
为向行业提供真实、可验证的推理性能,软硬协同算力解决方案提供商毅伯智算,近日向市场全新推出搭载满血版DeepSeek-R1-671B的8卡推理一体机TORA3000,其推理性能相比英伟达H20-141G高出四成,达到业界领先水平,并且实现了硬件、组网、功耗的综合成本最优。
毅伯智算是国内少有的实现全栈自研的软硬协同算力解决方案提供商,团队凝聚了超百人的AI工程师,其中核心成员在人工智能与超算领域拥有超10年的研发经验。过去三年,团队始终致力于全栈式AI训推平台的研发,并于2024年依托新组建的毅伯智算主体,推出了全栈式AI训推平台。2025年3月,毅伯智算进一步推出搭载DeepSeek模型的自研8卡推理一体机TORA3000。
TORA3000是软硬件一体化解决方案,开箱即用,全面满足客户推理需求。毅伯智算凭借其软硬件一体化的综合优势,提供最具性价比的一体机解决方案,1机8卡即能实现上述性能,显著降低客户硬件成本,原生支持 DeepSeek-R1-671B 所采用的FP8 精度,兼容FP64/32/16 及INT8,在保证推理精度的同时有效降低部署成本,通过全自研的算子库、编译技术、推理框架等技术手段,实现更快计算效率、长文本和高并发请求支持、更高推理性能。
对于企业用户来说,Deepseek推理一体机选择满血版还是蒸馏版?本质上,满血版与蒸馏版类似于教师和学生的关系,即前者是知识输出者,后者通过知识蒸馏过程继承前者的知识。在实际应用中,满血版可深度处理代码生成、知识图谱构建等高复杂度任务;而蒸馏版作为学生模型,受限于知识压缩与固定架构,仅适用于应用特别定义且相对简单场景。对于大中型企业,至少需配置满血版一体机作为核心引擎,以支撑业务迭代与高密度推理需求。
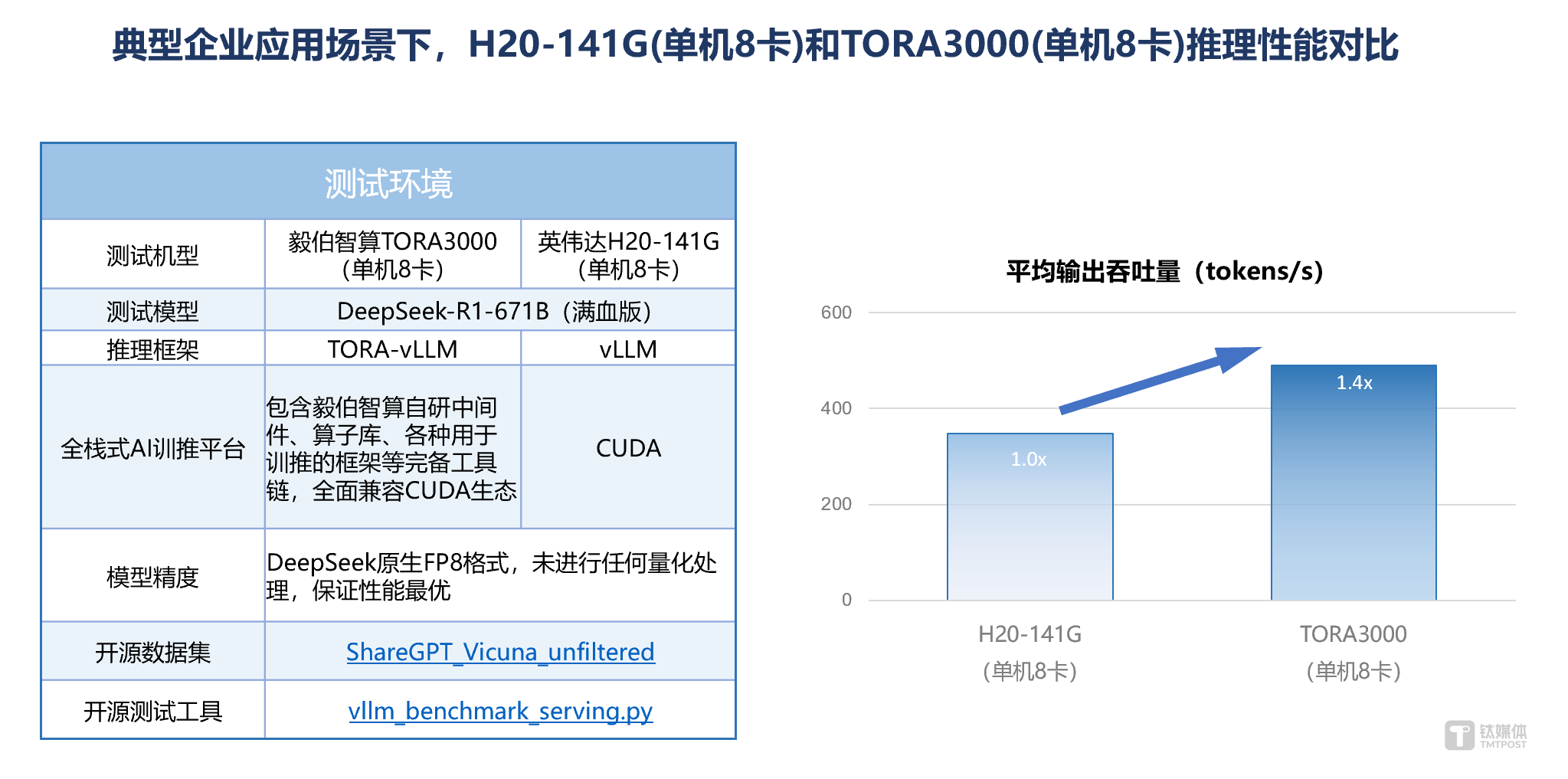
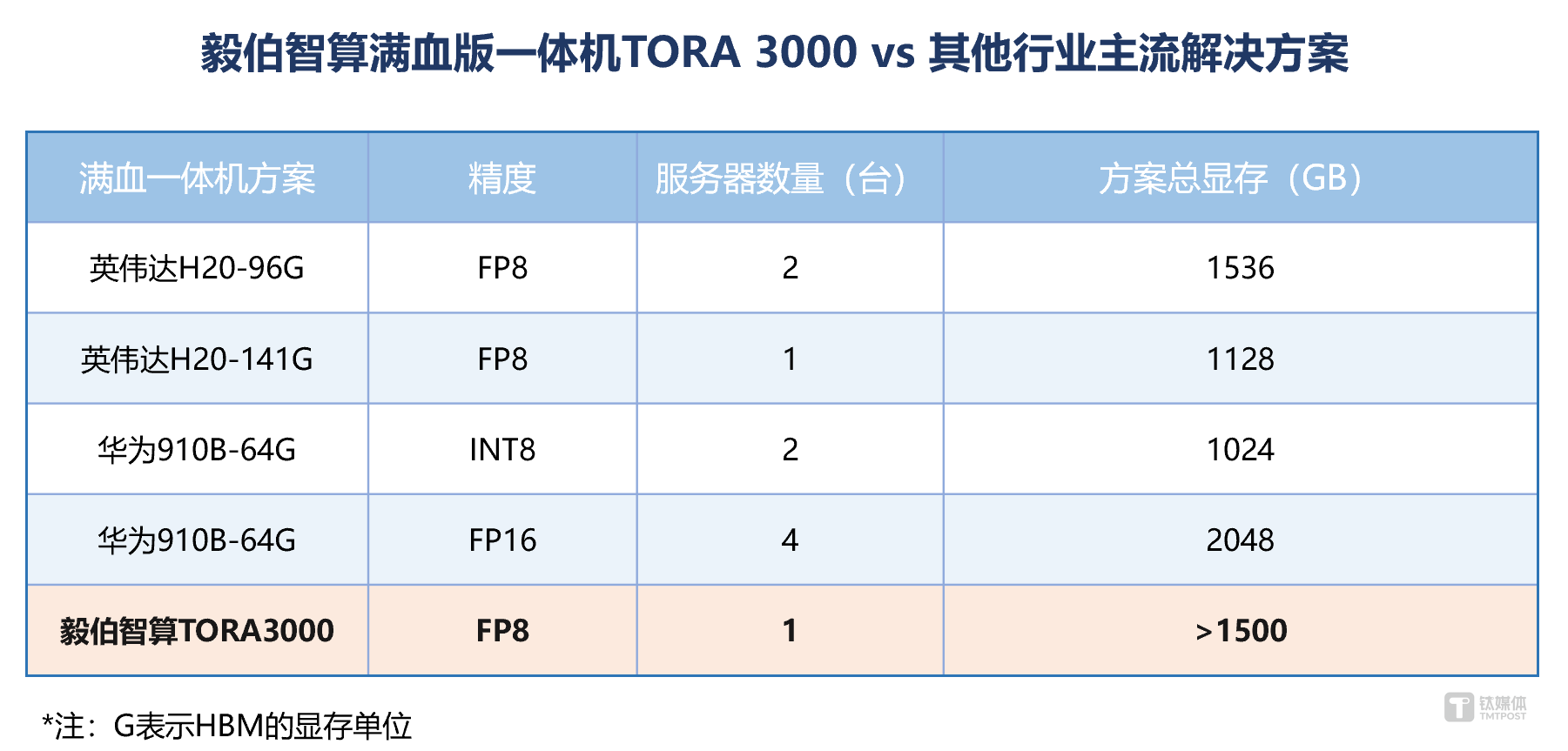
受GPU硬件性能的限制,市场上满血版推理一体机存在单机、双机甚至四机等多种部署方案,但是双机方案相对单机方案的硬件成本和功耗会都会翻倍,四机则更高,并增加额外的组网和运维成本。在Deepseek原生FP8精度下,一体机(8卡)要流畅运行满血模型,单卡显存需大于120G(整机显存大于1000GB),显存不足则必须采用多机部署。同时,部分GPU不支持FP8运算,只能量化为INT8或FP16模型,但INT8精度下,推理精度会所有下降,FP16会导致所需显存和节点数量翻倍。为降低部署成本、简化部署复杂性并保证性能,1台标准8卡服务器上部署原生FP8精度的DeepSeek-R1-671B模型是最优选择,但此方案要求GPU支持FP8精度且单卡显存超过120GB,而目前市场上仅有毅伯智算的TORA3000和英伟达H20-141G可以满足。经采用开源数据集和开源测试工具对两者推理性能进行测试发现,毅伯智算的TORA3000相比英伟达H20-141G,性能提升达40%,达到业界领先水平。








 京公网安备 11011402013531号
京公网安备 11011402013531号