3 月 10 日消息,“稚晖君”创业项目智元机器人今日发布了首个通用具身基座模型 —— 智元启元大模型(Genie Operator-1),它开创性地提出了 Vision-Language-Latent-Action(ViLLA)架构,该架构由 VLM(多模态大模型)+ MoE(混合专家)组成,实现了可以利用人类视频学习,完成小样本快速泛化,降低了具身智能门槛,并成功部署到智元多款机器人本体。
2024 年底,智元推出了 AgiBot World,包含超过 100 万条轨迹、涵盖 217 个任务、涉及五大场景的大规模高质量真机数据集。基于 AgiBot World,智元今天正式发布智元通用具身基座大模型 Genie Operator-1(GO-1)。
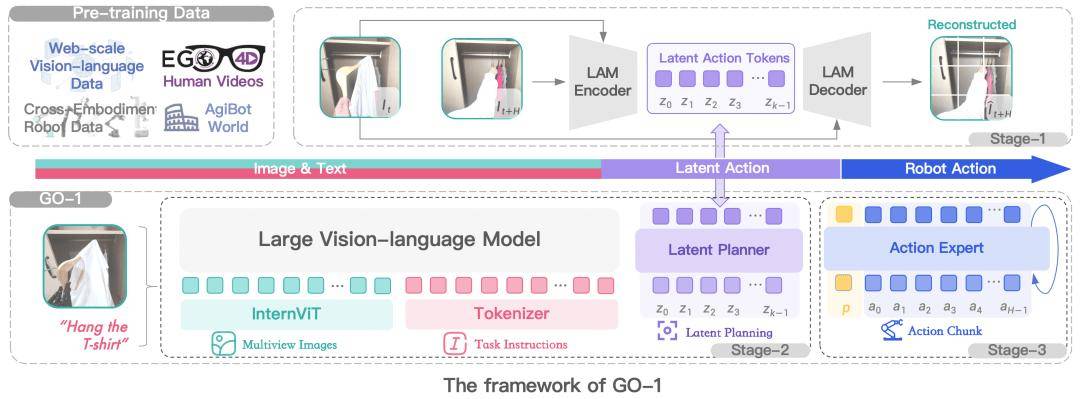
它开创性地提出了 Vision-Language-Latent-Action(ViLLA)架构,该架构由 VLM(多模态大模型)+ MoE(混合专家)组成:
VLM 借助海量互联网图文数据获得通用场景感知和语言理解能力
MoE 中的 Latent Planner(隐式规划器)借助大量跨本体和人类操作视频数据获得通用的动作理解能力
MoE 中的 Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力
通过 ViLLA 架构,智元机器人在五种不同复杂度任务上测试 GO-1,相比已有的最优模型,GO-1 成功率大幅领先,平均成功率提高了 32%(46%->78%)。其中“Pour Water”(倒水)、“Table Bussing”(清理桌面)和“Restock Beverage”(补充饮料)任务表现尤为突出。
此外智元机器人还单独验证了 ViLLA 架构中 Latent Planner 的作用,可以看到增加 Latent Planner 可以提升 12% 的成功率(66%->78%)。
GO-1 大模型借助人类和多种机器人数据,可泛化应用到各类的环境和物品中,快速适应新任务、学习新技能。同时,它还支持部署到不同的机器人本体完成落地,并在实际的使用中持续不断地快速进化。
这一系列的特点可以归纳为 4 个方面:
人类视频学习:GO-1 大模型可以结合互联网视频和真实人类示范进行学习,增强模型对人类行为的理解,更好地为人类服务。
小样本快速泛化:GO-1 大模型具有强大的泛化能力,能够在极少数据甚至零样本下泛化到新场景、新任务,降低了具身模型的使用门槛,使得后训练成本非常低。
一脑多形:GO-1 大模型是通用机器人策略模型,能够在不同机器人形态之间迁移,快速适配到不同本体,群体升智。
持续进化:GO-1 大模型搭配智元一整套数据回流系统,可以从实际执行遇到的问题数据中持续进化学习,越用越聪明。

智元机器人还预告了下一代具身智能机器人产品,不过没有透露推出时间。
附论文链接:








 京公网安备 11011402013531号
京公网安备 11011402013531号