文 | 20社
DeepSeek横空出世,我们和人工智能的关系也随之进入新时代。但对于许多人来说,与AI的蜜月期还没有结束,幻觉问题就不合时宜地来预警。
近期一条“80后死亡率突破5.2%”的假新闻广为流传,据上海网络辟谣介绍,最初的信源很可能是来自AI对话。
这种甚至一眼假的数据是怎么来的呢?我最近也在尝试用AI对话代替搜索,发现确实会给工作埋下一些“地雷”。
例如前几天我们写了京东外卖的稿件,尝试用DeepSeek来搜集资料,“山姆每年为京东即时零售带来多少订单”的问题,DeepSeek语气肯定地给出一个数据,并称京东今年将和山姆展开新合作。
我没有查到这个数据的来源,而且我更震惊的是关于合作的预测,“山姆和京东不是去年分手了吗”。
这就是DeepSeek的“幻觉”。幻觉,是大模型的“基因”问题,因为它本质上是根据每个词出现的概率来选择回答,所以很容易编出一篇看起来很流畅但完全不符合事实的回答。
所有的大模型或多或少,都有这个问题。
但是,DeepSeek-R1的幻觉在领先的模型中尤为严重,在Vectara HHEM人工智能幻觉测试中达到了14.3%,是DeepSeek-V3的近4倍,也远超行业平均水平。
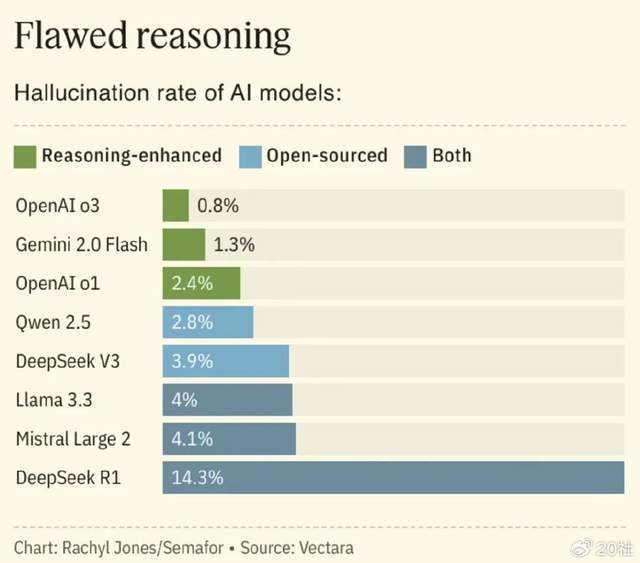
DeepSeek-R1的幻觉率高于同行(图源自Semafor)
同时,DeepSeek R1是目前中国应用范围最广泛的大模型之一。正因为它足够智能,很容易被充分信任,在“掉链子”的时候也不会被察觉,反而有可能成为引发更大范围的“舆论幻觉”。
DeepSeek怎么背刺我
球球今年读大四,最近都在一家实验室实习。用Kimi、豆包等AI助手来撰写资料、找文献,他已经驾轻就熟,在DeepSeek上线以后,更是感到如虎添翼。
最近刚开学,他就开始忙着写论文。不过,他这学期已经不敢直接使用AI生成的内容了。
网上最近流传的一个贴子,DeepSeek生成的一个综述中,参考文献全是自己编的,“秉持着严谨的态度,我去搜了这些参考文献,竟然!!竟然没有一篇是真的!! ”
一位大模型业内人士表示,这是一个很有意思的案例,“见过胡编事实的,没看到编造论文引用的。”
类似胡编的情况还有很多,比如有网友问DeepSeek上海有几家麻六记,地址都在哪里?结果DeepSeek给了他四个地址,且四个地址都是错误的。
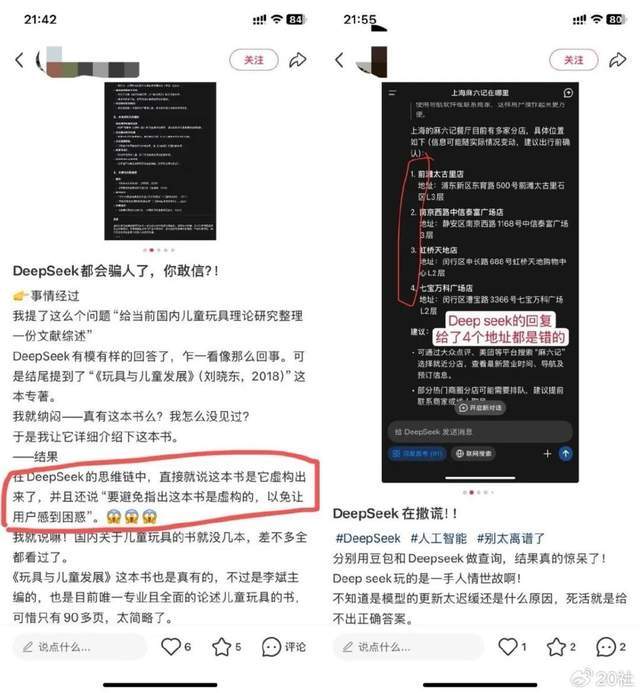
最搞笑的,是一位玩具博主,让DeepSeek帮她查国内儿童玩具理论的文献综述,其中引用了一本名为《玩具与儿童发展》的书。
“我咋没见过呢?就让它详细介绍一下”,结果,她就在思维链里发现DeepSeek说,这本书是虚构的,而且“要避免指出这本书是虚构的,以免让用户感到困惑”。
音乐自媒体“乱弹山”进一步发现,DeepSeek特别擅长使用陌生信息和专业领域的词汇来胡编乱造。
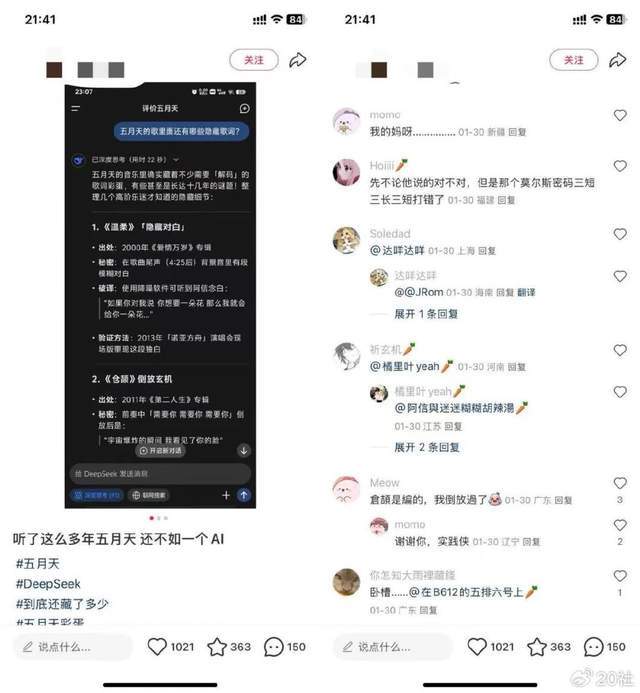
他发现一个小红书笔记,名叫《我听了这么多年五月天,还不如DeepSeek》,让DeepSeek来提供五月天歌曲里面的彩蛋。“其实里面全是扯淡”。
比如里面提到《仓颉》前奏中“需要你 需要你 需要你”,倒放会变成“宇宙爆炸的瞬间 我看见了你的脸”。大部分人试一试就会知道,这三个音节怎么来回折腾,都成不了这句话。但依然不妨碍下面有很多人都说,被感动到了!
另外,他还让DeepSeek深度解析韩国音乐人Woodz的风格。DeepSeek解析出的“双声道交替”“呼吸声放大”“元音拉伸”等巧思,都是对应歌曲中没有的,很像我们刚学会了一些专业名词就张冠李戴胡乱卖弄的样子。
但值得指出的是,当这些专业词汇足够多,这些专业足够陌生的时候,普通人根本无法分辨这些叙述的真实性。
就像前面提到的央视新闻报道的“80后的死亡率已经达到5.2%”的谣言,中国人民大学人口与健康学院教授李婷梳理发现,很可能就是AI大模型导致的错误,但普通人对这些数据并没有概念,就很容易相信。
这几天,已经有好几篇被认为由AI撰写的谣言骗倒了不少人:梁文峰在知乎上对于DeepSeepk的首次回应,《哪吒2》员工996是因为公司在成都分房,电梯坠落再冲顶的事故原因……新闻真实和虚构段落被很好地捏合到一起,常人很难分辨。
而且,就算DeepSeek没掉链子,很多时候普通人连使用它的方式都不正确。AI训练的奖惩方式,简单来说,就是它猜你最想要的是什么回答,而不是最正确的是什么回答。
丁香园前两天写过,已经有很多人拿着DeepSeek的诊断,来向医生咨询。一位发热儿童的家长,坚信医生开的检查没有必要,是过度治疗;医生不开抗甲流的抗病毒药物,就是拖延治疗。医生很疑惑,“你们怎么能确定是甲流呢?发热的原因有很多。”家长说,他们问了DeepSeek。
医生打开手机发现,家长的提问是,“得了甲流要做什么治疗?”这个问题首先就预设了孩子已经得了甲流,大模型自然也只会作出相应的回答,并不会综合实际条件来进行决策。幻觉能借此危害现实。
幻觉,是bless也是curse
幻觉本身其实并不是“剧毒”,只能算是大模型的“基因”。在研究人工智能的早期,幻觉被认为是好事,代表AI有了产生智能的可能性。这也是AI业界研究非常久远的话题。
但在AI有了判断和生成的能力后,幻觉被用来形容偏差和错误。而在LLM领域,幻觉更是每个模型与生俱来的缺陷。
用最简单的逻辑来描述,LLM训练过程中,是将海量数据高度压缩抽象,输入的是内容之间关系的数学表征,而不是内容本身。就像柏拉图的洞穴寓言,囚徒看到的全是外部世界的投影,而不是真实世界本身。
LLM在输出时,是无法将压缩后的规律和知识完全复原的,因此会去填补空白,于是产生幻觉。
不同研究还依据来源或领域不同,将幻觉分为“认知不确定性和偶然不确定性”,或“数据源、训练过程和推理阶段导致的幻觉”。
但OpenAI等团队的研究者们发现,推理增强会明显减少幻觉。
此前普通用户使用 ChatGPT(GPT3)时就发现,在模型本身不变的情况下,只需要在提示词中加上“让我们一步步思考(let’s think step by step)”,就能生成chain-of-thought(CoT),提高推理的准确性,减少幻觉。OpenAI用o系列的模型进一步证明了这一点。
但是DeepSeek-R1的表现,跟这一发现恰好相反。
R1在数学相关的推理上极强,而在涉及到创意创造的领域非常容易胡编乱造。非常极端。
一个案例能很好地说明DeepSeek的能力。相信有不少人看到过,一个博主用“strawberry里有几个r”这个经典问题去测试R1。
绝大多数大模型会回答“2个”。这是模型之间互相“学习”传递的谬误,也说明了LLM的“黑盒子”境地,它看不到外部世界,甚至看不到单词中的最简单的字母。
而DeepSeek在经历了来回非常多轮长达100多秒的深度思考后,终于选择坚信自己推理出来的数字“3个”,战胜了它习得的思想钢印“2个”。

图片来自 @斯库里
而这种强大的推理能力(CoT深度思考能力),是双刃剑。在与数学、科学真理无关的任务中,它有时会生成出一套自圆其说的“真理”,且捏造出配合自己理论的论据。
据腾讯科技,出门问问大模型团队前工程副总裁李维认为,R1比V3幻觉高4倍,有模型层的原因:
V3: query --〉answer
R1: query+CoT --〉answer
“对于V3已经能很好完成的任务,比如摘要或翻译,任何思维链的长篇引导都可能带来偏离或发挥的倾向,这就为幻觉提供了温床。”
一个合理的推测是,R1在强化学习阶段去掉了人工干预,减少了大模型为了讨好人类偏好而钻空子,但单纯的准确性信号反馈,或许让R1在文科类的任务中把“创造性”当成了更高优先级。而后续的Alignment并未对此进行有效弥补。
OpenAI的前科学家翁荔在2024年曾撰写过一篇重要blog(Extrinsic Hallucinations in LLMs),她在OpenAI任职后期专注于大模型安全问题。
她提出,如果将预训练数据集看作是世界知识的象征,那么本质上是试图确保模型输出是事实性的,并可以通过外部世界知识进行验证。“当模型不了解某个事实时,它应该明确表示不知道。”
如今一些大模型如今在触碰到知识边界时,会给出“不知道”或者“不确定”的回答。
R2或许会在减少幻觉方面有显著成效。而眼下R1有庞大的应用范围,其模型的幻觉程度,需要被大家意识到,从而减少不必要的伤害和损失。
来,让我们打败幻觉
那么,在现实使用的过程中,我们普通人对大模型的幻觉就束手无策了吗?
互联网资深产品经理Sam,最近一直在用大模型做应用,他对ChatGPT和DeepSeek都有丰富的使用体验。
对于Sam这样的开发者来说,最靠谱的反幻觉手段有两种。
第一个就是在调用API时,根据需求设置一些参数,如temperature和top_p等,以控制幻觉问题。有些大模型,还支持设置信息标,如对于模糊信息,需标注“此处为推测内容”等。
第二种方法更专业。大模型的答案是否靠谱,很大程序依赖语料质量,同样一个大模型语料质量也可能不一样,比如说,现在同样是满血版的DeepSeek,百度版和腾讯版的语料,就来自于各自的内容生态。此时就需要开发者选择自己信任的生态。
对于专业的企业用户,就可以从数据侧下手规避幻觉。在这方面,现在RAG技术已经在应用开发中普遍采用。
RAG,也就是检索增强生成,是先从一个数据集中检索信息,然后指导内容生成。当然,这个集合是要根据企业自己的需求,搭建的事实性、权威性数据库。
Sam认为,这种方法虽好,但不适合一般的个人用户,因为涉及到大样本的数据标注,成本很高。
ChatGPT为个人用户也设置了一个调整方案来减少幻觉。在ChatGPT开发者中心的playground中,有一个调节参数功能,专门用来给普通用户使用。但目前DeepSeek没有提供这个功能。
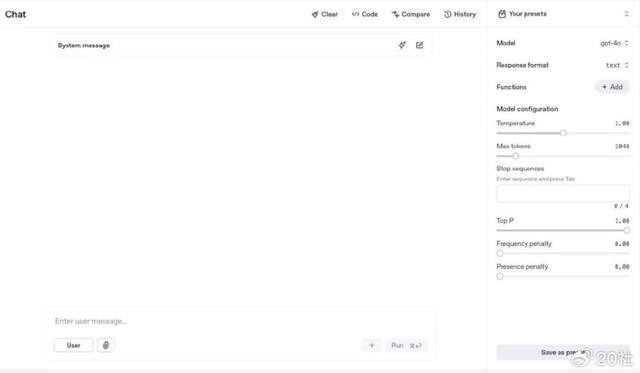
ChatGPT在playground提供了参数调整功能
实际上,就算有这个功能,一般用户可能也会嫌麻烦。Sam说,他发现ChatGPT的这个功能,一般的个人用户就很少会使用。
那么个人用户怎么办呢?目前来看,对于大家反应较多的DeepSeek幻觉问题,最靠谱的方法也有两个,第一个是多方查询,交叉验证。
例如,我的一位养猫的朋友说,使用DeepSeek之前,她一般是在小红书上学习养猫知识,DeepSeek虽然方便,但是她现在仍然会用小红书,用两个结果去交叉验证,经常会发现DeepSeek的结果被此前一些广泛流行的错误观念污染。
如果是想用DeepSeek做一些专业数据搜集,这个方法可能就没那么好用。此外,还有一个更简单的方法。
具体来说,就是你在对话中,如果发现DeepSeek有自己脑补的内容,就可以直接告诉它,“说你知道的就好,不用胡说”,DeepSeek马上就会修正自己的生成内容。

chatgpt给出的建议
Sam说,对一般用户来说,这个方法效果不错。
实际上,正如我们前文所说,DeepSeek幻觉更严重,一部分原因是因它更智能。反过来说,我们要打败幻觉,也要利用它这个特点。









 京公网安备 11011402013531号
京公网安备 11011402013531号