最近,一款名为Manus的产品颇受争议。
Manus是什么,它怎么突然就火了?从官网展示的demo来看,Manus主打的是针对某场景的实际应用,比如可以深度体验产品并制作调研报告,再比如可以批量处理面试简历并打分排名。

图源:Manus官网
先不管Manus的争议如何,它的出现能导致刷屏,正好说明了AI领域的一个新趋势:AI的发展不再盲目追求规模,而是开始深入挖掘实际价值。
无独有偶,Manus智能体横空出世后,OpenAI紧跟放大招,推出开发者工具链简化智能体开发,帮助开发人员和企业构建有用且可靠的AI智能体。OpenAI首席产品官凯文威尔直言:“2025年将是智能体真正发挥作用的一年。到2025年,ChatGPT将开始在现实世界中为你做事。”
这也让我们看到了AI领域的一个根本性变化:过去AI追求通用的广泛能力,现在则更聚焦于在特定垂直领域解决具体问题。
AI领域重心出现转移,市场开始聚焦垂类应用
这个发展路径并不意外,从历史上看,科技行业的变革往往遵循一定的阶段性规律。以互联网时代为例,最初是那些“赋能者”受益,比如半导体公司,然后进入基础设施的层面,包括云计算、设备和电力供应相关的企业,最后才是应用和服务层面,比如抖音、微信、美团等,大部分的价值都会在应用推广后释放出来。
这个思路放在AI时代同样适用,通用大模型建立了基础设施,最后真正实现AI价值的,是基于通用大模型所衍生出来的垂类模型。
有两个场景可以充分证明,一是医疗行业,二是翻译行业。
虽然人工智能已经落地医疗多场景,但当前医学领域的专用垂类模型和以DeepSeek为代表的通用大模型还有很大区别。以药物研发为例,据新华财经报道,多家生物医药企业表示,当前通用大模型对药物研发的直接赋能仍然有限。
药物研发目前还是依靠垂类模型。通用模型和垂类模型的差别主要取决于两个方面,一个是训练数据源的差异,另一个是反馈机制的差异。通用模型可用数据是庞大的、易获得的;专有模型训练用的数据是有较高质量要求的、精准的。
再以AI翻译市场为例,不可否认的是,对于文字转译这种简单翻译需求,其实大模型都能满足,但具有专业难度、容错率低的翻译需求,却往往会让我们对大模型持更大的怀疑态度,在准确性、专业性、安全合规性上,试错成本太高,因此最后还是要求助专业工具。
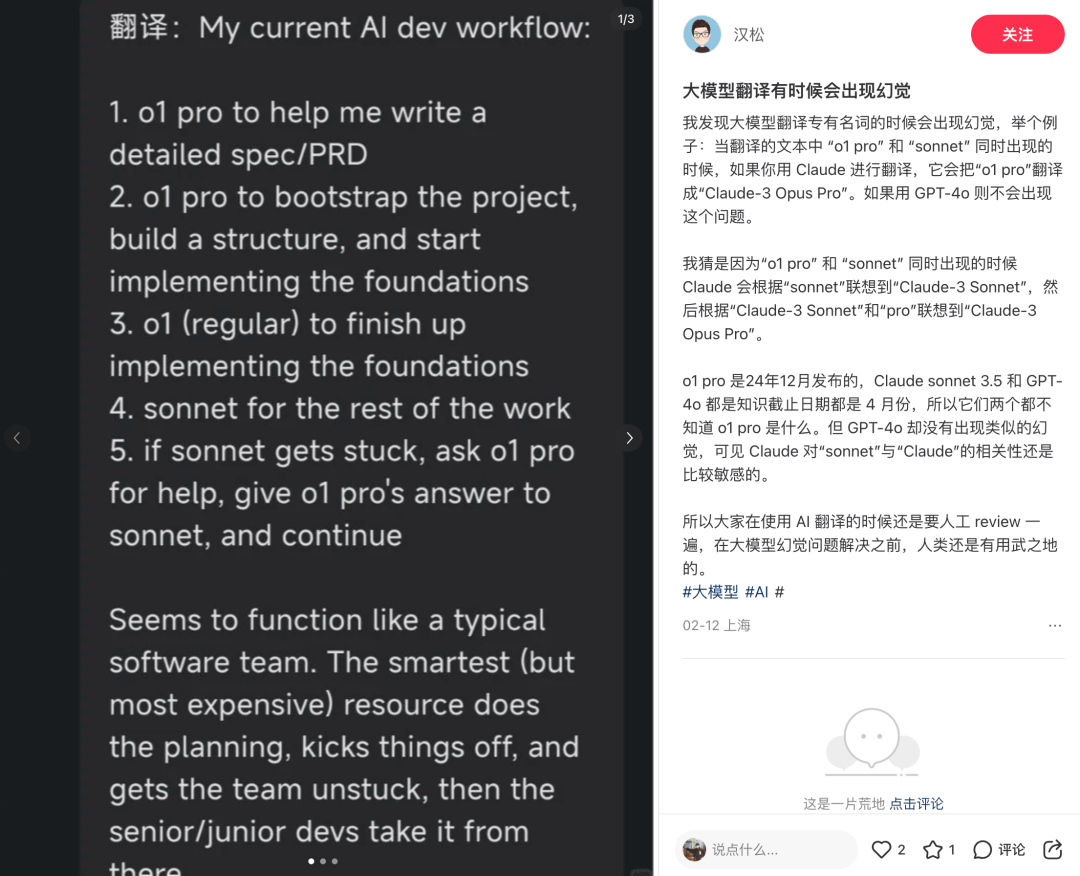
即便强如DeepSeek,有时候也会在回答结果上进行“思维涌现”,可能会出现在文字上生造概念,堆叠名词,滥用修辞的现象。简单来说就是会画蛇添足。这种自作主张对某个词语的“优化”,在专业场景中具有致命性,特别是在重要场合,或者医药翻译上,错误代价太高。
而且,DeepSeek有时候存在胡编乱造的可能,比如最典型的是在举例的时候,很容易自己异想天开。比如以下例子,着实让人贻笑大方。

图源:DeepSeek
在需要精准度的专业领域,通用大模型其引以为傲的"涌现能力"反而成为风险源头。当技术进入实际产业应用阶段时,建立精准的数据和场景适配,比单纯增加模型参数更有意义。
因此现在我们能够看到的一大趋势就是,2025年市场的焦点转向垂类AI应用。
专业工具想要拥抱AI,垂类模型是最好的选择
如果说2024年的主角是通用大模型,那2025年的主角绝对是小参数的垂类模型。
当业界还在热议 DeepSeek-R1 开源战略对 AI 生态的重构、持续探讨 Manus 智能 Agent 的技术突破时,国产大模型已在垂直赛道实现关键性跨越。
3 月 11 日,网易有道宣布完成翻译底层技术迭代,基于自主研发的子曰翻译大模型 2.0,在测试中实现翻译质量超越国内外主流通用大模型,达行业第一。
我们也实测了一下,发现在很多专业领域的翻译中,有道大模型翻译确实领先于市面上主流的通用大模型。
比如两者分别输入:“After the 52-week trial period, patients entered a 12-week follow-up safety period during which they were no longer receiving dupilumab or placebo。”对比其翻译结果。


可以看到,DeepSeek无法将“dupilumab”进行本土化翻译,仍是以英文的方式呈现,而有道词典则是准确将“dupilumab”翻译为度普利尤单抗。
另外,DeepSeek把“trial period”翻译成了“治疗期”,而正确的翻译应该是有道词典的“试验期”。
我不确定在医疗场景下,“治疗期”与“试验期”的差别是什么,但仅从语义来看,两者显然会让非医学专业的同学产生误会。
类似的例子还有很多,比如曾有通用大模型将临床试验报告中的"placebo effect"(安慰剂效应)误译为"愉悦效应",仲裁案中,法律文件里的"force majeure"(不可抗力)被译成"主要力量";再比如某并购协议中的“joint and several liability”(连带责任)被翻译为“联合与单独责任”,引发合同双方对责任范围的重大误解,最终需人工律师介入修正。
图源:小红书
之所以有道大模型翻译的质量能做到比主流通用大模型高,背后就是垂类大模型的驱动。
2023年7月,网易有道推出国内首个教育大模型“子曰”,“子曰”大模型从一开始就定位为是一个“场景为先”的教育垂类大模型,相比于通用大模型,教育垂类大模型子曰拥有更专业的预训练语料,可以满足用户在不同场景下的学习需求。
目前子曰翻译大模型已经来到了2.0阶段,这背后,有道从数据、算法和效果评估三个核心环节入手,进行了全面的优化和升级。
在数据层面,有道精心收集了并严格清洗了数千万高质量的翻译数据,并由英语专八认证人员及职业译员组成的专家团队进行多维度人工标注,保证训练数据的高质量。极大丰富了数据资源库,让模型在多样化翻译场景中游刃有余。
在算法层面,有道子曰翻译大模型实现了两大技术突破,分别是大模型融合与online DPO。
简单来说,大模型融合就是像“专家会诊”一样翻译,相当于有道子曰翻译大模型如同组建了“全科专家团”。使用大模型融合技术,通过结合不同大模型的优势来避免灾难性遗忘现象,确保模型在保持翻译能力的同时,也不失综合能力。
而online DPO则可以理解成翻译界的"养成计划",每次训练生成一优一劣两个译文,让模型学习更高质量的译文,通过3轮对比淘汰机制强化模型的判断力,自动标注翻译偏好数据。经过海选→晋级→决赛三轮严格筛选,最终留下的都是"全能翻译"。
在评估层面,有道团队人工标注了覆盖各个领域的开发集和盲测集,严格确保了测试数据的全面性和代表性。对算法团队所使用的开发集和盲测数据集实行严格分离、相互独立,以确保评估的客观性与准确性,模型最终效果以盲测集效果为准。
在自动评估方面,有道不仅使用行业通用的Comet指标,还自主研发了更精准的大模型评估工具,进一步提升了翻译质量检测的可靠性。同时设计并执行了更完善的人工评估方案,从多维度对模型的翻译结果进行细致地分析和评价。
正是通过这三个层面的全方位优化与升级,有道用一个小参数模型就能实现超越通用大模型的翻译质量。而这样的故事,在2025年还会涌现更多。
AI的价值,在于解决了多少实际问题
科技发展的核心就是解决问题。现在大家越来越清楚:到2025年,各种专业领域的AI工具会迎来大爆发。
根据市场研究机构MarketsandMarkets的最新报告,垂类AI应用的市场规模预计将从去年51亿美元大幅扩张至2030年的大约471亿美元,到2032年还可能超过1000亿美元。
在这样的大背景下,以有道为代表的专业翻译工具具有标杆意义。这场垂类AI革命给予行业的最大启示,或许在于对技术本质的重新认知:AI的价值不在于参数多少,而在于解决了多少实际问题。
当科技巨头还在为"万亿俱乐部"的门票厮杀时,那些在垂直领域默默耕耘的“有道”们,正在用更精巧的模型、更专注的投入,撬动百倍于通用模型的实际价值。这种"少即是多"的策略,或许才是穿越AI时代的真正指南针。
站在2025年的技术分水岭回望,我们会发现一个有趣的现象:当通用大模型试图用规模征服世界时,专业工具正在用深度重新定义边界。其中,有道大模型翻译就是一个将AI与实际应用结合的极佳典范。
这不仅是技术的胜利,更是对产业规律最深刻的敬畏:在任何领域,专业主义永远是不可替代的稀缺品。







 京公网安备 11011402013531号
京公网安备 11011402013531号