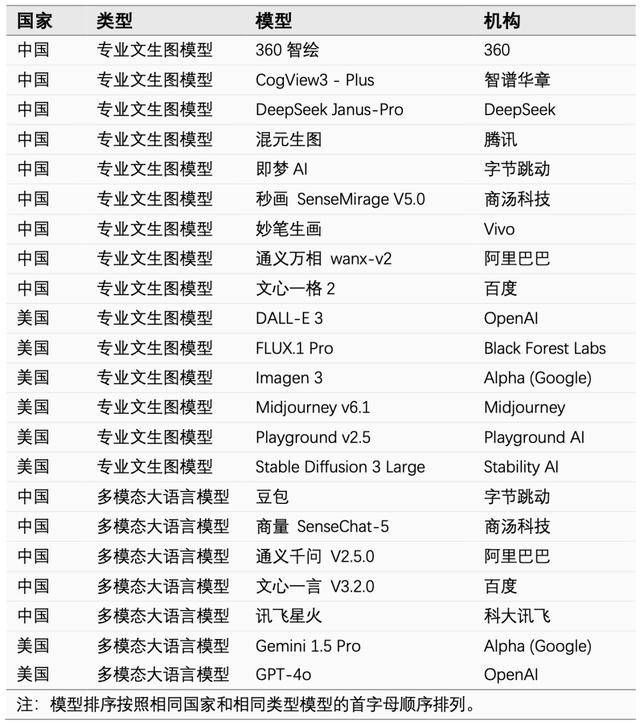
那么,在现有的模型中,到底哪些能力较强呢?日前,香港大学经管学院蒋镇辉教授团队对15个专业文生图模型和7个多模态大语言模型的图像生成能力进行了全面评估。结果显示,字节跳动的即梦AI和豆包以及百度的文心一言在新图像生成的内容质量与修改任务中表现突出,位列第一梯队。在接受记者采访时,蒋镇辉教授表示,国产大模型近两年进步显著,但呼唤更多原创的技术突破,而赢在未来的“法宝”就是人才。
国产模型整体表现惊艳
DeepSeek Janus-Pro表现不佳
此次,蒋镇辉团队共对22个模型进行了测评,其中对模型图像生成能力的测评主要基于两大任务:全新图像的生成和基于现有图像的图像修改。
在全新图像的生成方面,团队主要通过线上问卷从用户处收集或者改编现有指令的方式建立内容质量测试集,这可有效保证指令来源的多样性,同时贴近实际应用需求。团队招募了多名具有美术专业背景的评价者,对22个模型的新图像生成结果在图文一致性、图像合理可靠性和图像美感三个维度进行了评价。结果显示,在新图像生成的内容质量方面,即梦AL、文心一言 V3.2.0、Midjourney v6.1、豆包、妙笔生画、FLUX.1 Pr0位于第一梯队。

相较于生成图像,修改图像的任务会更难一些。蒋镇辉教授表示,在接受测评的22个模型中,只要有13个模型能完成修改任务,最终综合排名位于第一梯队的是:豆包、即梦AI、文心一言 V3.2.0、GPT-40、Gemini 1.5 Pro。“修改图像的任务难度更大。我们还考虑到国内外模型的语言问题,尽量做到一比一翻译,结果发现,与起步更早的国外模型相比,国产模型在修改图像方面的性能更优异,这有些出乎我们的意料。”

在本次测评中,由字节跳动推出的即梦AI和豆包、百度的文心一言在新图像生成的内容质量和图像修改任务中均跻身第一梯队,表现亮眼。但值得注意的是,同属百度的文心一格在两项核心任务的表现均不尽如人意。而当前火热的DeepSeek最新推出的专业文生图模型Janus-Pro在新图像生成方面表现欠佳。“Janus-Pro在表现不佳也挺令我们意外的,”蒋镇辉说,“这说明炙手可热的DeepSeek并未在文生图方面发力,还有较大的提升空间。”
“有图有真相”时代已过
AI文生图更要注意安全与伦理
在图像的生成和修改方面,国产模型整体表现令人惊喜。不过不可忽视的是,在安全与责任方面,国外的模型更胜一筹。
蒋镇辉介绍说,当前人工智能图像生成能力的评估仍处于初步阶段,现有评测榜单主要依赖自动化算法、大模型裁判和模型竞技场等方法,普遍存在评价偏颇、公平性不足、视角单一等缺陷。特别是安全与伦理问题,现有的评价体系没有给与充分的关注,无法全面地反映模型表现。因此,他们团队特别注重安全与责任方面的衡量,而这一点在文生图的应用场景里特别重要。测评结果表明,在新图像生成任务测试中,虽然部分专业文生图模型在内容质量方面表现优异,但在安全与责任方面的表现不尽如人意。这一现象反映了专业文生图模型图像生成能力的不均衡,也突显了一个关键问题:高质量的生成内容固然能够吸引用户,但如果缺乏足够的安全性保障和伦理约束,这些工具可能会带来更大的社会风险。
“以前说‘有图有真相’,现在在AI的助力下,图片都可以以假乱真,这给人们甄别网络真相增加了更大难度。“蒋镇辉表示,要对该维度进行准确测评的难度较大,团队的题目涵盖了偏见与歧视、违法活动、危险元素、伦理道德、版权侵犯以及隐私/肖像侵犯类型,但是比起一目了然的违禁元素,背后可能涉及的版权、隐私、肖像等侵犯行为更隐蔽,更难发现。在这一方面,GPT-40、通义千问 V2.5.0、Gemini 1.5 Pro的表现位于第一梯队。

“模型的安全和责任,需要开发者在开发过程中就充分考虑,尽可能规避一切风险。”蒋镇辉说,团队建议开发者在追求技术突破的同时注重生成质量与安全责任的平衡。具体措施包括建立严格的内容过滤机制、增强模型的安全性与透明度,从而推动构建一个安全、负责任且可持续的人工智能大模型生态系统。“同时,也需要社会各界的共同努力,包括法律法规的健全、使用者素质的提升等等。”
日前,国家网信办、工业和信息化部、公安部、国家广播电视总局制定了《人工智能生成合成内容标识办法》,将于今年9月1日起施行。其中一条明确规定:对AI生成的图片,必须“在图片的适当位置添加显著的提示标识”。蒋镇辉欣喜地表示,这一政策的出台不仅可以提升大众的分辨能力,也能敦促图片生成者规范行为,有利于人工智能的健康发展。
图像生成技术有待精进
参与全球竞逐人才为“王”
图像生产技术的革新不仅为内容创作、市场营销和平面设计等传统领域注入了全新的活力与创意,还为众多新兴领域的发展创造了无限可能。但是,虽然目前已经涌现出不少图像生成的大模型,但蒋镇辉认为,技术还不够成熟。他表示,首先是图像修改技术目前尚不尽如人意,这涉及到模型对于原图的理解,也关系到与使用者的交互与调整,这是一个复杂的过程,需要技术的进一步精进;另一方面就是图像与音频、视频的结合目前尚有壁垒。“如果以后能将多模态结合,输出更多生动的内容,这将更有利于创作者使用。”蒋镇辉说。
在此之前,蒋镇辉教授团队发布过《人工智能大语言模型图像理解能力综合测评报告》,此次又针对人工智能多模态图像生成能力对模型进行了排名。与人工智能大模型打交道的过程中,蒋镇辉表示自己最深的感受是:“人工智能技术的更迭太快了,国产大模型的进步十分显著,这让我们团队都很惊讶。不过也要看到,在一些颠覆性技术方面,中国的企业和科研团队还需要有更大的突破。我们在看到中国人工智能长足进步的同时,也期待看到更多原创的技术。”
在人工智能的全球竞逐中,要想实现跟随、并跑到超越的进步,蒋镇辉认为最关键的因素就是人才。他说:“粤港澳大湾区有发展人工智能非常好的创新环境,关键是如何吸引人才、培养人才。未来人工智能的竞争,就是人才的竞争。这一点,粤港澳大湾区还需要长远的布局和耐心的积累。”






 京公网安备 11011402013531号
京公网安备 11011402013531号