
决定产业未来的关键因素并非只是技术创新本身,更在于谁能够以更低成本、更高效率实现创新扩散,真正将 AI 的潜力转化为企业和社会发展的实际生产力。
DeepSeek 点燃了 " 引线 " 后,大模型再一次进入到了 " 爆发期 "。
短短一个多月里,大模型的能力上限不断被刷新," 落地 " 已然成为产业上下游的普遍共识。
在这样的局面下,一家企业最佳的生态位是什么呢?
上世纪 90 年代,杰弗里 · 摩尔在深入研究了埃弗雷特 · 罗杰斯的 " 创新扩散理论 " 后,在《跨越鸿沟》将 " 技术采用生命周期 " 的客户群体分成了五类,分别是创新者、早期采用者、早期大众、后期大众和落后者。
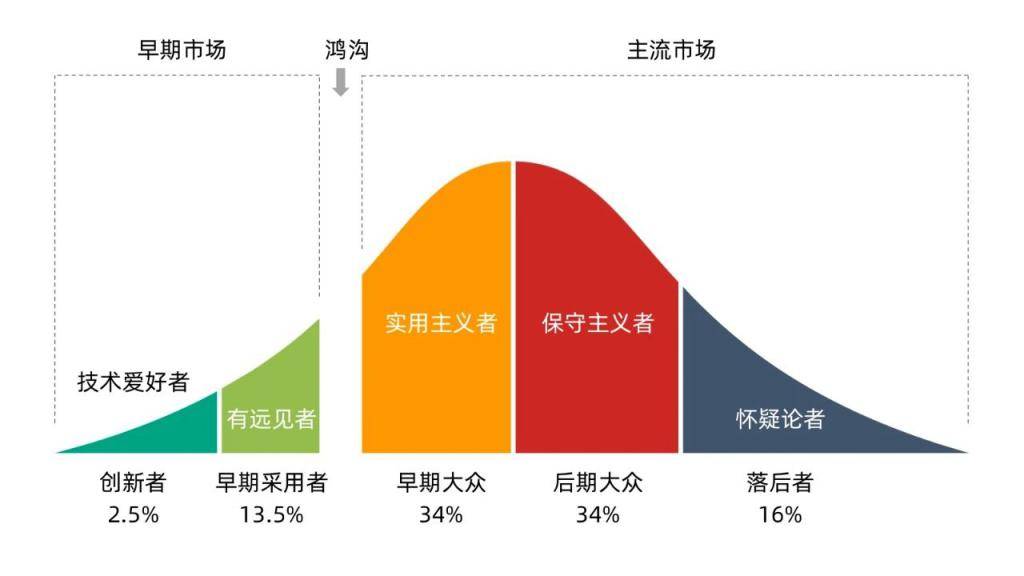
对号入座的话,大模型正处于从早期采用者向早期多数过渡的阶段,也就是 " 鸿沟 " 所在的阶段。
由此来审视这轮大模型浪潮,相较于模型层的你追我赶,一场更重要的博弈在于怎么将创新迅速 " 扩散 " 到产业中,支撑创新应用的落地。
01.
跨越算力鸿沟:一场 " 双螺旋 " 竞赛
DeepSeek 意外 " 出圈 " 后,在流量洪峰的冲击下一度陷入了 " 崩溃循环 ",直到半个多月后才走出 " 服务器繁忙 "。
一些想要接住 DeepSeek 流量的第三方 MaaS 平台,则在月亏 4 亿的压力下,无奈关闭了相关推理服务。
这些现象指向了同一个原因——算力瓶颈。
算力供应的不稳定,即便是 DeepSeek 这样的团队,也无法在短时间里填补缺口;而算力价格的居高不下,不单单束缚了千万使用者的手脚,MaaS 平台也深感压力山大。
大模型想要落地到千行万业,让 " 智力 " 转化为实实在在的生产力,首先要打破算力瓶颈。大模型创新扩散的鸿沟,很大程度上属于算力鸿沟,只有打破了算力瓶颈,才能创新的扩散铺平道路。
就在 DeepSeek 走红的同一时间,百度智能云对外宣布——在百舸 4.0 的能力加持下,成功点亮昆仑芯三代万卡集群。
如果说 DeepSeek 给出了模型训练的新思路,百舸 4.0 给出了跨越算力鸿沟的新解法:通过覆盖大模型落地全流程的算力平台,让用户能够高效率、低成本使用算力。

训练大模型的第一步是创建集群。许多人不知道的是,GPU 集群需要大量复杂、琐碎的配置和调试,通常需要几周时间。但基于百舸 4.0 创建集群,只需要 1 小时就可以跑起来。
完成创建集群后,真正的考验才刚开始,因为集群的规模越大,出故障的概率就越高,运维的复杂性急剧增加。例如 meta 训练 Llama3 时用了 1.6 万张 GPU 的集群,平均每 3 小时就会出一次故障。同样是万卡任务,百舸 4.0 可以保障有效训练时长占比达到 99.5%,远高于行业内公布的相关指标。
大模型训练既要稳定,也要效率。训练千亿、万亿参数的模型,动辄需要几周到几个月的时间。百舸 4.0 在集群设计、任务调度、并行策略、显存优化等方面进行了大量优化,最终让端到端的性能提升了 30%。
同时不应该忽略的,还有百舸 4.0 的多芯混训、多芯适配能力。能够把同一厂商不同代际芯片、不同厂商的芯片统一管理,混布成一个集群高效完成模型的训练和推理任务。
按照百度智能云官方公布的数据:在万卡规模上,百舸 4.0 将两种芯片混合训练的效率折损控制在了 5% 以内;某金融机构在百舸的支持下,完成了不同型号 GPU 资源的部署、上线,有力保障了 6000 多次训练任务。
古代打仗讲求 " 兵马未动粮草先行 ",放到大模型产业同样适用,其中的算力就是 " 粮草 "。想要大模型深入落地到千行万业,势必要开启一场追求高效率和低成本的 " 双螺旋 " 竞赛。
可以找到的一个实战案例是:春节假期结束时,有近 20 家芯片企业在忙着适配 DeepSeek,在百舸 4.0 的赋能下,百度的昆仑芯是国内率先支持单机部署满血版 DeepSeekR1 的芯片,单机 8 卡配置便可实现 2437tokens/s 吞吐,并给出了业内最低的价格。
02.
吹响落地号角,工程能力见真章
和每次产业革命初期一样,创新的扩散始于 " 早期采用者 ",往往是创新意识比较明确且有能力进行智能化转型的大中型企业。
某种程度上说,大中型企业的选择,更能折射出真实的市场需求,更能从中洞察到创新的方向。
曾有媒体统计了 "2024 全年大模型相关中标项目 ",一共有 910 个项目,中标金额约为 25.2 亿元。其中百度智能云斩获了 55 个项目,中标金额 3.4 亿元,在能源、政务、金融等行业的中标数量位于所有厂商第一。
到了 2025 年 1 月,公开数据统计到的大模型相关中标项目数量已经达到 125 个,项目金额为 12.67 亿元。百度
智能云实现了中标项目数量和中标金额上的双第一,中标金额 4.17 亿元,占到了全行业的三分之一。
为什么会出现这样的局面?
国际权威咨询机构弗若斯特沙利文进行了深入的市场调研后,在《2024 年中国大模型行业应用优秀案例白皮书》给出了解释:企业用户在大模型落地的主要需求点包含完善的落地指导、先进的产品架构、全面的安全治理以及开放的生态支持,百度智能云代表的 AI 云厂商在技术生态、行业经验和服务能力方面具备显著优势,能够以高效率、低成本的方式加速大模型的推广与行业应用。
原因依然离不开 " 高效率和低成本 "。
进一步从技术层面剖析的话,和百度智能云的全栈 AI 技术能力不无关系。
百度是国内为数不多同时深耕芯片、框架、模型、应用的企业,能够针对大模型的训推、部署和调优等进行全流程优化。比如昆仑芯三代万卡集群,在行业内率先验证了可以通过模型优化、并行策略、有效训练率提升、动态资源分配等手段,将训练、微调、推理任务混合部署,进而最大化提升集群综合利用率,降低单位算力成本的可行性。
在大模型进入全球视野的第四年,早已形成了两个战场:第一个战场是大模型训练,第二个战场是大模型落地。
特别是在 " 百模大战 " 格局瓦解,大模型的牌桌上仅剩下百度、阿里、DeepSeek、智谱等少数玩家后,越来越多企业将注意力集中到了应用层,思考怎么将技术可能性转化为稳定生产力,讨论如何通过标准化流程、工具链支撑和全生命周期管理,解决大模型开发与部署中的效率、成本和质量矛盾。
在百度智能云的示范下,云厂商竞赛的升维已然是可以预见的结果,倒逼全行业提升工程能力,从底层芯片、智算平台、大模型等多个维度进行布局,推进全栈创新与快速迭代。
也就是说,落地应用的号角吹响后,竞争的天平进一步向 " 扩散 " 倾斜,不单单是算力之争、模型之争,而是工程能力的比拼:谁能借助系统性的技术体系和方法论降低成本、提升大模型落地易用性、帮助企业更好地构建 AI 原生应用,谁才有机会成为最后的赢家。
03.
长跑才刚开始,算力仍是重头戏
按照 " 创新扩散理论 ",一旦跨越了从早期采用者到早期大众扩散的 " 鸿沟 ",市场将会进入到高速增长阶段。
2024 年被公认是大模型推理应用的元年,2025 年注定是落地生花的一年,从央国企先行逐渐演变成一股不可逆的产业浪潮。对算力的需求,将呈现出指数级的增长态势。
折射到 AI 基础设施的布局上,点亮昆仑芯三代万卡集群的百度智能云并未停下来,还将进一步点亮 3 万卡集群。百度集团执行副总裁、百度智能云事业群总裁沈抖曾公开表示:" 百舸 4.0 正是为部署 10 万卡大规模集群而设计的,目前已经具备了成熟的 10 万卡集群部署和管理能力。"
不只是百度智能云,国外的 xAI、meta、OpenAI 等都在积极布局 10 万卡乃至更大规模的智算集群。
个中原因并不难理解。
一方面,大模型的 Scaling Law 仍在继续,大模型竞赛本质依然是算力竞赛,能否解决跨地域部署、多芯混训以及集群稳定性等问题,关系着是否能满足源源不断的算力需求,是否有参与大模型竞赛的资格。
另一方面,比创新更重要的,是创新的扩散。大模型赋能千行万业的过程中,需要根据不同企业的需求动态分配计算资源,提高资源利用率的同时,降低云服务的成本,10 万卡乃至更大规模的集群至关重要。
参考每次工业革命的时间跨度,大模型的产业竞赛,更像是一场考验耐力的马拉松。擅长耐力赛的百度,正以一种兼顾技术创新与产业落地的独特节奏,稳步推动大模型从创新走向产业应用。
正如 World Governments Summit 2025 峰会上的一幕,当阿联酋 AI 部长奥马尔询问 " 如何看待数据中心和 AI 基础设施的未来 " 时,百度创始人李彦宏笃定地回答道:" 我们仍需对芯片、数据中心和云基础设施进行持续投入,用于打造更好、更智能的下一代模型。"
Alter聊科技








 京公网安备 11011402013531号
京公网安备 11011402013531号