DeepSeek 开源周第四天的开源项目如约而来,今天 DeepSeek 一共带来了三个优化并行训练的核心项目:
DualPipe:用双向流水线并行算法实现计算通信重叠EPLB:提升分布式训练效率的专家并行负载均衡器profile-data:提供 V3/R1 模型的性能分析数据
什么是并行计算?
比如你开了一家餐厅,突然来了100个客人点单。
如果只有1个厨师做饭,可能要忙到半夜。这时你找了5个厨师,把菜单拆成20份,每人负责20道菜,这就是并行计算:把大任务拆成小任务,多人同时处理,效率翻倍。
但问题来了,如果有个厨师分到了佛跳墙这种复杂菜,而其他厨师分到拍黄瓜,前者累到虚脱,后者闲到玩手机——这就是负载不均衡。

而 DeepSeek 今天的开源项目就是为了解决并行问题,同时解决负载不均衡。
DeepSeek:为“厨房”安装智能流水线
DeepSeek最新开源的DualPipe和EPLB项目,就像给后厨装上了“智能调度系统+动态菜谱分配器”:
双向流水线(DualPipe):切菜工切完第1道菜的食材,立刻传给炒菜工,同时自己开始切第2道菜——实现切菜与炒菜的全重叠。
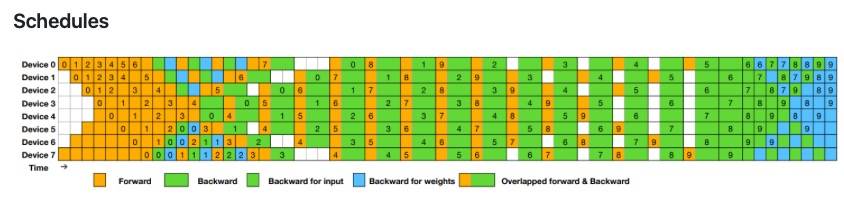
动态专家调度(EPLB):当佛跳墙订单暴增,系统自动复制该菜谱给其他厨师,并优先分配给空闲灶台(GPU),避免“专家过劳” 。

有了这两个技术,DeepSeek AI 相比竞品方案可减少高达 11 倍的计算资源需求,避免采购昂贵的硬件集群,实现硬件开支与运维成本的双重降低。在保持训练效率的同时规避了规模扩张带来的资源黑洞。模型体积的指数级增长不再伴随算力需求的同步激增。
这是资源榨取的终极技术。
效率至上,DeepSeek 的新方法
在与OpenAI、Google、meta等巨头的竞争中,DeepSeek AI选择了"效率至上"的差异化路径:当竞争对手依赖天价的Nvidia H100集群彰显实力时,DeepSeek通过算法优化将"性能受限"的H800 GPU转化为高效算力单元。
DualPipe与EPLB的组合拳,使得用1/5硬件资源实现同等训练突破成为可能。这场算力竞赛正在改写规则——不再是硬件堆砌的蛮力比拼,而是算法创新的智慧较量。如同大卫用弹弓战胜巨人歌利亚,只不过这次战场换成了GPU阵列。







 京公网安备 11011402013531号
京公网安备 11011402013531号