前几周分享来自清华的五部 DeepSeek 攻略之后,北大的肖睿团队也出品了两份 DeepSeek “内部秘籍”,这就 赶紧来给大家分享。
可能有的家友对什么是 DeepSeek?它有什么用?仍感到一头雾水。
就让我们回归基础,从大语言模型的基础流程、能力边界与适用场景看起。
对了,这次给大家分享的 PDF 下载,是原汁原味的原版哦,网上有太多卖课者魔改的内置其广告版本。
01.
从大模型基础讲起
第一份秘籍 《DeepSeek 与 AIGC 应用》,就是来为 没有专业的 AI 或 IT 技术背景的我们,解答 DeepSeek 是什么,有什么用的问题。

我们常听到的 GPT 一词,其实就是生成式预训练变换器(Generative Pre-trained Transformer)的简写。
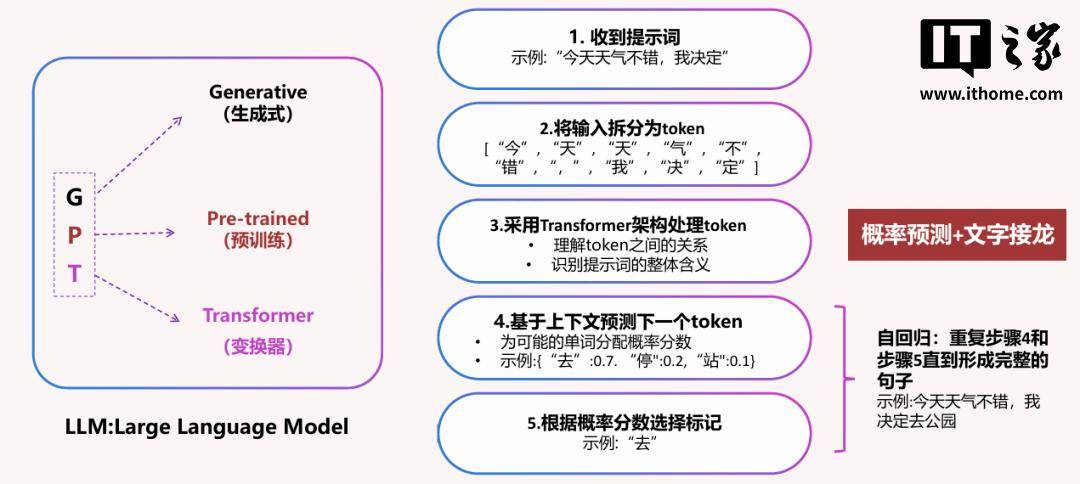
其基本工作流程是:
收到提示词
将输入拆分为 token
利用 Transformer 架构处理 token
基于上下文 预测下一个 token
根据概率分数选择 token
自回归:重复步骤 4 和 5 ,直到形成完整的句子
看到上面的工作流程后,我们面对大模型“吐”出的结果时,也就不会感到奇怪了。
其优势在于,具有语言理解和生成能力、世界知识能力,以及一定的推理能力。
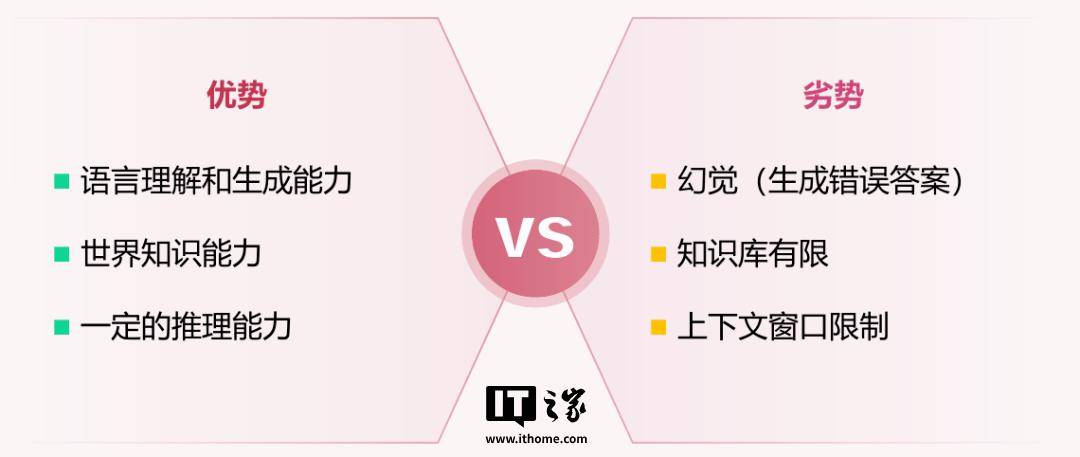
相对应而言,其劣势便在于 AI 幻觉、有限的知识库及上下文窗口限制。
了解完原理,我们也就能让这些聊天机器人更好地为我所用。
02.
拥抱 AIGC 的未来
我们在使用这些 AI 大模型工具的时候,需要注意其能力边界的限制。
比如,GPT-3.5 与 GPT-4 的 上下文长度只有几千个字。
当需要连续处理长篇幅的文本时,我们就需要使用 分段对话、定期总结、使用关键词提醒及精简输入的技巧,时刻关注大模型有没有遗漏自己所关注的上下文。

在文本分析领域,它更擅长文本统计、摘要生成、分类与总结,而面对 知识更新、语境歧义、新颖和未知类别时,表现可能就没那么理想。

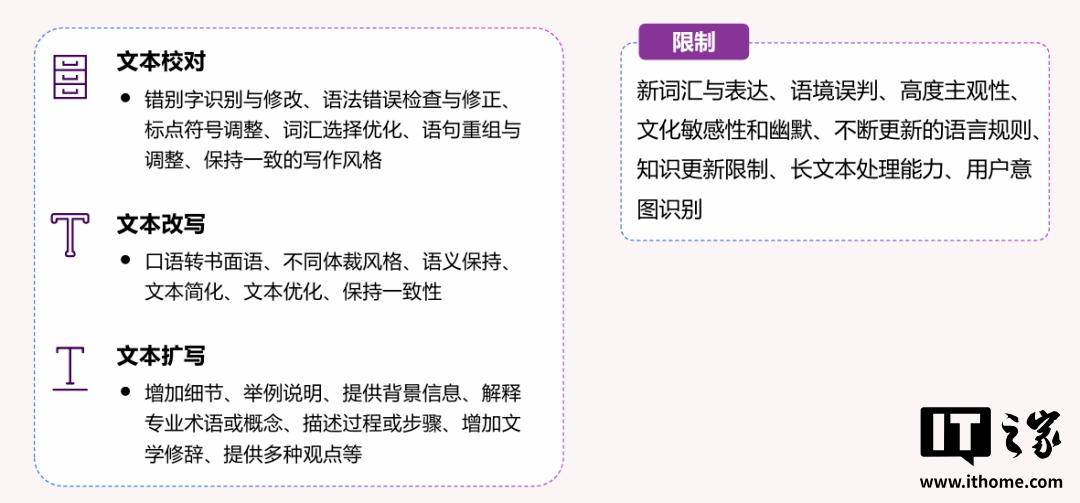
在面对 新词汇与表达、语境误判、不断更新的语言规则时,大模型也只能表示:“这我都没训练过啊!”
03.
拥抱 AIGC 的未来
了解完一些基础之后,我们对于大模型能干什么,会有更加深入的理解。
目前面向普通用户开放商用的 AIGC 工具,主要有以下几个方向:
聊天对话机器人
图像生成工具
音频工具
视频生成工具
搜索工具
就以目前火热的聊天机器人来看,DeepSeek-R1 的主要优势还在于 强大的推理能力,但其并不具备多模态的能力,无法直接处理图像、音频等信息。
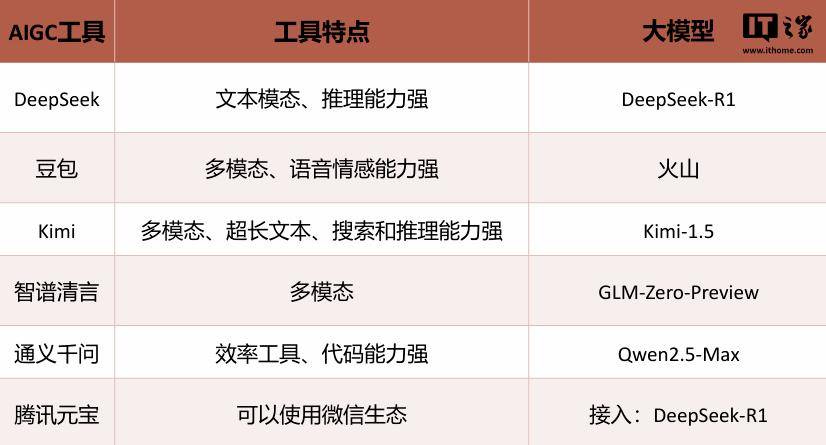
而豆包则拥有更出众的多模态能力,其语音情感交互能力更适合日常休闲对话。
比如当我们想要制作 PPT 时,就可以 使用 DeepSeek R1 完成大纲设计,最后再来通过 Kimi 生成。

由于 AI 行业日新月异的发展,上面的列表随时都可能发生变化,我们也需要根据自己的需求和目标, 持续更新自己的 AI 工具列表。

04.
DeepSeek R1 提示词技巧
来自北大的第二篇 秘籍 《DeepSeek 提示词工程和落地场景》,则更专注于 DeepSeek R1 使用过程中的提示词技巧。

作为一款 CoT 思维链(Chain-of-Thought)模型,我们可能需要放弃传统的提示词习惯,可以直接“把 AI 当人看”:
我要(做)XX,要给 XX 用,希望达到 XX 效果,但担心 XX 问题

此外,我们还可以学会 “反向 PUA” DeepSeek,让它通过自己的思考逻辑,输出更好的结果。

这份文档中还给出了市场营销、公文写作、编程开发、数据分析、会议纪要、学术研究等多领域的的用法示例,等待大家去发现。









 京公网安备 11011402013531号
京公网安备 11011402013531号