
出品|虎嗅黄青春频道
作者|商业消费主笔 黄青春
头图|电影《华尔街之狼》
DeepSeek 犹如热浪席卷而过,市场叙事不再局限于眼花缭乱的“新模型”以及枯燥的参数比拼,短期注意力开始转移到“标配DeepSeek”的博弈上,其正从技术路线、落地场景层面对整个大模型竞争格局产生深远影响。
甚至,可以将DeepSeek R1视作针对互联网企业的一次大考——因为所有平台几乎同时拿到考题,在这个情况下,谁能适配产品给出最优解变成一场公开检验,不再像以往各家只是沉迷于自说自话、缺乏公允的参照标准。
要知道,连微信、百度在内的超级入口都抢着接入DeepSeek ,但豆包仍在坚持自研深度思考模型,说明字节仍未被DeepSeek“征服”:
一方面,字节内部认为,客户需求不会被一家模型公司全部满足,豆包的技术路线和 DeepSeek 存在差异;其次,评价一个模型有几十个不同维度,OpenAI、Claude、Google 也是某些方面强,某些方面弱一些。
另一方面,字节也留有“后手”,抖音作为掀起短视频浪潮的超级应用,逐渐解构了微信公众号在图文时代奠定的绝对优势,其对网友注意力及时间的挤占越发明显;但用户仍需跳出抖音使用豆包,若抖音全面接入豆包的 AI 能力、实现产品跳转互通(近日,抖音直接在短视频界面放开豆包入口,与点赞、评论、转发等功能并列),DeepSeek 之于移动市场的统治力便会被撕开一条口子。

事实上,DeepSeek 之前推出 V2 时,国外就比较关注,但国内却直到 V3 才彻底引爆,大模型浪潮的公众接受度迅速得以普及,应用场景也渗透到更下沉群体——需要指出的是,即便用户日常在网页端和手机端会经常使用大模型支撑的功能,但 C 端感知呈现毕竟不够直接,直到 DeepSeek 凭一己之力做出最好的开源模型,才彻底捅破夹在 B 端与 C 端这层“窗户纸”。
在火山引擎智能算法负责人吴迪看来,AI 就像未来的水和电一样,提供水、电的公司,并不会因为单位利润高带动变革,而是要整个行业通水、通电赚取服务利润才能长久。
这个逻辑就像移动互联网 3G、4G、5G 的普及一样,变革需要建立在使用场景、心智渗透充分的基础上——尤其,2023~2024 年大模型烈火烹油,每月都有新进展刺激着媒体的“肾上腺素”。
字节跳动 CEO 梁汝波曾在去年 All Hands 全员会上表示,字节在应对这波大模型浪潮时显得迟钝——有趣的是,2024 年初开完这个会,字节便开始奋起直追,年末媒体的叙事就变成张一鸣见技术大牛、看论文,字节不动声色从迟缓切换到一骑绝尘的姿态,而字节年内的大模型叙事也摇身一变成了“逆袭样本”。
对此,吴迪认为,这是一个未来 10 年、20 年的事业,眼下走得快一点或慢一点,放在一个很长的历史周期来看没有太大差别,只是 C 端用户及媒体非常在意、不断进行审视和解读。
“做好自己的产品更重要,比如 B 端客户关注好产品性价比,C 端客户关注好产品体验,即用户用哪个 APP 感觉更舒服、更有用、更务实就好了。”吴迪说道。
当然,过去两年大模型走到喷薄而出的黄金窗口期,各家习惯堆算力、堆资源,然后用产品进行心智卡位;然而今年春节后,腾讯元宝通过“钞能力”在 APP Store 免费榜先超豆包、再超 DeepSeek,最终登顶(3月3日晚,腾讯元宝超越DeepSeek与豆包登顶中国区APP Store免费榜),一切似乎又回到了移动互联网卷投放、抢渠道入口的“暴力烧钱”路径。
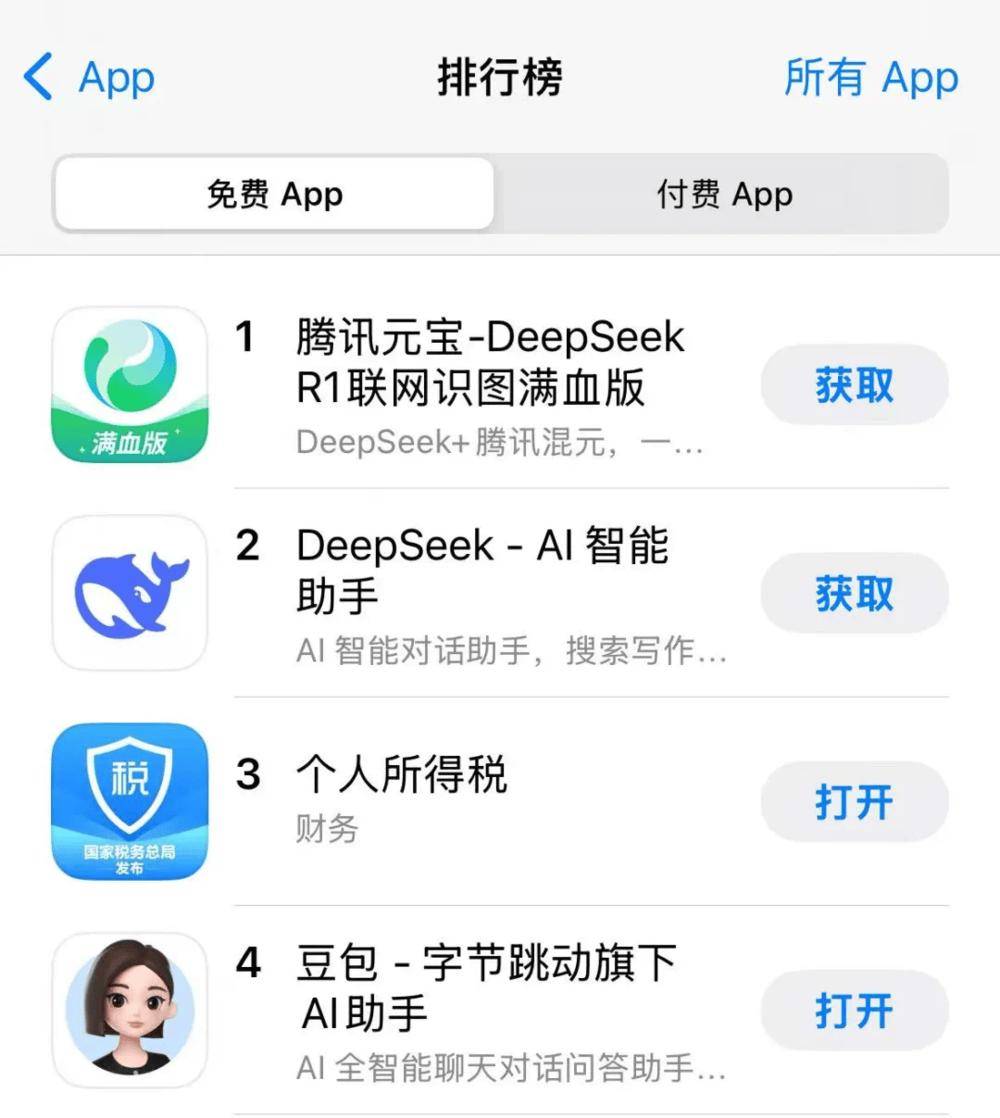
对此,吴迪认为,不管下载榜上是什么位置,这些短期波动不能代表一款产品最真实的用户使用情况,长期决定一个产品日常体量的一定是用户体验,以及能不能解决 C 端用户和 B 端客户的真实诉求,才是核心。
“火山更看重的是‘成功的早期信号’,AI 如同一场马拉松,早期不可能瞄着最终目标去做事,要找的一定是‘成功的早期信号’——基于此,团队重心主要会放在产品优化上,跟客户交互、倾听反馈,自然能搞清楚是不是在‘成功的早期道路上’。”吴迪说道。
以下为虎嗅与火山引擎智能算法负责人吴迪沟通实录(部分表述因方便阅读需要有所删减和调整):
字节仍不服DeepSeek
Q:现在其他应用都在积极接入 DeepSeek,豆包为什么仍然在坚持做自研模型?
吴迪:您觉得世界上需要一家模型公司就够了吗?首先,从服务企业客户的视角来看,豆包的技术路线和 DeepSeek 存在不小的差异;其次,评价一个模型像评价一个人,很难十全十美,评价一个模型有几十个不同的维度,任何模型都不可能所有方面做到最好, OpenAI、Claude、Google 都是某些方面强,某些方面弱一些。
豆包在文案生成润色、信息抽取等方面表现优秀,尤其 vision (视觉理解方面)能力在国内非常靠前。举个例子,熟食店橱窗需要摄像头监测食品摆盘,任何盘子把底露出来就会自动通知补货,这原本要专用模型、成本高,现在豆包不仅适配,还能在工具化和准确度方面大幅提升。
所以,从 B 端需求来看,火山的客户覆盖广泛,很多企业应用方向主要是数据分析、离线抽取、聊天对话、市场信息处理,这些维度豆包强于 DeepSeek RI 模型。
而且,DeepSeek RI 模型和豆包模型可以形成互补,DeepSeek 有推理优势,豆包模型强的地方 DeepSeek RI 模型也有一些不足,所以很多客户会同时选择多家大模型。
今天火山还发布了 DeepSeek 版的一体机,针对金融行业普遍的私有化部署需要,AI 一体机通过搭载轻量化统一底座 veStack,支持豆包大模型、DeepSeek、MaaS、HiAgent、大模型防火墙、轻量机器学习平台产品,提供大模型部署、管理、推理、微调、蒸馏、应用开发等产品能力。
Q: 各家标配接入DeepSeek 会不会改变大模型厂商格局,甚至影响以后的路线?
吴迪:大模型产品格局每个月都在变,AGI 发展速度也非常快,它会因为各种各样不同的原因推动格局变化。
Q:火山与 Flow 部门在业务逻辑、产品策略、商业化方面的差异?
吴迪:这个差异特别好理解,豆包大模型团队和基础工程技术就像一个大中台, Alex 带领的 Flow 团队(Flow 是与抖音、火山、飞书等平级的主要业务部门,由朱俊领导)专攻把平台的能力往 C 端导;火山是赋能 B 端,把能力提供给企业端、开发者端。
Q:字节 Flow 团队刚成立不久,分工是最近拆分还是之前 C 端能力在另一个团队?
吴迪:这个之前集团就有共识,不仅仅是大模型能力,公司各业务的基础能力都是通过火山引擎走向企业,这是整个组织协同的默契和共识。
Q:去年 6 月份大模型价格战,外界注意力是字节掀起了大模型价格战,然后阿里、腾讯、百度相继跟进,其实是 DeepSeek 最先主导的降价,为什么大家当时没有注意到?
吴迪:传播有时候像“薛定谔的猫”,你大致可以判断出来有一件事情可能会在某个时刻发生,但是当你最后去预测的时候,往往(卡点)不够准确。
至于去年豆包全家桶掀起的行业降价,谁率先发起(降价)无关紧要,重要的是推动整个行业扎扎实实去把性价比做好。
Q:价格战不是某一家主动为之,而是行业推动的结果,为何字节会遭受百度高管的“炮轰”?
吴迪:过去 14 个月 OpenAl 价格降到 14 个月前的 4%,模型能力变强了 N 倍,怎么没人去炮轰它打价格战?不同公司对这个事情的认知不太一样。
在我看来,AI 就像未来的水和电一样,提供水、电的公司,并不会因为单位利润高而活得长久,而要整个行业都通水、通电赚取服务利润才更长久。火山在 Deep Learning 方面有很长时间的积累,有非常健康的毛利。
还有个重要考虑,很多人都没有意识到客户要试错。比如一家电子商务公司,知道两年后一定会大量使用大模型,但具体在什么地方以什么形态用无法确定,所以这时候就要试错,我们的价格定在这个水位线上是考虑了客户的试错成本,试错 100 次只要成功一次,场景就能建立。
因为字节自己做 APP,有丰富的业务,从字节一系列孵化的 APP 场景,或者是产品功能上慢慢去调优出一个区间,所以可以站在客户的角度,感同身受。
有些云厂商,脱离实际业务比较久,慢慢就把自己当成一个纯粹的服务商,自然习惯“在商言商”。
不care短期波动
Q:如何看待腾讯元宝在APP Store免费榜超过豆包?
吴迪:我个人观点,不管短期豆包在下载榜上是什么位置,长期决定一个产品日常体量的一定是用户体验,一定是如何解决 C 端用户和 B 端客户的真实诉求。
相对市场投放行为,短期波动真谈起来没那么重要,其实用户是非常聪明的,他们有很敏锐的感知,他们能够 sense 到,能感知到什么样的体验是好的,什么体验是差的,我们今年的主要目标是追求智能的上限。
Q:阿里计划未来三年至少投入3800亿元,字节有没有这种规划或者目标?
吴迪:第一,长期的云基础和算力规划肯定有,我们一般是往三年、五年甚至更长时间去做,但不会对外先宣布数字;第二,我不太清楚,阿里投入3800亿具体怎么落实、怎么分配,比较模糊。
Q:移动浪潮起来的互联网巨头擅长利用资源培养用户心智和产品习惯,应用变现能力很强,但技术底层创新动力不足,字节也有这种路径依赖吗?
吴迪:DeepSeek 在技术架构方面有创新,MLA 是一个好的 attention 方面的改进和尝试,但世界上有数十种不同的 attention 的变种和优化, 我相信未来还会有更多更有创新的想法出现,这是第一点。
第二点是什么呢?火山更关注对整个企业服务市场的务实普惠,比如去年将每百万个 Token 价格降到 8 毛,这肯定是让整个行业受惠受益的一件事情,我们更关注和针对是在 B 端客户服务体验和成本下沉。
Q: 现在很多厂商强调接入 DeepSeek 是满血版,凸显的是什么?
吴迪:首先凸显是答题准确率,比如 100 道数学题能做对多少,所谓满血版就是 DeepSeek 官方版本作为参照,准确率在 95%-100% 之间,要看效果、要看智能水平,火山能做到 95%。
Q:标配DeepSeek对云厂商格局短期影响如何?会大幅提升应用落地速度和服务效率吗?
吴迪:我觉得有两个影响,一是客户更容易看出来谁在 AI 的基础能力上强一些,谁在 AI 的基础能力上弱一些,因为这是开卷考;二是 DeepSeek 进一步激发了中国市场对算力和大模型的需求,去年我有很多的工作时间都在鼓励客户多用、敢用,去积极拥抱 AGI,现在 DeepSeek 帮我把这个工作难度降低了,客户会更积极地去尝试 AGI。
现在,很多客服对话系统都在使用大模型,只是它没有以一个显性的东西摆在你面前。不管是算法精度还是并发处理能力、响应速度、语言深度都是看大模型整个的智能的水平高低去决定的。
智能水平要不断地变高,不断地 scaling 上去,这是至关重要的;然后在智商不断提高的前提下,系统越做越快、越做越便宜、越做越稳定,最终千行百业都能从中受益。
Q:如果将接入 DeepSeek 视作一次大考,在落地场景、商业化方面影响如何?
吴迪:今天上午团队开会还聊起这个话题,其实接入DeepSeek R1 主要看稳定性、响应速度等。
为什么说 DeepSeek R1 是一次面向行业的大考?因为所有平台几乎同时拿到考题,在这个情况下,谁能够把这道试卷答得更好就变成一次公开检测,不再像以往各家只能自说自话、缺乏公允的客观评价。
比如在第三方评测中,完整回复率指所有 prompt 得到完整答复,没有中断、没有失败;准确率指拿 100 道数学题去问各个平台的 DeepSeek RI 模型,看答对多少题。结果很多号称满血版的 DeepSeek R1 测出的智力水平参差不齐,完全像两个模型,这很可能是为追求稳定性,对 DeepSeek R1 的精度裁剪太狠了。
其次,是响应速度,长思考模型最关键的一点是吐字过程特别长,每个Token延迟非常重要,火山引擎在保证准确率前提下,吞吐速度是很多友商的两三倍。
Q:这个指标应对的是奥数推理,像 DeepSeek 强的是逻辑能力,它侧重的点不同会导致数据差异性?
吴迪:其实现阶段看三方面能力,一是写代码,二是做数学题、物理题,三是长文本或长报告的深度总结和分析。
虽然(模型的)每道测试题肯定有偏重,但数学解题维度差异大,长文本深度分析差异会小吗?这个很难。因为各平台部署都号称满血版,是官方671B模型,若模型一样但得分差异大,只能说明在精度上损失严重。
火山等待“爆发”
Q:去年字节 CEO 梁汝波在 All Hands 全员会上说团队在这波大模型浪潮中比较迟钝,是投入不足错失了窗口期吗?
吴迪:2023~2024 年大模型(烈火烹油),每月都有新变化,根本原因是公司目标高,越重要的业务肯定要得到来自 CEO 更高的要求。
当然,如果我们在 thinking 方面投入能够更早、更快的话,也可以拿出更好的成绩单。
Q:有趣的是,后面媒体的叙事里又变成张一鸣见技术大牛、看论文,字节在这波大模型战又被塑造成“逆袭样本”?
吴迪:一方面,豆包模型在过去一年中肯定是得到了大家越来越广泛的认可,包括豆包 APP 的用户体验;另一方面,万里长征才走出了第一步,这是一个未来10年、20年的深耕方向,眼下走得快一点或慢一点,放在一个很长的历史窗口来看没有太大差别。
团队更关注自己的产品体验、产品性能、精准度、并发处理能力、响应速度等等,这些才是大模型更重要的点,它们会影响 B 端客户,最终体现在大模型产品极致的性价比。
Q:之前各家都在堆算力、堆资源、堆人力,认为大模型是通过资源累积、抢时间窗口、产品心智卡位,但是 DeepSeek 似乎证明不是这样一套路径?
吴迪:DeepSeek 获得大量关注,一言以蔽之就是:非常精干的团队做出了世界上最好的开源模型,这是根本。
Q:火山整个 API 接入情况如何?目前需求旺盛的行业主要是哪些?
吴迪:以整个火山方舟平台对公有云客户提供的Token市场占比来讲,应该在国内最高。2024年 12 月对外发布过一组数据,豆包全家桶(包含自用)当时Token每天消耗量是 4 万亿。
目前,大模型应用比较积极的行业,一是聊天陪伴类产品,二是大量离线数据分析需求,三是和 education 有关、教育相关,四是电商客服这类场景相关。
Q:现在整个团队规模情况?接下来火山有没有什么新模型或者新业务节点?
吴迪:火山这边 AML 要去 learning 企业服务,团队还是比较精干的,大概研发工程师 100 出头,包含 RD, QA、 SRE, 然后算法工程师大概五六十人,同时负责方舟上的大模型服务, 以及火山机器学习平台。
当然,新模型肯定会持续不断地出,然后也会在一些城市巡展会,或者是每年春季和冬季 force 大会上向大家再批量地公布一些模型方面的进展。下一次对外做产品发布可能要到5、6月份,这中间会有一些中小型活动或者是有些新的发布。
Q:这个人员规模相比外界感知到火山能力过于精简?
吴迪:我们在争取和吸引最优秀人才方面肯定毫不手软,而且非常有竞争力,我一直认为一个团队也好,或者一个公司也好,不管它规模有多大,一年能够真正实实在在做好的大事情,也就是三五件事。
所以,团队绝对不会为了争取市场快速扩张,然后在非常早的时候把团队搞得特别臃肿,(那是)非常愚蠢的事情。一个精简的团队,大家配合得非常默契、信息非常透明,像创业团队一样把代码写好、把产品做好,这样的团队才能走得更长久。
Q:这是在梁汝波倡导“要保持创业精神,逃逸平庸的重力”之后,还是此前团队秉承的理念?
吴迪:我们团队(一以贯之),这对 leader 的判断力要求特别高, leader 必须搞清楚什么事情是重要的,要大力做三年、五年,什么事情是不重要的那就坚决不投入。举个例子,火山引擎的机器学习平台网页很简洁,从来不搞花哨的 Feature。
谭待(火山引擎总裁)更看重的是“成功的早期信号”,AI 如同一场马拉松,早期不可能瞄着最终目标去做事,要找的一定是“成功的早期信号”——基于此,团队重心主要会放在产品优化上,跟客户频繁交互、虚心倾听反馈,自然能搞清楚是不是在“成功的早期道路上”。








 京公网安备 11011402013531号
京公网安备 11011402013531号