
网 乐天 2月25日
AI公司Anthropic今日宣布推出 Claude 3.7 Sonnet1,这是Anthropic迄今为止最智能的模型,也是市场上第一个混合推理模型。
Anthropic称,Claude 3.7 Sonnet 可以产生近乎即时的响应或向用户展示的扩展的、逐步的思考。API 用户还可以对模型的思考时间进行细粒度控制。
PK OpenAI与DeepSeek R1
Anthropic新模式的目标是PK OpenAI o1和OpenAI o3-mini、DeepSeek R1、Grok 3 Beta。
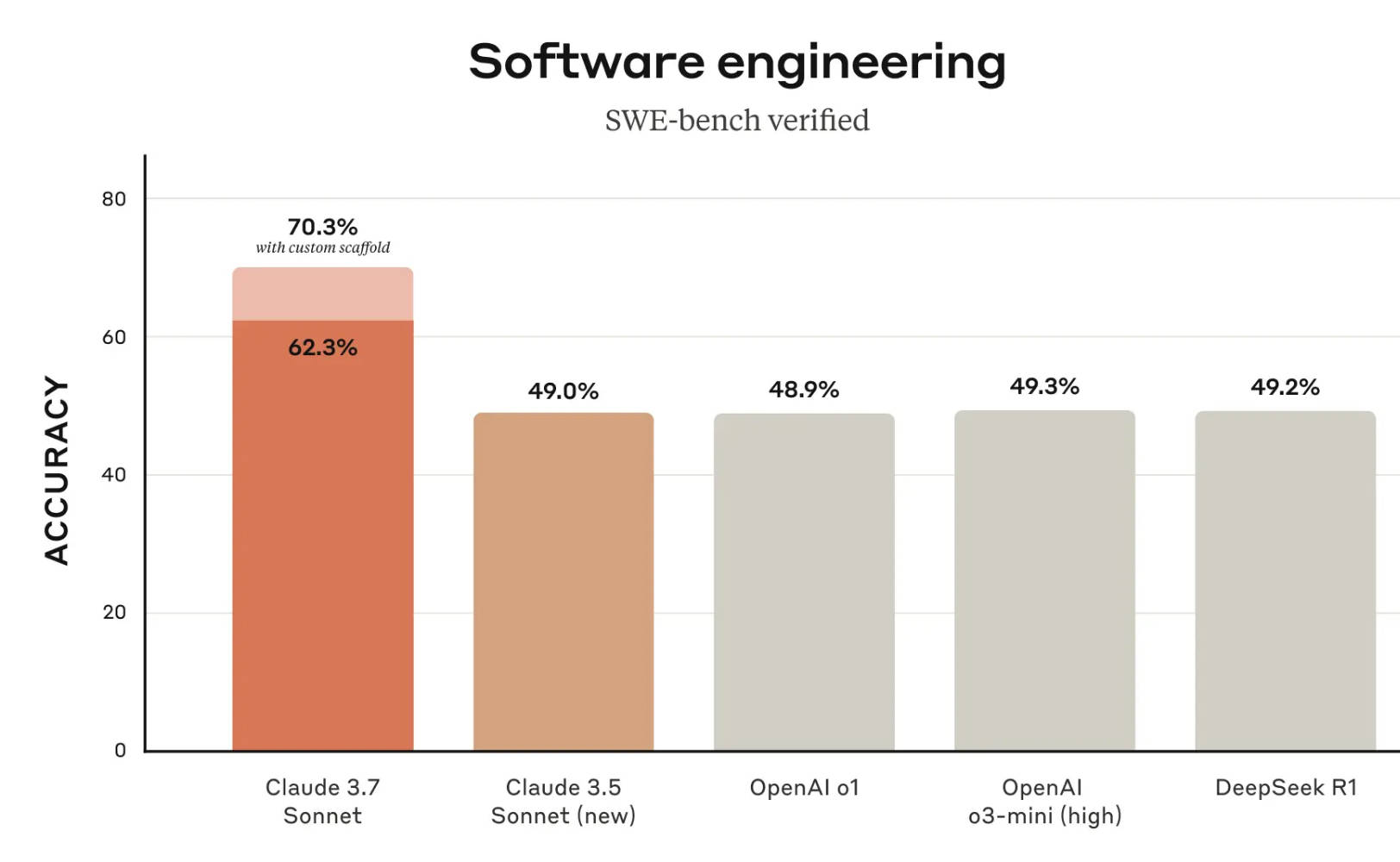
据介绍,Claude 3.7 Sonnet 在编码和前端 Web 开发方面表现出很大改进。除了该模型外,Anthropic还推出了用于代理编码的命令行工具 Claude Code。Claude Code 可作为有限的研究预览版使用,并允许开发人员直接从他们的终端将大量工程任务委托给 Claude。
Claude 3.7 Sonnet 现已在所有 Claude 计划(包括免费版、专业版、团队版和企业版)以及 Anthropic API、Amazon Bedrock 和 Google Cloud 的 Vertex AI 上提供。除免费 Claude 层外,所有界面都提供扩展思考模式。
在标准和扩展思维模式下,Claude 3.7 Sonnet每百万输入令牌收费3美元(这意味着可以以3美元的价格在Claude中输入大约 750,000 个单词),每百万输出令牌收费15美元。
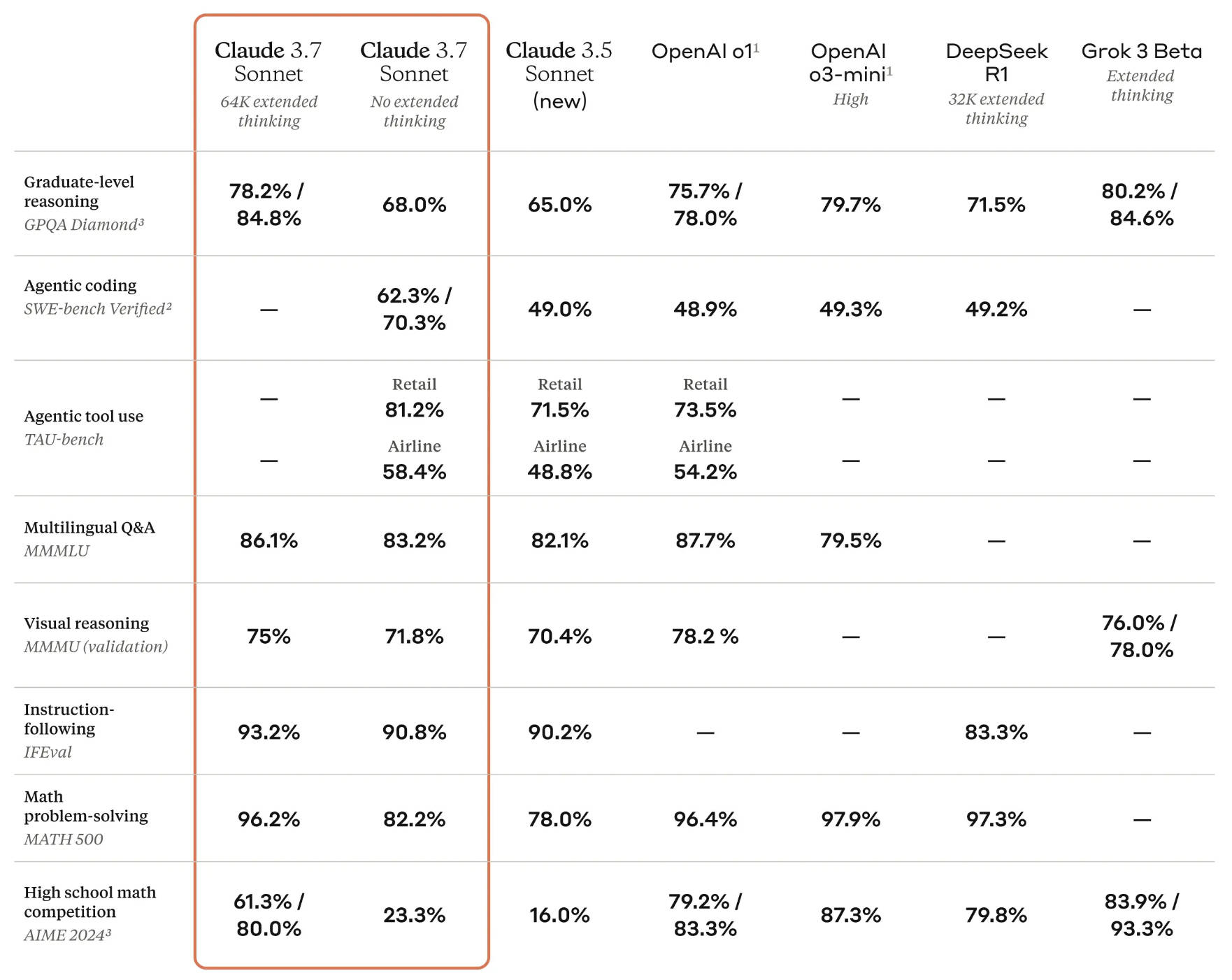
这使得它比OpenAI 的 o3-mini(每 100 万个输入令牌1.10美元/每 100 万个输出令牌 4.40 美元)和 DeepSeek 的 R1(每 100 万个输入令牌 55 美分/每 100 万个输出令牌2.19美元)更昂贵,但o3-mini 和 R1 是严格的推理模型 - 而不是像 Claude 3.7 Sonnet 这样的混合模型。
Claude 3.7 Sonnet:前沿推理变得实用
Anthropic称,其开发 Claude 3.7 Sonnet 的理念与市场上其他推理模型不同。正如人类使用单个大脑进行快速反应和深度思考一样,Anthropic认为推理应该是前沿模型的综合能力,而不是完全独立的模型。

Claude 3.7 Sonnet以多种方式体现这一理念。首先,Claude 3.7 Sonnet 既是普通的 LLM,又是推理模型:您可以选择何时希望模型正常回答,何时希望它在回答之前思考更长时间。在标准模式下,Claude 3.7 Sonnet 是 Claude 3.5 Sonnet 的升级版。在扩展思考模式下,它会在回答之前进行自我反思,从而提高其在数学、物理、遵循指令、编码和许多其他任务上的表现。我们通常发现,在两种模式下,提示模型的工作方式类似。
其次,当通过API使用 Claude 3.7 Sonnet 时,用户还可以控制思考的预算:可以告诉Claude思考不超过 N个标记,对于任何 N 值,其输出限制为128K个标记。这允许您在速度(和成本)和答案质量之间进行权衡。
第三,在开发Anthropic的推理模型时,Anthropic对数学和计算机科学竞赛问题的优化较少,而是将重点转向更能反映企业实际使用 LLM 方式的现实任务。
———————————————
由媒体人雷建平创办,若转载请写明来源。








 京公网安备 11011402013531号
京公网安备 11011402013531号