AI大模型竞赛愈发白热化,下半场将聚焦推理与数据。
2月23日,马斯克点赞了一条关于AI模型竞争路线的分析,他称赞道“分析得很好”,值得一提的是,上周马斯克旗下xAI正式发布Grok 3大模型。
这篇推文是由Gavin Baker发布,他在文章中表示,AI产业格局的变革正在加速,OpenAI的先发优势消退,微软也选择后撤一步。
Gavin还预计,未来数据成为竞争核心,无法获得独特、有价值数据的前沿模型是历史上贬值最快的资产。meta等巨头通过数据垄断和算力规模构建护城河,而中小玩家聚焦差异化部署和成本优化。
不过,Gavin仍看好xAI和OpenAI,他表示,如果OpenAI在5年后仍然是该领域的领导者,那可能是因为先发优势和规模优势,以及产品影响力。
OpenAI的先发优势消退,微软也选择后撤一步
Gavin在推文中指出:
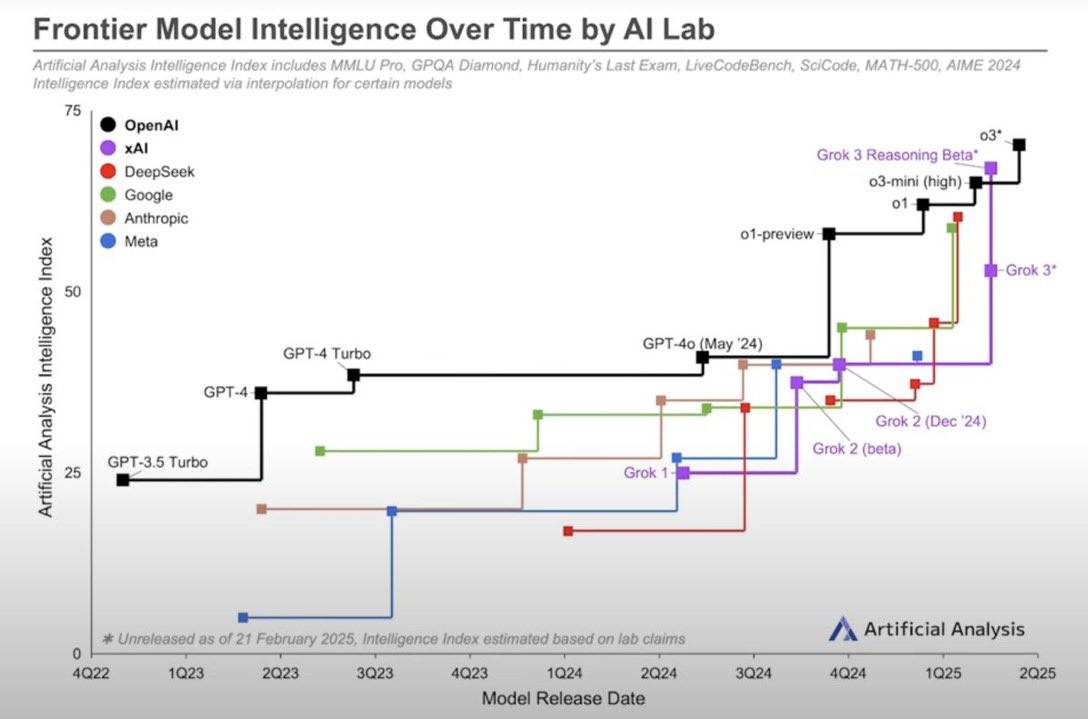
当ChatGPT在2022年11月横空出世时,OpenAI通过激进押注Scaling Law,在生成式AI领域建立了长达7个季度的统治地位。但这一优势窗口正在关闭:Google的Gemini、xAI的Grok-3,以及Deepseek的最新模型,均已达到与GPT-4相近的技术水平。
就连OpenAI创始人Altman也指出,OpenAI未来的领先优势将更加狭窄;微软CEO纳德拉基本上表示,他们在模型能力方面领先的独特时期即将结束。
据The Information此前报道,微软内部备忘录显示,由于预训练边际效益递减,原计划投入160亿美元升级预训练基础设施的方案已被叫停,微软转而专注于为OpenAI提供推理以获取收益。
纳德拉也在此前的播客节目中表示,数据中心可能建设过剩,租赁优于自建,微软甚至可能会使用开源模型来支持 CoPilot。Gavin认为,这些预示着单纯依靠参数扩张建立壁垒的“预训练时代”已走向终结。
独家数据资源成为护城河
Gavin认为,当模型架构趋同,独家数据资源成为护城河。
Gavin在推文中表示:
我多次转述EricVishria的话,无法获得独特、有价值数据的前沿模型是史上贬值最快的资产,而蒸馏只会放大这一点。
如果未来前沿模型无法访问 YouTube、X、TeslaVision、Instagram 和 Facebook 等独特而有价值的数据,则可能没有任何投资回报率。
从这个角度来看,扎克伯格的策略似乎也要明智得多。独特的数据可能最终成为预训练数万亿或千万亿参数模型差异化和 ROI 的唯一基础。
这解释了为何扎克伯格将meta的AI战略锚定在社交数据闭环,据媒体此前报道,Instagram用户的图像标注数据,使meta的多模态模型训练效率提升40%。
巨型数据中心只需2-3个,推理所需算力占95%
这一变化也将带来AI基础设施格局的颠覆性变化,Gavin预计,
预训练算力:需超大规模集群(10万卡级),但参与者将缩减至2-3家,技术堆栈追求极致性能(液冷、核能供电),这一中心堪比“法拉利”级超算中心。
推理算力:较小的6-10家数据中心,分布式、低成本架构主导,地理就近部署与能效比成关键,使用风/光能源,基于量化压缩技术(如Deepseek R1的1-bit LLM)支撑低成本推理,是“本田”级边缘节点。
Gavin强调,推理模型是极其计算密集型的,具备强大的计算能力,模型才能高效地完成推理任务。但与之前那种预训练和推理阶段计算资源分配大致各占一半的情况不同,现在会变成预训练占 5%,推理阶段占95%。卓越的基础设施将至关重要。
整体来看,未来AI行业可能呈现“预训练集中化,推理去中心化”的两极格局,数据成为权力核心,巨头通过数据垄断和算力规模构建护城河,而中小玩家聚焦差异化部署和成本优化。









 京公网安备 11011402013531号
京公网安备 11011402013531号