文|光锥智能 白鸽 魏琳华
2月28日凌晨,OpenAI发布最新GPT-4.5模型,该产品一经上线,就备受网友吐槽,吐槽的点集中在价格贵得离谱,反应又特别慢。
其中,X 网友 @Colin Fraser 实测的一道逻辑谜题出现严重错误。价格方面,GPT4.5 API价格不仅远超DeepSeek R1,输入每百万Tokens75 美元的价格甚至比GPT-4o的2.5美元还贵30倍。
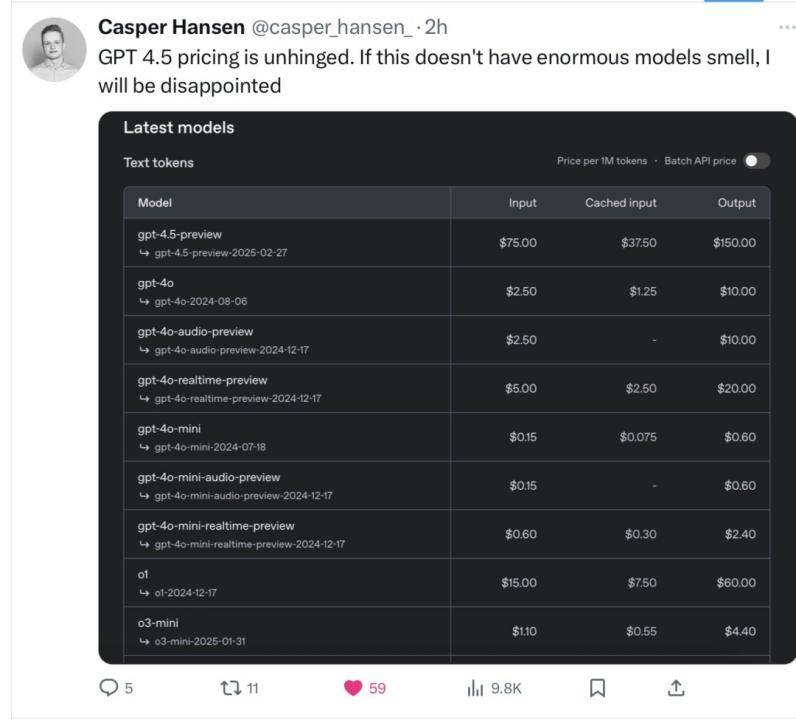
“GPT4.5的定价非常高,如果这些模型没有显著改进,我会感到失望。”X 网友 Casper Hansen 发帖说道。
可以看到,OpenAI此次发布会略显仓促,甚至OpenAI CEO奥特曼因需要照顾刚出生的孩子没有到达发布会现场。而如此仓促的背后,或许是受到了来自中国大模型赶超的压力。
2月28日,百度正式官宣将于3月16日上线文心大模型最新版4.5,不仅在基础模型能力上有大幅提升,且具备原生多模态、深度思考等能力。此前,百度还宣布将从6月30日起,将文心4.5开源。
前段时间火出圈儿的DeepSeek发布的DeepSeek-R1大模型,不仅在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,更重要的是对算力资源的极致利用,让成本做到了最低。这也令国外同行在《自然》杂志上惊呼:“这太疯狂了,完全出乎意料”。
而这第二场竞赛的关键,除了比拼大模型的基础能力外,更考验对成本的控制和开源生态的建设。毕竟,这些综合因素,都是关乎大模型是否能够真正实现大规模落地应用的根本。
事实上,此前中国的大模型一直被看作是OpenAI的追随者,从大语言模型,到多模态大模型,再到推理大模型,都紧跟在OpenAI之后。
但现在,“中国在生成式AI领域正在赶超美国,甚至在视频生成等领域,中国似乎已处于领先地位。”著名人工智能研究学者、DeepLearning.AI创始人吴恩达在博客中如此写道。
从追赶到超越,基础大模型的开年之战
放在半年前,OpenAI每发布一次大模型,便会引起圈内的一次“地震”。但这次,定价昂贵、性能一般的GPT-4.5,让OpenAI遭遇了第一次在模型上的滑铁卢。
GPT-4.5的“失灵”,正是中美大模型实力博弈的一个注脚,它映射出当前大模型圈的地位变更——和开启狂卷模式的其他公司相比,OpenAI能带来的技术突破越来越有限,且极其没有性价比。
与之相反的则是国内大模型公司们,正集体在2025年密集“秀肌肉”。2025开年以来,即使在中国人最忙碌的春节前后,大模型公司们仍然保持着极快的速度发布新的大模型。
不同于2022年底开始,国内大模型争分夺秒,只为和海外公司缩小差距的第一场竞争,这一次,由国内发起的大模型“第二场竞速”,目标直指在各方面超越海外的顶尖成果。
从性能、训练成本、推理成本再到模型架构等方面横向对比,这是一次中国大模型界的“百花齐放”:
火爆出圈的DeepSeek,不仅性能直追OpenAI的推理模型,还把训练及推理成本打了下来;MiniMax的新模型不再遵循海外公认的Transformer架构,而是改成了更利于上下文记忆的线性注意力机制;月之暗面的推理模型K1.6尚未正式发布,但已经在基准测试平台LiveCodeBench上登顶第一,超过了OpenAI的o3-mini。
在技术无限缩小甚至超越的基础上,中国大模型开始找回自己的主场优势,对于Day 1就在思考落地问题的大模型公司来说,谁能在技术优势的基础上,找到落地场景的最优解,就能赢得接下来的应用卡位赛。
对于既有流量、又有生态优势的大厂来说,场景化本就是他们的优势。而在DeepSeek爆火后,他们在这场大模型之战中放出了相当有诚意的动作。
以百度为例,它算得上是大厂梯队中最下血本的一家。
2月13日,百度宣布文心一言将于4月1日0时起全面免费,所有PC端和APP端用户均可体验文心系列最新模型,这其中就包括要在3月16日正式上线的文心一言4.5。在OpenAI大举商业化旗帜,开售200美元会员月费的当下,百度能把最顶尖的模型免费拿出来,已经够有诚意。

在免费的基础上,百度还准备把文心一言4.5开源。
在这场席卷而来的大模型之战中,李彦宏快速找到了卷模型背后的关键问题。
“我想强调的是,无论开源闭源,基础模型只有在大规模解决现实问题时,才具备真实价值。”李彦宏说。
追赶海外顶尖技术的同时,中国大模型已经跳出了固有的竞争框架,在这场中美大模型的博弈中,大模型公司们正在思考弯道超车的可能性。
大模型开源背后,中国企业对成本的极致优化
春节后的一个月,在中国大模型市场掀起了一股DeepSeek接入潮。截至目前,已经有近200多家企业官宣将深度接入DeepSeek大模型产品。
不仅是百度AI搜索、百度文库等C端产品,B端的云厂商也在MaaS服务平台中,集成DeepSeek大模型,为客户提供相关API调用服务,还考虑围绕DeepSeek推出私有化部署的方案。
比如,百度智能云千帆接入 DeepSeek-R1/V3模型,上线首日就有超1.5万家客户通过千帆平台进行模型调用。而百度智能云旗下客悦、曦灵、一见、甄知四款大模型应用产品,正式上线接入DeepSeek模型的全新版本。
除了应用层外,百度在基础设施层面也深度适配了DeepSeek,如基于昆仑芯P800,百度百舸发布部署 “满血版DeepSeek R1+联网搜索” 服务,能够为企业提供及时、准确的信息支持。
针对企业私有化部署需求,百度智能云发布DeepSeek一体机解决方案,在私有化部署层面搭载昆仑芯P800的百舸、千帆、一见一体机产品,可支持在单机环境下一键部署DeepSeek R1/V3全系列模型,提供开箱即用的便捷体验,在确保性能与安全合规的情况下,能够助力企业快速实现模型部署落地。
目前,针对企业私有化部署需要,除百度智能云外,其他云厂商也纷纷在部署相关DeepSeek一体机解决方案,但相比较来说,自研GPU芯片的百度,无疑更具有成本优势。
事实上,此次百度宣布大模型开源和免费的底气,就来源于从底层基础设施,到上层工具链,以及大模型推理应用的体系化技术创新。
从底层基础设施来看,百度自研的昆仑芯性价比极高,得益于昆仑芯的成本优势,百度智能云率先点亮了首个国产万卡算力集群,能够为大模型的部署和应用提供稳定的算力支持。
据外部猜测,此次文心一言全面开放功能,背后最大的原因之一是推理成本不断降低。
该分析人士表示,百度在模型推理部署方面有比较大的优势,尤其是在飞桨深度学习框架的支持下,其中并行推理、量化推理等都是飞桨在大模型推理上的自研技术。飞桨和文心的联合优化可以实现推理性能提升,推理成本降低。
当然,大模型最关键的,还在于找到具体的应用场景,能够实现真正的应用落地。
有数家做企业服务的销售人员对光锥智能表示:“大模型来了之后,咨询的企业增多,但真正落地应用的比较少。”比如在企业OA系统中,集成DeepSeek大模型,更多的是为企业提供知识问答能力,在一些智能客服场景中,大模型的能力优势更为凸显。
就像百度在客悦、曦灵、一见、甄知四款自身应用产品中,上线接入DeepSeek模型的新版本,业务以企业智能外呼、数字人视频脚本生成、视觉智能分析、知识管理等场景为主。
无疑,依托全栈自研四层技术架构(云、深度学习框架、模型、应用),百度能够实现端到端优化,不仅大幅提升了模型训练和推理的效率,还进一步降低了综合成本。
总的来说,当前大模型技术发展如此之快,则必须要持续投入,以确保处于技术创新的最前沿。
“我们仍需对芯片、数据中心和云基础设施进行持续投入,来训练更好更智能的下一代模型。”李彦宏说道,为此,需要使用更多的算力来尝试不同的路径。也许,在某个时刻,你会找到一条捷径,比如说只需600万美元就能训练出一个模型,但在此之前,你可能已经花费了数十亿美元来探索,哪条路才是花费这600万美元的正确途径。
总之,只要用户/客户想要,中国公司没有做不到。
事实上,于企业自身来说,前期研发成本投入是固定项,只有当技术真正投向应用,让更多的用户来使用这个技术,才能真正实现规模经济优势。
而扩大规模经济优势的同时,只有通过技术降本,免费和降价才能得以持续。
李彦宏曾表示:“今天,当我们谈论大型语言模型时,12个月内推理成本基本上可以降低90%以上成本。并且,大模型的性能也越来越好。”
无疑,当大模型推理应用成本降得足够低,就能够让大模型真正走向千行百业,也势必将真正地让中国生成式AI实现弯道超车。





 京公网安备 11011402013531号
京公网安备 11011402013531号