3月17日,小米技术官方微博发文称,小米大模型团队在音频推理领域取得突破性进展,受 Deepseek-R1 启发,团队率先将强化学习算法应用于多模态音频理解任务,仅用一周时间便以64.5%的 SOTA 准确率登顶国际权威的 MMAU 音频理解评测榜首。现同步开源。
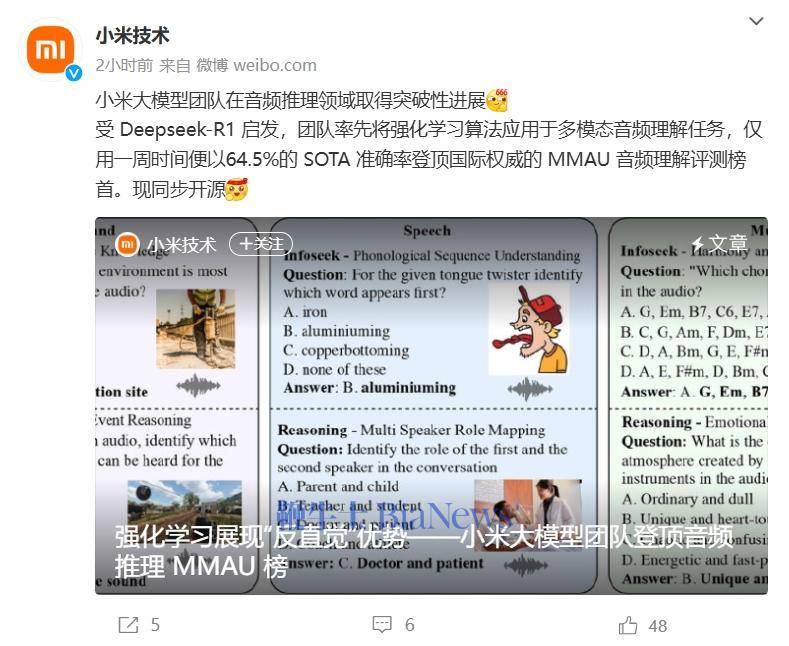
据介绍,MMAU(Massive Multi-Task Audio Understanding and Reasoning)评测集是音频推理能力的量化标尺,它通过一万条涵盖语音、环境声和音乐的音频样本,结合人类专家标注的问答对,测试模型在27种技能,如跨场景推理、专业知识等应用上的表现,期望模型达到接近人类专家的逻辑分析水平。
作为基准上限,人类专家在 MMAU 上的准确率为 82.23%。目前 MMAU 官网榜单上表现最好的模型是来自 OpenAI 的 GPT-4o,准确率为 57.3%。紧随其后的是来自 Google DeepMind 的 Gemini 2.0 Flash,准确率为 55.6%。
来自阿里的 Qwen2-Audio-7B 模型在此评测集上的准确率为 49.2%。由于它的开源特性,小米大模型团队尝试使用一个较小的数据集,清华大学发布的 AVQA 数据集,对此模型做微调。AVQA 数据集仅包含 3.8 万条训练样本,通过全量有监督微调(SFT),模型在 MMAU 上的准确率提升到了 51.8%。
DeepSeek-R1 的发布为小米大模型团队在该项任务上的研究带来了启发。DeepSeek-R1 的 Group Relative Policy Optimization (GRPO) 方法,让模型仅通过"试错-奖励"机制就能使自主进化,涌现出类似人类的反思、多步验证等推理能力。
小米大模型团队尝试将 DeepSeek-R1 的 GRPO 算法迁移到 Qwen2-Audio-7B 模型上。最终,在仅使用 AVQA 的 3.8 万条训练样本的情况下,强化学习微调后的模型在 MMAU 评测集上实现了 64.5% 的准确率,这一成绩比目前榜单上第一名的商业闭源模型 GPT-4o 有近10个百分点的优势。








 京公网安备 11011402013531号
京公网安备 11011402013531号