
报道
编辑:犀牛 好困
谷歌DeepMind推出了Gemini Robotics和Gemini Robotics-ER两款AI模型,基于Gemini 2.0打造,这对「机器人大脑」在泛化能力、交互性和灵巧性上全面突破,让机器人能理解复杂环境、执行精细任务,甚至适配各种形态。
就在昨天,谷歌DeepMind推出了新一代专为机器人设计的AI模型。
一口气推出了两款:Gemini Robotics和Gemini Robotics-ER。
这两款模型都是基于Gemini 2.0,其中Gemini Robotics-ER能利用Gemini的具身推理(ER)能力。

博客地址:https://deepmind.google/discover/blog/gemini-robotics-brings-ai-into-the-physical-world/
谷歌DeepMind在X上放出了许多演示视频。
Gemini Robotics可以解决需要高度灵巧性的多步骤任务,例如折纸、打包饭盒等。
下图一台双臂机器人通过两只手臂的配合折纸,不仅动作要求精细,配合的默契程度更是有很高的要求。

除了折纸,替人把饭盒装到包里也不在话下。
看来再配个炒菜机器人,我们距离不用自己做饭真的不远了。

除了Gemini Robotics自己表演,DeepMind团队也整了点活,他们与机器人比赛,看谁能更好地把皮带安装到齿轮上。
这项挑战对于力量有要求,人类选手要完成都有难度,但Gemini Robotics机器人可以在两只手臂的配合下熟练安装,完胜人类。

为了使机器人能够与人类更好地进行交互,当它被中断或情况变化时,Gemini Robotics可以即时调整其行为。
这种可控性将使Gemini Robotics机器人能够更好地在未来与家庭、工作场所乃至更广泛的机器人助手合作。
下方演示中可以看到,机器人在拾取葡萄时不仅懂得要轻拿葡萄,不能太用力将其捏爆,还能在餐盒不断变换位置时准确地重新定位。
可见其不仅操作精细,更是具备了很高的推理能力。
真是挺厉害的。
Gemini Robotics机器人还完成了训练中未曾出现过的任务,展现了泛化到新场景的能力。
在综合泛化基准测试中,Gemini Robotics的性能平均比其他最先进的视觉-语言-动作模型提高一倍以上。
例如,在学习了将葡萄放进餐盒中后,研究团队让其将笔放进笔盒中。
在没有做相同情况的训练下,机器人通过自己的泛化能力就完成了这个任务。

当然,像「灌篮」这种操作对于Gemini Robotics基本就没啥难度了。

除了Gemini Robotics模型,DeepMind还一同推出了更智能的Gemini Robotics-ER,允许机器人利用Gemini的具身推理能力。
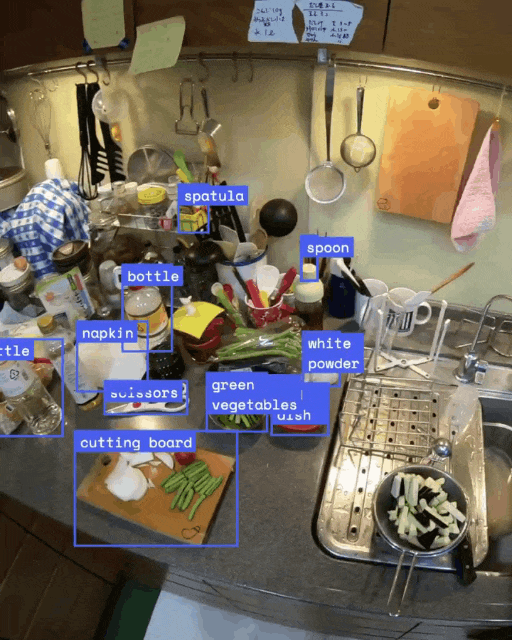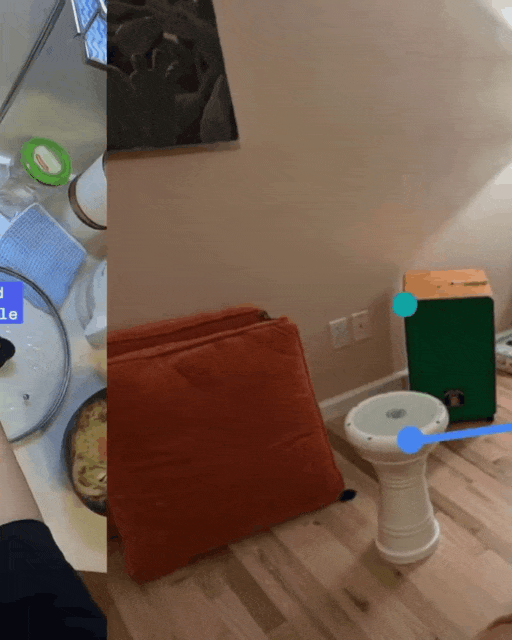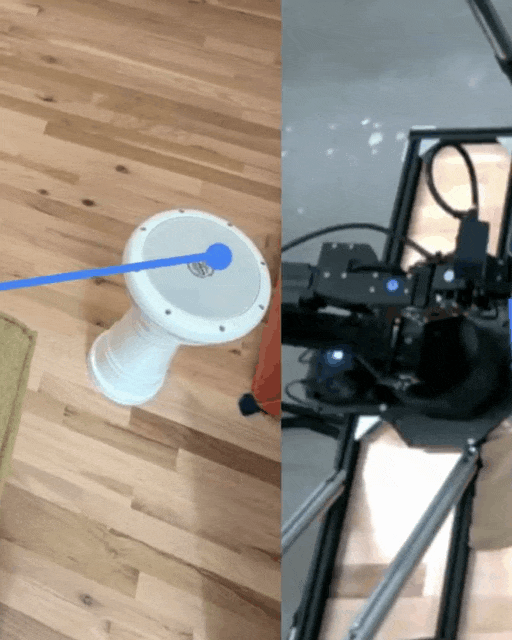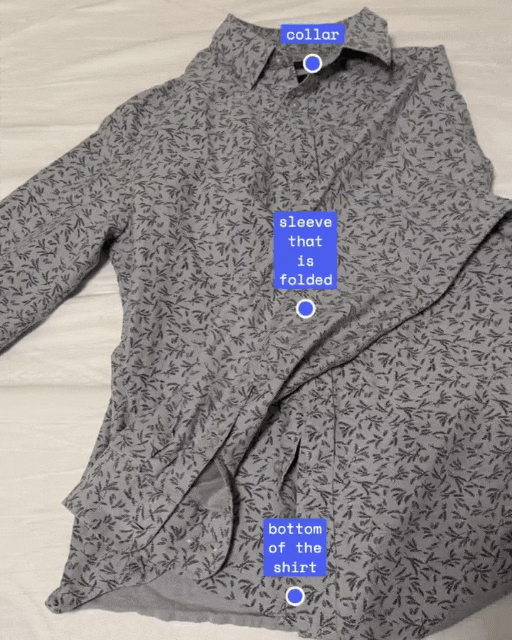
比如说,如果一个机器人看到一个咖啡杯,它能识别出来,然后用「指向」功能找到可以互动的部分——比如杯把——还能认出捡起来时要避开的东西。
DeepMind称自己最终目标是开发适用于任何品牌机器人的AI模型,无论其形状或大小。这包括双臂平台,如ALOHA 2和Franka,但同时也适用于更复杂的实现,例如Apptronik开发的Apollo。
基于Gemini 2.0的机器人模型
Google DeepMind一直在研究如何让Gemini模型通过文字、图片、音频和视频的多模态推理来解决复杂问题。
但到目前为止,这些能力还主要局限在数字世界里。
但要让AI在现实世界中真正帮到人,它得展现出「具身」推理——也就是像人一样理解周围世界并做出反应,还要能安全地采取动作把事情搞定。
就在昨天,DeepMind推出了两款基于Gemini 2.0的全新AI模型,为新一代实用机器人打下基础。

第一款是Gemini Robotics,一个高级的视觉-语言-动作(VLA)模型。
它在Gemini 2.0的基础上增加了物理动作作为新的输出方式,可以直接控制机器人。
第二款是Gemini Robotics-ER,一个拥有高级空间理解能力的Gemini模型,让机器人专家能利用Gemini的具身推理(ER)能力运行自己的程序。
这两款模型让各种机器人能完成比以往更多的现实任务。
谷歌DeepMind最强视觉-语言-动作模型
要让机器人用的AI模型真正帮到人,它得具备三个关键特质:
泛化性:能适应各种情况
互动性:能快速理解并回应指令或环境变化
灵活性:能像人一样用手完成精细操作,比如小心地拿东西
虽然DeepMind之前的研究在这几方面已有进展,但Gemini Robotics在以上三点上都大幅提升了表现,让我们离真正的「全能机器人」更近了一步。
泛化性
Gemini Robotics利用Gemini对世界的理解,能适应新情况,解决各种没见过的新任务。
它还擅长处理新物体、多样的指令和陌生环境。
在DeepMind的技术报告中,Gemini Robotics在泛化性基准测试上的表现比其他顶尖视觉-语言-动作模型平均高出一倍多。
互动性
要在动态的现实世界里工作,机器人得能跟人和周围环境无缝互动,还得随时适应变化。
Gemini Robotics建立在Gemini 2.0的基础上,天生就很会「聊天」。
它能理解日常对话语言的指令(还能用不同语言),比之前的模型能处理的自然语言范围广多了。你说什么它都能调整自己的行为。
它还会持续观察周围,察觉环境或指令的变化,然后调整动作。
这种「可控性」能让人跟机器人在家里或职场上更好地合作。
灵活性
打造实用机器人的第三个关键是动作灵活性。
人类轻松完成的日常任务往往需要很精细的动作技能,但对机器人来说却很难。
而Gemini Robotics能搞定超级复杂的多步骤任务,比如折纸或把零食装进密封袋。
多形态适应
最后,因为机器人形态各异,Gemini Robotics被设计成能轻松适配不同类型的机器人。
他们主要用双臂机器人平台ALOHA 2的数据训练它,但也证明了它可以基于许多学术实验室中使用的Franka手臂来控制双臂平台。
它还能针对更复杂的形态(比如Apptronik开发的Apollo人形机器人)进行优化,完成现实任务。

Gemini Robotics致力于研究不同类型的机器人
增强Gemini的世界理解
除了Gemini Robotics,DeepMind还推出了一款高级视觉-语言模型Gemini Robotics-ER(ER是「具身推理」的缩写)。这个模型提升了Gemini对世界的理解,尤其是空间推理能力,让机器人专家能把它跟现有的低级控制器结合使用。
Gemini Robotics-ER大幅改进了Gemini 2.0的指物和3D检测能力。结合空间推理和Gemini的编程能力,它能即兴创造新功能。
比如,看到一个咖啡杯,它能自己判断用两指抓手柄合适,还能规划安全的接近路径。
Gemini Robotics-ER开箱即用就能控制机器人,涵盖感知、状态估计、空间理解、规划和代码生成等所有步骤。
在这种端到端的设置下,它的成功率比Gemini 2.0高出2-3倍。
如果生成代码不够用,Gemini Robotics-ER甚至可以通过少量人类示范的模式进行「上下文学习」,找到解决方案。

Gemini Robotics-ER擅长具身推理能力,包括检测物体和指向物体部位、查找相应的点和检测3D物体
参考资料:
https://x.com/GoogleDeepMind/status/1899839624068907335 https://www.theverge.com/news/628021/google-deepmind-gemini-robotics-ai-models








 京公网安备 11011402013531号
京公网安备 11011402013531号