极点商业

无论DeepSeek,还是文心大模型4.5,都已率先进入第二战场,掀起一场将大模型门槛拉低到极致,推动产业落地、应用爆发的革命性探索。
作者|刘珊珊
编辑|Cindy
分隔在大洋彼岸的中美两大AI企业,同一天宣布了重磅消息。
2月28日,百度宣布,文心大模型4.5将于3月16日正式上线。根据百度方面介绍,最新版不仅在基础模型能力上有大幅提升,且具备原生多模态、深度思考等能力。
“文心大模型4.5,将是百度有史以来最强大的大模型。”此前百度2024年Q4及全年财报电话会上,百度创始人、董事长兼首席执行官李彦宏如此透露。
受来自DeepSeek、百度、阿里等中国大模型的挑战,OpenAI在北京时间周五凌晨发布博文,宣布GPT-4.5大模型正式登场。这款被OpenAI内部代号为“Orion”的模型,被声称是其最大、最佳的聊天模型。

众所周知,过去几周全球AI产业界都正因DeepSeek而巨变。在全球AI竞赛加剧之际,作为中美两大领先AI企业,百度和OpenAI的新动作,自然更受外界关注。
目前来看,百度将通过文心大模型4.5,打出“开源、免费”组合拳,走向更加开放的策略。
相比之下,GPT-4.5的高情商和人性化表现也带来了惊喜,但整体差强人意,因为并不是推理型模型,在性能上也与OpenAI前几代模型有差距——更强大基础大模型仍然是护城河逻辑不变下,中国大模型正加速占据以应用落地为主题的大模型第二场主动权。
01
开源+免费”,百度更为开放
进入2月以来,百度已密集放出了多个重磅“AI炸弹”。
2月12日,CNBC一则关于百度文心大模型5.0版本将于下半年发布的消息,在AI行业引发震动。2月13日,OpenAI首席执行官Sam Altman(山姆·奥特曼)宣布将在未来几个月推出名为GPT-5,中美大模型竞赛氛围越来越浓。
最重磅消息来自百度。同一天,百度宣布文心一言将于4月1日0时起,全面免费,所有PC端和APP端用户均可体验文心系列最新模型。同时,上线深度搜索功能。
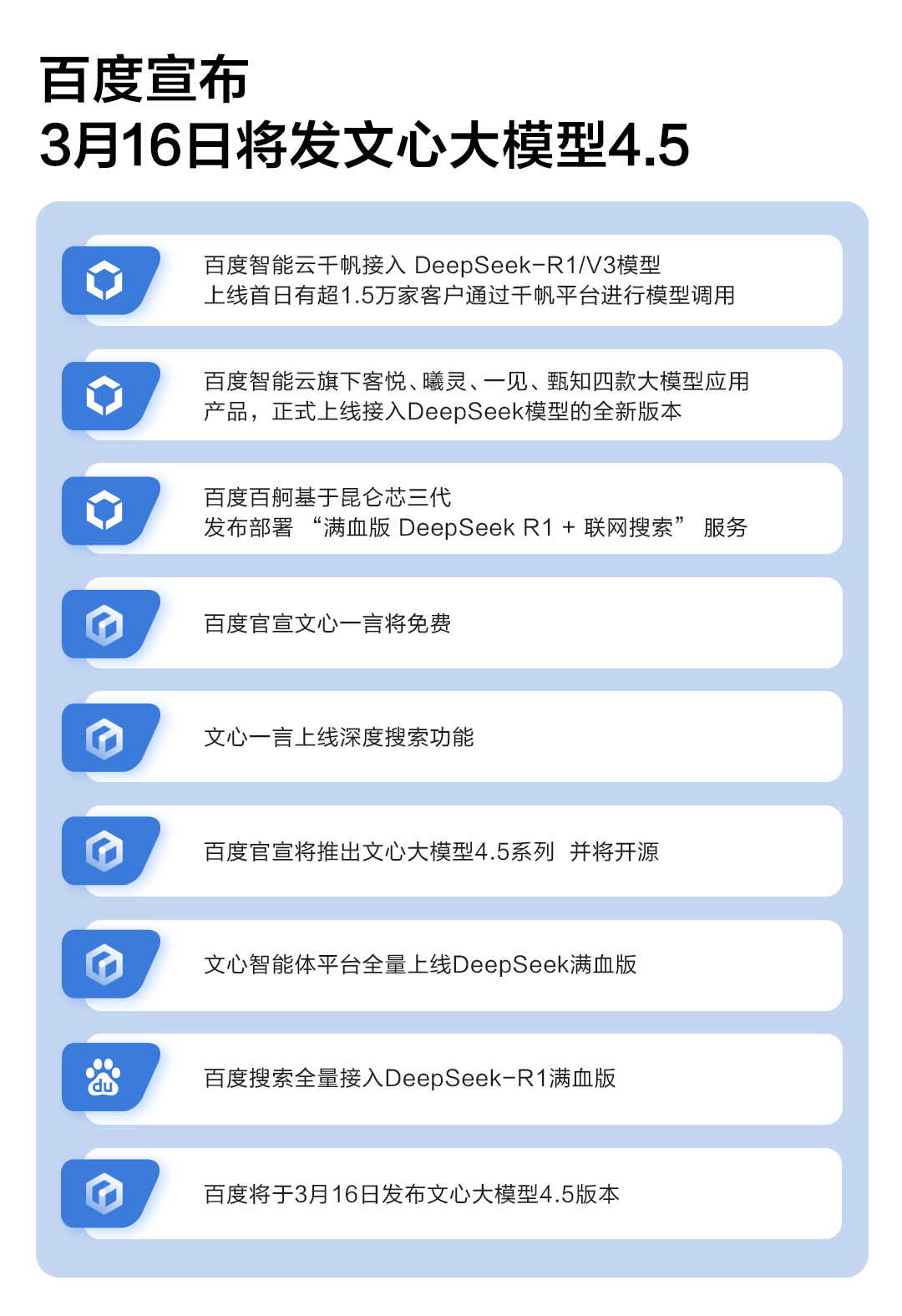
1天后(2月14日),百度宣布将在未来几个月中陆续推出文心大模型4.5系列,并于6月30日起正式开源。
这意味着,文心大模型就此打出“免费+开源”组合拳,百度AI策略更为开放。
百度转变和DeepSeek横空出世带来的震动,有一定关系——但不止百度,OpenAI、腾讯、阿里等国内外AI巨头,无一不受影响。比如OpenAI,就在中国大模型压力下,被迫加速模型发布和开源的脚步。
更客观现实是,开源和闭源,其实并没有绝对的优劣之分。
作为中国大模型最早入局者,百度文心大模型是全球最早对标GPT的LLM大模型,几年时间里,文心大模型经过了持续的迭代和进化。比如,文心一言版本已经迭代到了4.0,无论是日均超15亿次的调用量,还是在各行业的赋能落地,都是推动中国大模型发展的重要组成部分。
同时,在百度强大生态支撑下,百度搜索、百度地图、百度文库、百度智能云等,都早已在给普通用户提供最完整的AI服务。
多位业内人士就此认为,百度走向“开源+免费”,是大模型发展的“顺势而为”,其意义重大,可以更好地推动技术平权。它让全球用户能够毫无门槛地运用中国顶尖的大模型技术,更是大模型从专业范畴,迈向大众市场的关键转折点。
李彦宏在多个场合的表态,也表明了,百度如今对开源与闭源模型价值的思考逻辑。“我在过去几个月中学到的是,开源可以帮助你获得更多关注。我们正处于AI、生成AI创新的早期阶段,更快的传播将有助于提高采用率,但也有助于更多的人尝试这项技术。”
这背后,体现的是百度组合拳,推动技术平权时的底气和开放心态。
比如,百度系多款产品,百度搜索、百度文库、百度网盘都全量接入了DeepSeek- R1满血版。相比其他产品入口较深,任何普通网友,都可以在百度首页搜索框下方,点击“AI搜索DeepSeek满血版”直接体验。

无论如何,自研大模型才是百度最强竞争力所在。如同李彦宏指出,基础模型真正的价值,只有在能够有效解决现实问题并广泛应用时才能得到体现。“即使是开源,如何确保其在实际应用中展现出色的表现,才是企业必须面对的挑战。”
至此,留给外界的疑问,无外这场普惠大众的AI 变革浪潮,何时正式开启。
2月27日,路透社爆料称,百度将在3月中下旬发布文心大模型4.5 。或许是明显感受到了来自中国AI的竞争压力,OpenAI略显仓促的在2月28日推出GPT-4.5——发布会仅持续不到14分钟,OpenAI的CEO山姆·奥特曼正在医院陪刚出生的孩子,并未现身。
02
史上最强文心大模型,有多强?
随着文心大模型4.5正式登场日的官宣,接下来半个月中,业界都会有一个共同猜测:史上最强文心大模型,到底有多强?又有哪些能力值得期待?
可以肯定,和GPT-4.5不同,文心大模型4.5,将在基础模型能力上有大幅提升,带给用户最明显的感受,可能是RAG能力进一步增强,将在幻觉方面降低到新水平。
“幻觉”,是悬在AI发展之路上的达摩克利斯之剑。指的是大模型在试图生成内容或回答问题时,输出的结果不完全正确甚至错误,即通常所说的“一本正经地胡说八道”。
在大模型领域,由于训练知识存在偏差、过度泛化地推理、理解存在局限性等,幻觉是每个模型与生俱来的缺陷。

大模型或多或少都有幻觉问题
例如OpenAI,多份研究此前指出,o3-mini大约只有10个简单问题中答对1个,两年来幻觉问题都没有得到改善。异军突起的DeepSeek,也因在解答西安安定门绕行问题时 “翻车” 而备受关注。
RAG(检索增强型生成),在解决幻觉问题上扮演着至关重要的角色——在推理过程中,RAG 使用检索到的数据作为参考来组织答案,从外部知识源中动态检索信息,以此帮助大模型生成更丰富、更准确、更可靠的内容。可以说,RAG给大模型增加了一个可以快速查找的“知识外挂”。
毋庸置疑,在国内,百度拥有最丰富的实时与个性化的数据和知识,研发了“理解-检索-生成”RAG能力。从各种RAG能力实测来看,国内外主流大模型中,百度文心一言综合表现最佳。
比如,在和OpenAI的直接PK中,即使是春节档电影细节、春晚节目等内容,文心都能准确回答;相比之下,OpenAI虽能检索到信源,却无法生成准确回答。

基于此,去年11月的百度世界2024大会上,百度发布了自研的检索增强的文生图技术(iRAG),将百度搜索的亿级图片资源跟强大的基础模型能力相结合,大幅降低图片生成领域的幻觉,大幅提高了文心的模型可用性。
可以预计,在文心大模型4.5中,随着大模型的训练数据得到进一步扩充,AI幻觉也会大幅降低,不仅让百度自身AI应用快速进化,也能够让更多行业放心用上大模型。
近期,文心一言就上线了“深度搜索”功能,具备专家级问答能力,RAG能力突出,尤其是专业领域问答幻觉率低。
在OpenAI的GPT-4.5不具备推理能力,还是主打写作等文本生成趋势下,文心大模型4.5究竟能呈现怎样的原生多模态、深度思考能力?以及可以在哪些场景下落地应用?显然更值得期待。
可以推测,在DeepSeek掀起大模型降价浪潮后,文心大模型4.5也会加速推动性能升级与成本降低,有望催生新的商业模式和产业生态。

值得一提的是,得益于飞桨和文心的联合优化,文心大模型在推理性能提升同时,推理成本也得到了有效降低——根据去年世界大会上的说法,其推理成本一年降低99%。
从李彦宏演示的个例来看,以前拍一组汽车在某场景的大片宣传海报动辄需要一二十万,甚至大几十万,使用iRAG后,创作成本接近于0。
推理成本降低速度还在加快。李彦宏在阿联酋迪拜出席“世界政府峰会”上表示,“在过去,当我们谈论摩尔定律时,每18个月,性能水平或价格都会减半。但是今天,当我们谈论大型语言模型时,增加的成本基本上降低了,可以在12个月内降低90%以上。”
所以,这也是众多企业和开发者,对于文心大模型4.5的共同期待。一位开发者就说,基于文心大模型4.5,希望无论是开发原生应用,还是做二次开发,都能够方便地体验,拥有更低的推理成本和更高的训练效率。
03
第二场竞速,
中国大模型赶超美国提速
上述开发者的期待,其实正是在百度接连打出“开源+免费”组合拳后,李彦宏的表态:“希望客户和用户能比之前更方便地体验这款模型。”
某种程度看,无论DeepSeek,还是文心大模型4.5,都已率先进入第二战场,掀起一场将大模型门槛拉低到极致,推动产业落地、应用爆发的革命性探索。
中国是全球唯一拥有联合国产业分类中所列全部工业门类的国家,不仅拥有全球最多的C端用户,还有最广阔的B端市场,对AI应用落地来说,这是独特的巨大优势。

如何让大模型更好应用于千行百业,全面升级产业同时,创造一个巨大商业市场,是自上而下的共识。权威媒体就在评论中认为,大模型落地应用,是中国AI当下最重要的命题。
“作为生产力工具,以大模型为代表的AI技术,不仅将与营销、文娱、社交、电商等AI原生应用深度融合,还会重构、改造传统制造、医疗、HR、教育、金融、法律等垂类应用,推动千行百业向高质量方向发展。”一位观察人士说。
过去十余年来,美国或许一直在AI竞赛中领先中国。但从DeepSeek到文心大模型4.5,这一切正在迅速改变:
尽管OpenAI等明显感受到了来自中国的竞争压力,也在想方设法提速,但GPT-4.5“最佳聊天的小家子气”——GPT 4.5(研究预览版)甚至输出价格是每百万token 150美金相比,依然让更多美国AI人士相信,这标志着在大模型第二场竞速,也就是应用落地比拼中,中国大模型正不断赶超美国。









 京公网安备 11011402013531号
京公网安备 11011402013531号