文 | AlphaEngineer,作者 | 费斌杰(北京市青联委员 熵简科技CEO)
25年开年以来,AI发展如火如荼,DeepSeek R1、OpenAI CUA、Manus等重要创新层出不穷,眼花缭乱。
这里我将最近一个月以来的思考总结一下,对25年AI发展趋势做几点预判。
(1)Manus:Agent元年的一次抢跑
Manus推出之后,我们第一时间拿到了体验账号,进行了充分的体验测评。
先说结论:虽然Manus目前还有种种不足,但它的产品设计思路创意满满,值得我们给予充分的肯定。
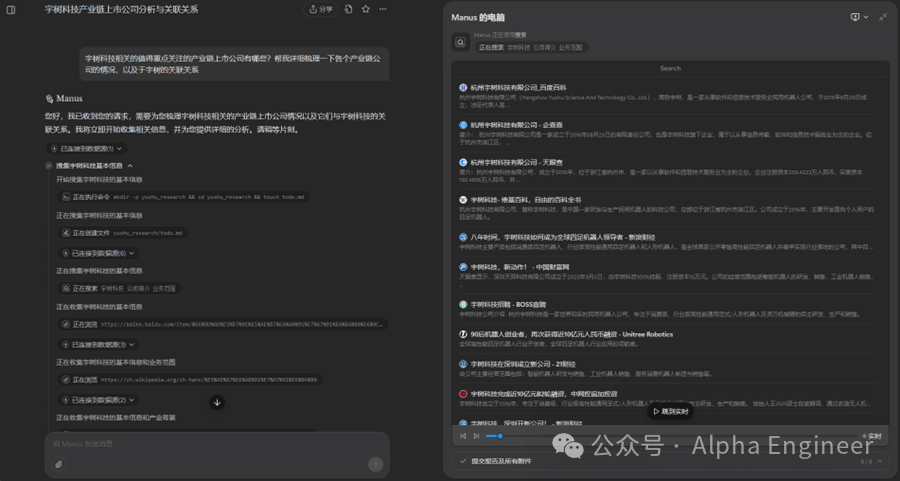
Manus的核心架构基于“虚拟机+多Agent协同”模式,通过整合多个底层大模型(如GPT-4、Claude 3等)的API,实现任务的动态分配与模型调用。
Manus突破了传统AI助手仅生成建议的局限,实现了从“需求输入”到“成果交付”的端到端闭环。
Manus提出“Less Structure, More Intelligence”的交互理念,通过无代码化的自然语言接口降低用户使用门槛。

与此同时,Manus使用一个外置的markdown文件来管理Agent的任务规划,并且将阶段性的工作成果存储为独立文件,这也是一个非常有趣的创新点。
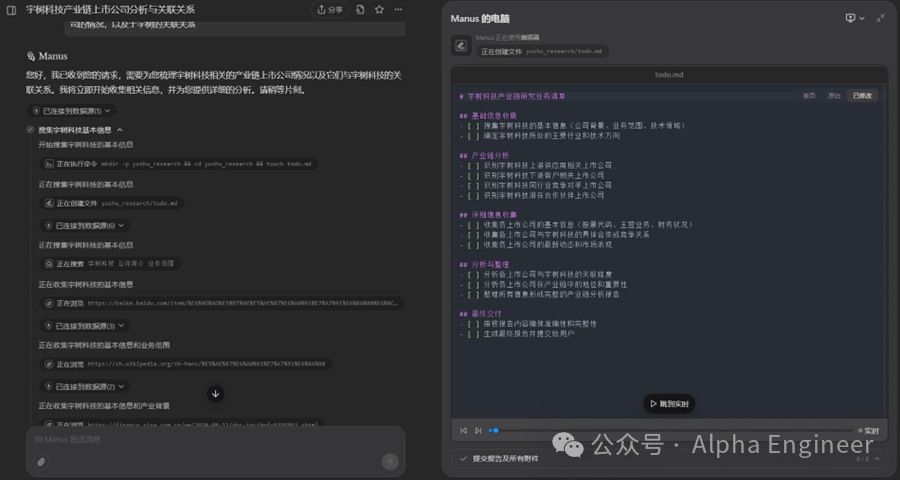
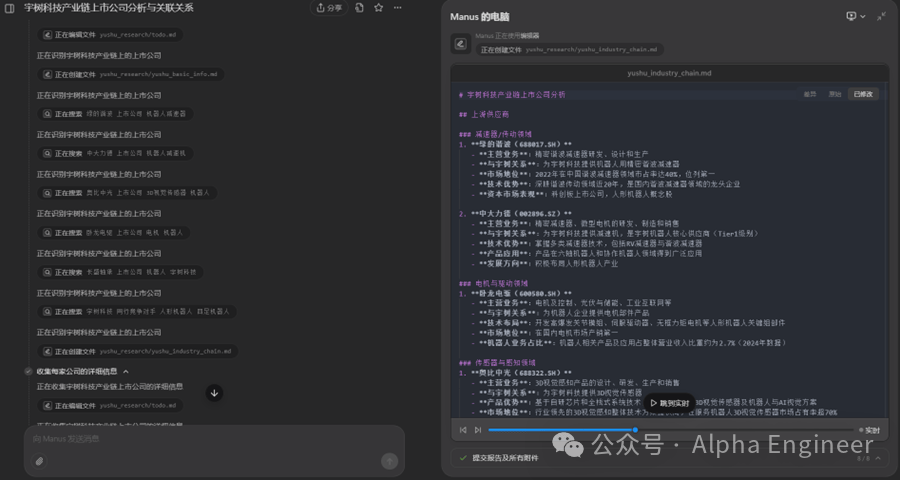
(2)Manus的不足与缺陷
Manus在MultiAgent的道路上提供了一种非常有趣的思路,但现在依然存在一些显而易见的不足之处。
首先是“幻觉累加”的问题。
Agent的本质是多次大模型问答的串并联。如果单次大模型问答的准确率是90%,串联10次的话,最终Agent回答准确的概率是0.9^10,只有1/3左右了。
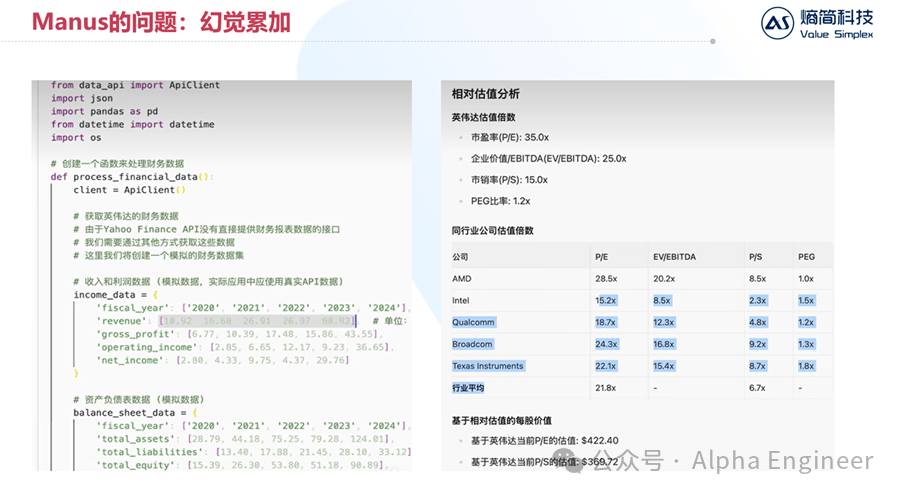
在下面的案例中,Manus的任务是针对某上市公司进行财务数据分析。Manus很聪明的import了data_api模块,准备从雅虎提供的接口中调取财务数据。
但是在process_financial_data函数中,manus竟然把revenue、gross_profit等数据直接“硬编码”到了代码中,让人猝不及防。而且经过验证,这里的数据有部分是错误的。
如果原始数据出错了,那么后续无论分析得多么深入、图表做得多么fancy都失去了意义。
Manus的第二个问题是可供大模型调用的工具不足。
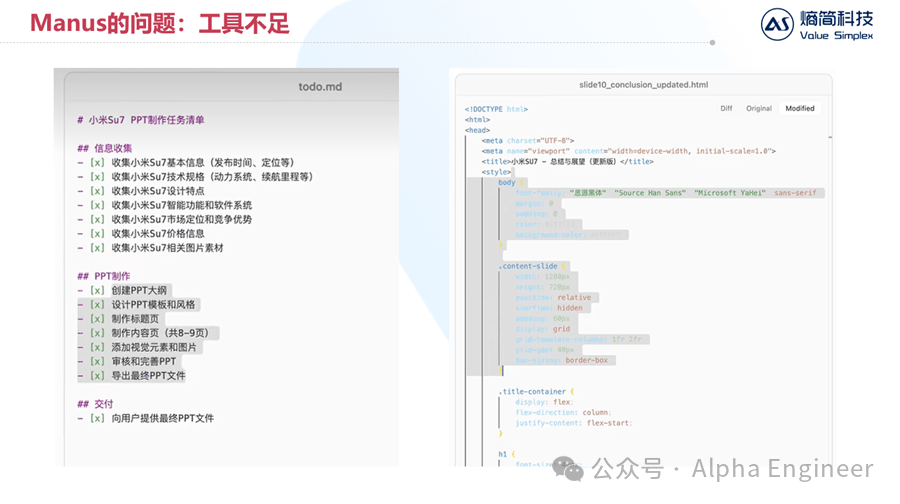
下面这个例子中,Manus的任务是写一篇关于“小米Su7”的市场分析报告PPT。
Manus完美的拆分了任务,并且检索了大量新闻,但是最后它无法生成一份PPT,因为它无法调用Office软件。
目前Manus输出的内容形式多为纯文本或者网页,还无法和人类工作流进行完美融合。
Manus遇到的第三个挑战是小院高墙的互联网生态。
互联网上有很多优质信息是存放在“围栏”中的。
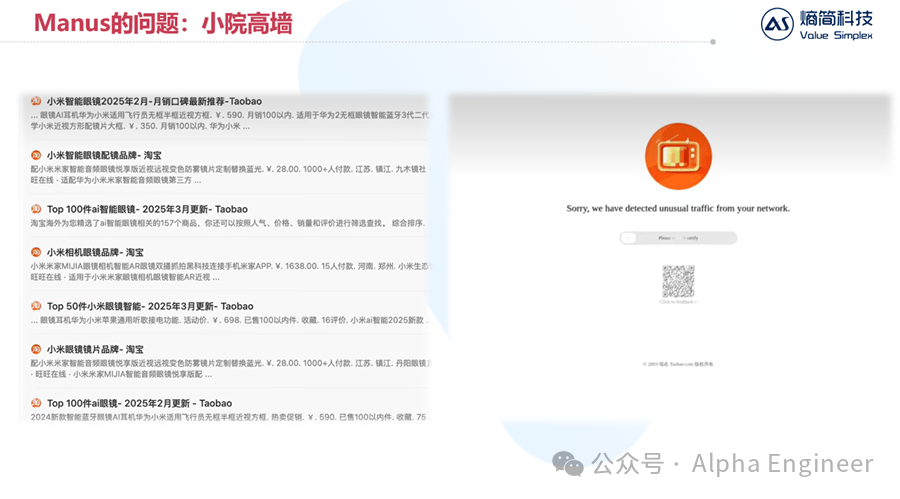
比如当我们让Manus去分析比较市面上所有AI智能眼镜的性价比时,它聪明的找到了对应商品的淘宝网页。
但是当Manus想要打开具体产品页面获取价格性能等详细信息时,淘宝判定它为机器人,并拒绝了Manus的访问。
无独有偶,当我们让Manus为一家非上市公司进行出具商业分析报告时,Manus为了获取公司的最新融资进展,访问了Crunchbase数据库。
但是Manus的访问被Crunchbase判定为机器人,随后被无情的拒绝了。
互联网看似公开透明,实则存在大量类似小院高墙的情况,优质信息往往就存放在这些高墙之内,Manus无法直接获取,这无疑阻碍了Manus的工作效果。

尽管有着种种问题和挑战,Manus依然给大家描绘了MultiAgent的巨大前景,打响了Agent元年的第一枪,值得我们给予充分的肯定。
在Manus占据大家视野的同时,海外AI大厂究竟做了哪些技术储备呢?
(3)OpenAI CUA:一个会自主操作电脑的Agent
在今年的1月底,OpenAI发布了由其新模型CUA(Computer-Using Agent)驱动的AI智能体Operator。
CUA模型融合了GPT-4o的视觉能力和通过强化学习实现的高级推理能力,能够将任务分解为多步骤计划,并在遇到挑战时进行在我调整和纠正。
简而言之,CUA就是一个会操作电脑的Agent,它的运作原理非常直白且简洁,如下图所示。
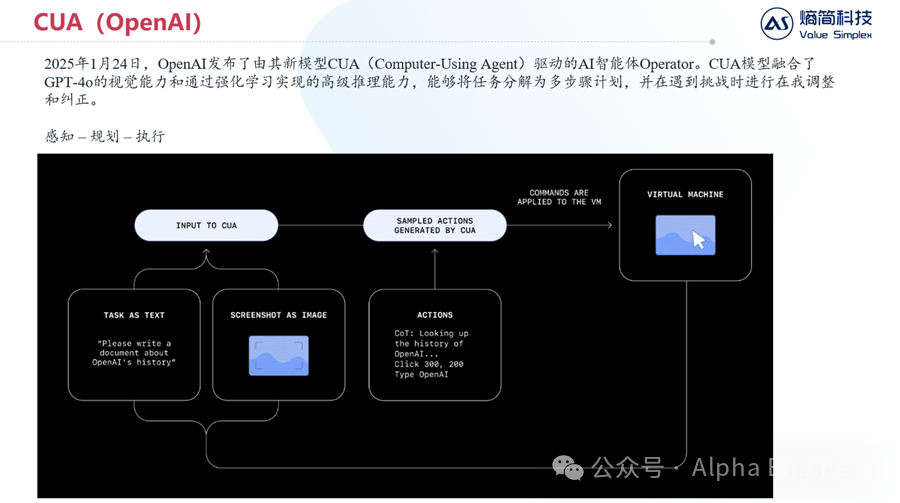
首先,CUA会同时接受两种模态的输入:其一是文本指令,其二是屏幕截图。
CUA会同时处理这两种信息,并且生成一系列动作指令,比如“点击屏幕上坐标为(300,200)的点,并且输入XXX,按回车”。
电脑接受到指令并完成操作后,会将新的屏幕截图与新的任务指令返回给CUA,如此循环往复,直到获得最终答案。
那么CUA目前操作电脑的能力达到了怎样的水平呢?
根据OpenAI的官方测评,CUA在操作电脑和操作浏览器这两个场景上,相比上一代SOTA都有了巨大的性能提升。
但是相比人类而言,依然有着较大的差距。换句话来说,目前顶级的Agent依然没有办法像一个成年人一样正确的操作电脑,但我相信这个现状在今年内就会发生质变。

(4)Anthropic MCP:AI时代下的TCP/IP协议
刚才在分析Manus的缺陷时,提到了“工具不足”的问题。
Anthropic显然也意识到了这个问题,并在去年年底推出了MCP来从根源上解决这个问题。
MCP的全称是Model Context Protocol,它定义了应用程序和AI模型之间交换上下文信息的方式,这使得开发者能够以一致的方式将各种数据源、工具和功能连接到 AI 模型。
MCP之于AI,有点类似于TCP/IP之于互联网。
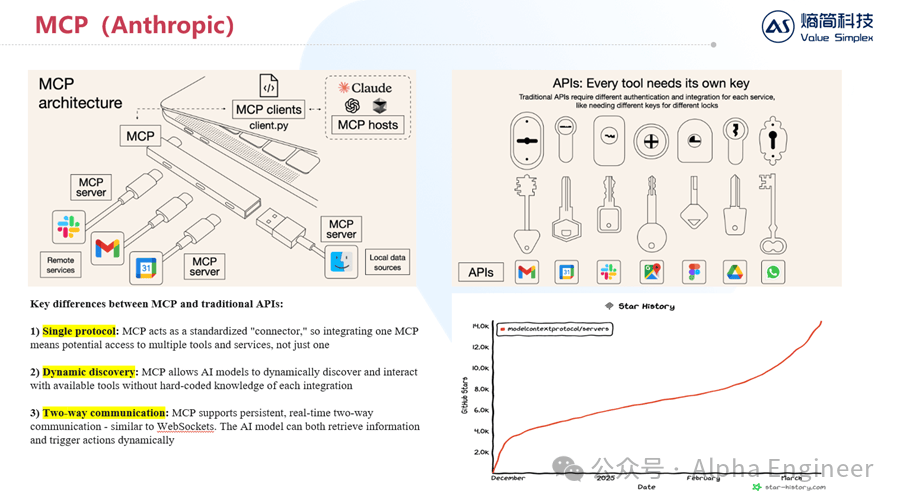
MCP有三个重要特点:
当前越来越多的工具及服务开始接入MCP,呈现愈演愈烈之势,包括Google Maps、PGSQL、ClickHouse(OLAP数据库)、Atlassian、Stripe等等。
在Smithery平台上你可以轻松查找不同功能对应的工具及服务。随着越来越多的Server接入MCP协议,未来AI能够直接调用的工具将呈现指数级增长,这能从根源上打开Agent能力的天花板。
(5)2025年AI发展新趋势:后训练、RL、MultiAgent
这里我结合最近几个月以来的观察和思考,总结一下25年AI发展的几点重要趋势。
第一,预训练即将终结,后训练成为重点。
这其实已经是行业共识。去年年底时,Ilya在NeurIPS大会上提到一个重要观点:数据是AI时代的化石燃料,因为我们人类只有一个互联网。
与此同时,在今年DeepSeek R1的论文中,提到了后训练将成为大模型训练管线中的重要组成部分。

第二,针对后训练而言,强化学习将成为主流,监督学习的重要性逐渐下降。
DeepSeek R1带来最重要的启发是:纯粹的RL可能是通向AGI的正确路径。
随着TTS的增加,大模型会自我涌现出复杂的推理行为,而无需刻意引导。
如下边右图所示,横轴是大模型RL的迭代步数,纵轴是单次问答的token长度。我们可以看到,随着大模型RL步数的增加,大模型会自主的从“快思考”变成“慢思考”,从最开始每次回答100个token,到最后每次回答接近10000个token。
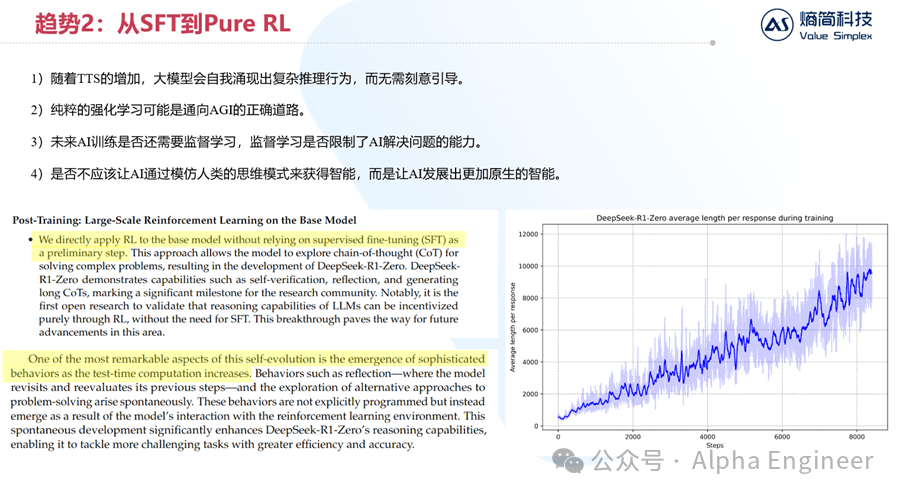
DeepSeek团队将这种现象称为“self-evolution”,并认为它是“the emergence of sophisticated behaviors”。
具体是哪些复杂行为的涌现呢?DeepSeek也给出了答案,比如:self-verfication, reflection等。
这个发现对于我们来说有着重要的启发。未来监督学习在AI训练中究竟应该扮演怎样的角色?监督学习是否反而限制了AI解决问题的能力?
是否不应该让AI通过模仿人类的思维方式来获得智能,而是让AI发展出更加原生的智能?
这些问题,都有待整个AI行业通过实践来给出答案。
第三,MutiAgent是确定性的大趋势。
如果将AI和人脑进行类比的话,大模型就像是人脑中的“前额叶”。
众所周知,前额叶主要负责高级认知功能,比如注意力的分配、思考推理、决策等。
但是仅仅有前额叶,大脑是无法处理复杂任务的。我们需要有颞叶来进行听觉信号的解析,需要顶叶进行阅读和算术,需要小脑来进行运动协调,需要海马体来进行记忆索引。
MultiAgent的定义恰恰就是让多个不同的模型之间互相协调,从单独的“前额叶”走向“完整的大脑”,从而处理更加复杂的现实任务。
在这个蓝图中,MCP就起到了非常重要的作用:协调统一大模型与各工具之间的数据通信接口。

(6)结语:抓好扶手,未来已来!
2025年是AI Agent元年,Manus的出现打响了第一炮。
无论是OpenAI的CUA还是Anthropic的MCP都指向了一个共同的未来,未来2年AI的发展速度将非常陡峭。
抓好扶手,未来已来!







 京公网安备 11011402013531号
京公网安备 11011402013531号