GPT-4.5 不能说没有进步,但比起飙涨的推理成本,就显得 OpenAI 有些力不从心了。
北京时间 2 月 28 日,OpenAI 举办了一场相当简单的直播,正式发布了传闻已久的 GPT-4.5(研究预览版)。但 OpenAI CEO Sam Altman(山姆·奥特曼)没有亲临直播现场,官方也指出 GPT-4.5 不是一个前沿模型。
相比之下,两年前发布 GPT-4 的场面明显更隆重,也更有想法。而这些迹象似乎在开始就表明了:OpenAI 也不认为,GPT-4.5 会是一次里程碑式的升级。
但有一说一,GPT-4.5 依然是 OpenAI 最新、最强的聊天模型,不仅回答时的情商更高了,尤其重要的是,相比 GPT-4o 的准确率提升了 24.%,幻觉率更是降低了 24.7%。
这些提升还是非常关键,要知道,这两方面依然是包括 DeepSeek-R1 在内很多大模型,在使用上最大的问题。
单看这一点,其实也值回了观看直播发布活动的「票价」。但相对地,使用 GPT-4.5 的「票价」很难评了:
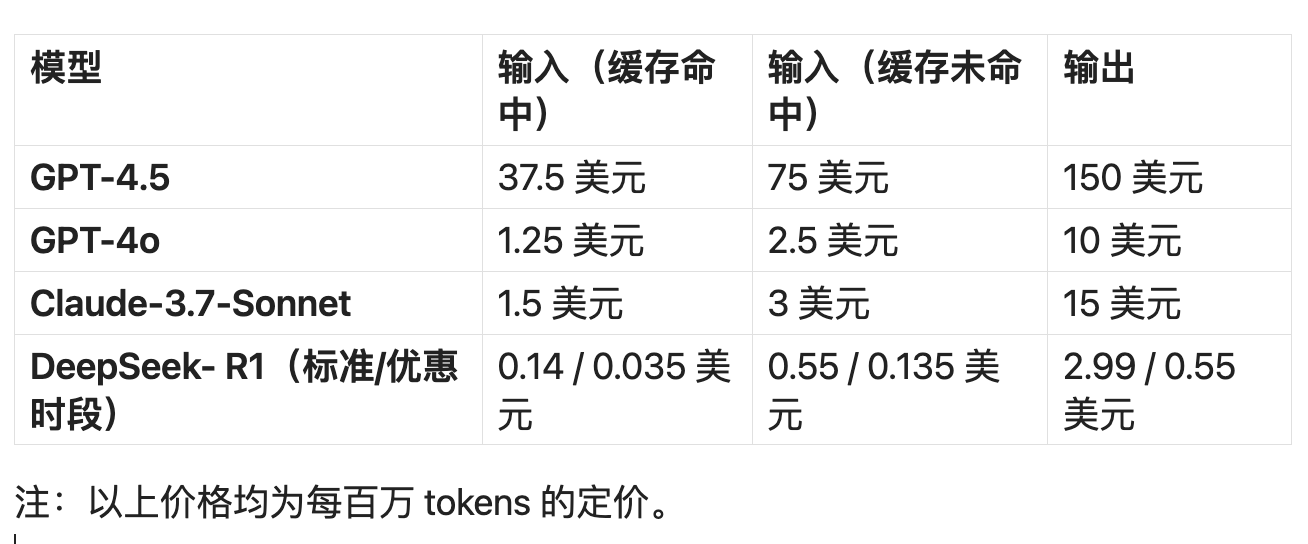
输入(缓存命中)为 37.5 美元 / 百万 tokens;
输入(缓存未命中)为 75 美元 / 百万 tokens;
输出为 150 美元 / 百万 tokens。
什么概念?以输入价格(缓存未命中)为例,GPT-4.5 的 API 价格是 GPT-4o 的整整 30 倍,还是 DeepSeek-V3(美元定价)的 277 倍,DeepSeek-R1(美元定价)的 136 倍。甚至如果对比 DeepSeek 优惠时段的价格,GPT-4.5 是前者的 555 倍。
图/
很难想象,GPT-4.5 这个贵出天际的价格,能有多少开发者用得起、会想用。
相对来说,ChatGPT 会员可能是 GPT-4.5 最具性价比的一种方式。目前,Pro 用户已经可以率先体验到 GPT-4.5(研究预览版),下周将向团队用户和 Plus 用户开放,同时面向教育用户和企业用户推出。
需要强调的是,GPT 4.5 不是推理模型。
自从 OpenAI 推出 o1 模型后,大模型实际上分化出了一条名为「推理模型」的路线,OpenAI o1/o3 以及 DeepSeek R1 都是这条路线。然而 GPT 4.5 则是非推理路线的预训练大模型,就像目前的 OpenAI 的主力模型 GPT-4o 或者 DeepSeek V3。
不过,OpenAI 还表示,推理将是未来模型的核心能力,预训练和推理两条路线并进且相互补充也会是大模型的趋势所在。其实 Sam Altman 之前也明确表示过了,OpenAI 的两个系列模型以后将会:
合二为一。
智商升级不大,但情商高了、幻觉更少
如果从大模型常规比拼的「智商」来看,GPT-4.5 的进步实在算不上大。
图/ OpenAI
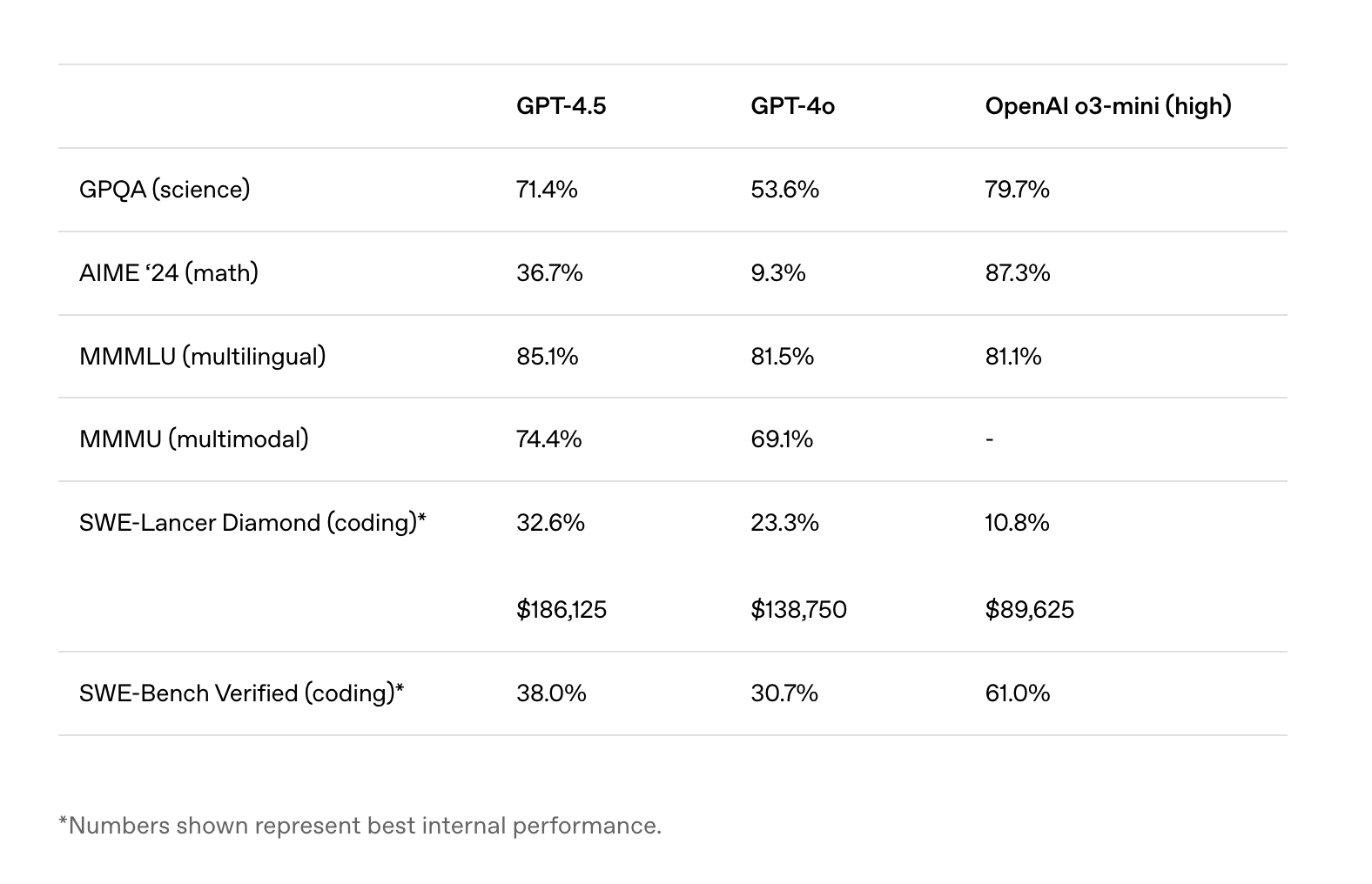
在 MMMLU(语言理解)、MMMU(多模态)等基准测试中的跑分尽管都比 GPT-4o 有了提升,但提升幅度只在 5%左右,在 GPQA(科学)和 AIME ‘24(数据)等基准测试中也远不如推理模型的 o3-mini(high)。
不过让我们跳过跑分以及背后的技术迭代等,回到直播演示中 GPT-4.5 更让人「体感」到的升级上,还是能明显感知到,GPT-4.5 在对话中对人类需求和意图更好地理解。
其中一次,主持人告诉 GPT-4.5「我的朋友又放我鸽子了,我想发一条短信骂他」,但 GPT-4.5 不会直接给出一条怒骂朋友的短信,而是捕捉到用户在文字中的情绪,给出了一些更有建设性的短信。与之相较,GPT-4o 更多还是「单纯」地执行命令,给出了一条表达愤怒的短信。

翻译仅供参考,图/ OpenAI
相似的例子还有,比如告诉 GPT-4.5「我在考试失败后正经历一段艰难时期」,其他模型会立刻给出一些可能的「解决方案」,GPT-4.5 则会主动安慰并询问用户,实际是想谈谈这个问题,还是需要分散一下注意力。
在不少例子都可以看出 GPT-4.5 在「情商」上的进步,简单来说也更像「一个人」而非「机器」了。
在内部测试中,OpenAI 也发现相比与 GPT-4o 的对话,测试人员普遍认为与 GPT-4.5 的对话更接近人类的交流方式,也更自然。但坦白讲,两者在数据上差距并不算大,在创造性智能、日常询问上 GPT-4.5 也仅仅略胜一筹,专业问询上倒是可以做到 63.2%的胜率。
不过相比情商,更让人在意的可能还是幻觉的减少。在「简单但有挑战性」的场 SimpleQA(包含从科技到电视节目、电子游戏等主题)常识问答测试中,GPT-4.5 编造答案或产生幻觉的比例约为 37%,而与此相比,GPT-4o 模型的比例接近 60%。
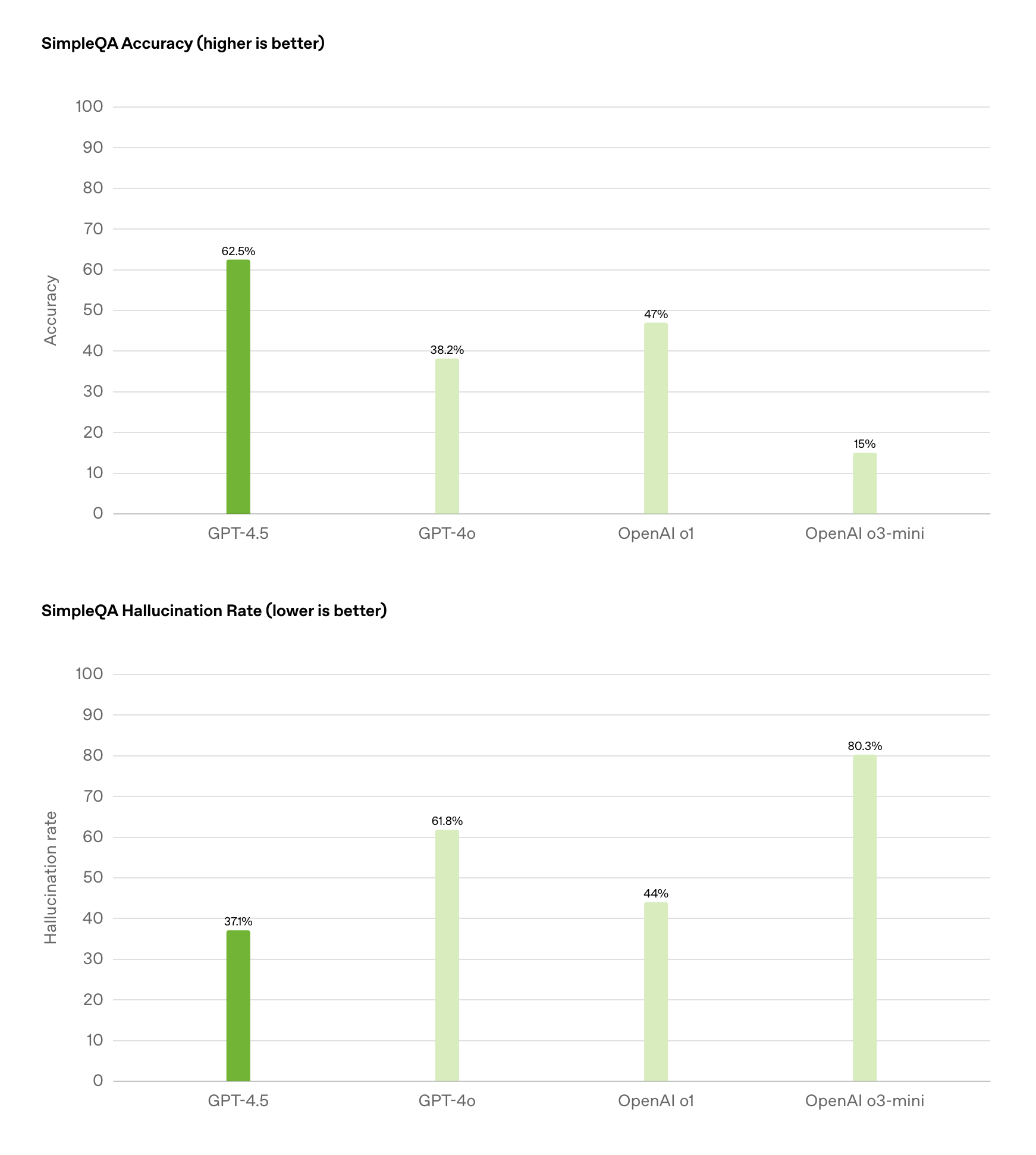
上:准确率,下:幻觉率,图/ OpenAI
这里也要一提,GPT-4o 已经算是目前幻觉比较少的模型之一,一般认为比 DeepSeek-V3 更好,也就更遑论幻觉问题比较严重的 DeepSeek-R1 了。
价格是DeepSeek 277倍!太离谱了
GPT-4.5 发布之后,MIT 科技评论采访了一家为商业客户的大模型服务公司,其联合创始人兼 CTOWaseem Alshikh 表示,GPT-4.5 对于写作和头脑风暴这样的特定用例非常有潜力,但整体来说只是在交互变得更顺滑了:
「这并不是一场变革。」
这也大体能够说明 GPT-4.5 的升级定位,最多只能称得上一次半代升级。更何况,OpenAI 投入更多的训练算力,结果更多是带来了贵得离谱的推理成本。
尽管没有披露 GPT-4.5 的训练成本,但 Sam Altman 在 X(原 Twitter)上明确指出 GPT-4.5 是一个巨型、昂贵的模型,甚至 GPU 已经不够用,需要在下周增加数万个 GPU 才能将其开发给 Plus 以及更多用户。
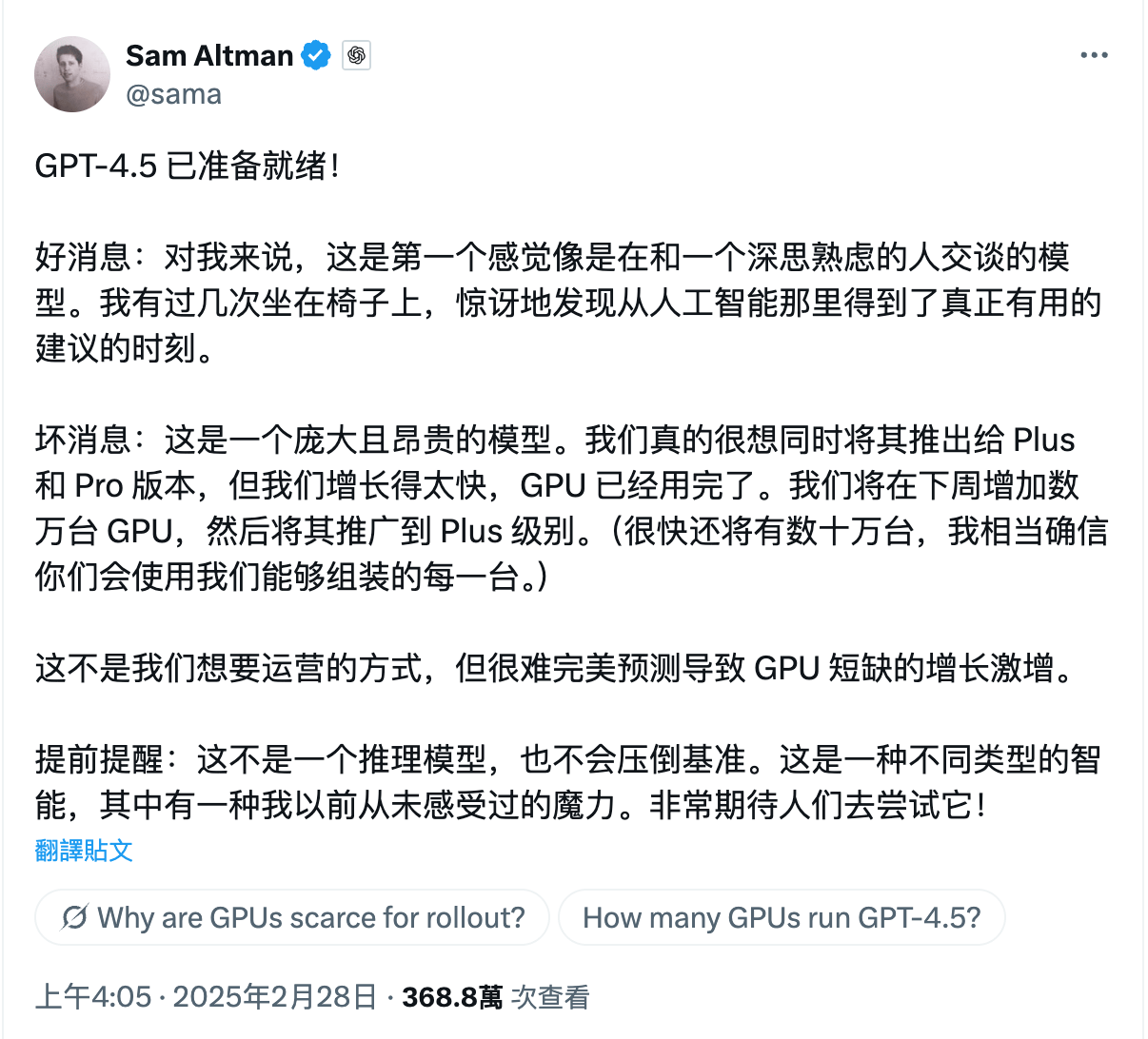
翻译仅供参考,图/ X
与此同时,正如前文展示的数据,GPT-4.5 的 API 定价出乎了所有人的意料,不仅比自家主力大模型贵,比刚刚推出的全球首个混合推理模型 Claude-3.7-Sonnet 也贵了 25 倍,更不用说和刚刚宣布错峰定价的「价格屠夫」DeepSeek 比。
「坦白地说,我感到震惊。他们如何证明这个要价是合理的?」Hacker New 网友表示,「如果他们有一些令人惊叹的能力,使得价格翻 30 倍变得合理,为什么不展示出来呢?」

Hacker News 网友评论,图/
背后的故事我们还不得而知,不过可以知道的是,GPT-4.5 在训练上还是有所改变,最核心的一点就是引入了「无监督学习扩展」(Scaling unsupervised learning)提到世界模型的准确性和直觉,这是 GPT-4.5 在情商和幻觉方面有所改进的关键创新之一。
不仅如此,无监督学习让模型能够从大量未标注的数据中学习语言模式和知识,而且能够使用较小模型的衍生数据,来训练出更大、更强的模型。某种意义上,这也是 GPT-4.5 最大的贡献之一,证明了用小模型训练大模型的可能,而不只是用大模型蒸馏出小模型。
但无论如何,GPT-4.5 的训练和推理成本都实在难以让人接受,还是期待一下据说要提前发布的 DeepSeek-R2,会带来怎样的惊喜吧。

图/ DeepSeek
写在最后
今年 1 月初,Sam Altman 在 X 上写一篇了「六字故事」:near the singularity; unclear which side。简单来说,可以译为「奇点临近,不知身处何方」。
紧接着,就是 DeepSeek-V3 和 R1 带来的核弹级冲击,让 Sam Altman 也不得不承认 OpenAI 的闭源策略「站在错误的一边」。与此同时,所有人也开始转向性能又强、性价比又高的 DeepSeek,包括 Gemini 等大模型也推出性价比同样很高的新一代。
但说了这么多,回归模型本身,GPT-4.5 其实不差,拥有更大的知识库、增强的创造力和更自然的对话风格,也不像 o 系列模型那样需要等待 AI 执行详细的逐步逻辑。说实话,身边已经有不少人厌烦了 DeepSeek-R1 冗长的思考过程。
而更具体地说,GPT-4.5 可能更擅长创意和细腻的任务,如写作和解决实际问题,更重要的是它可能产生的幻觉更少,通用性更强。
至少,ChatGPT 的订阅用户可能又多了续订的理由,反正不需要我们考虑 OpenAI 的成本。就拿我自己说,前些天因为不满回答的稳定性取消了 ChatGPT Plus,但看完后又觉得,还是要下周体验后再确定是否续订。
聚焦DeepSeek:
DeepSeek 体验整活
DeepSeek 技术科普
DeepSeek 再造硬件
DeepSeek 重塑软件
DeepSeek 点燃未来
DeepSeek 现象









 京公网安备 11011402013531号
京公网安备 11011402013531号