, 我们又在第一时间拿到了清华大学沈阳团队的新 DeepSeek 攻略,赶紧来给大家分享。
不知道家友们在使用 DeepSeek 等大语言模型的时候,有没有遇到过“一本正经的胡说八道”的情况?
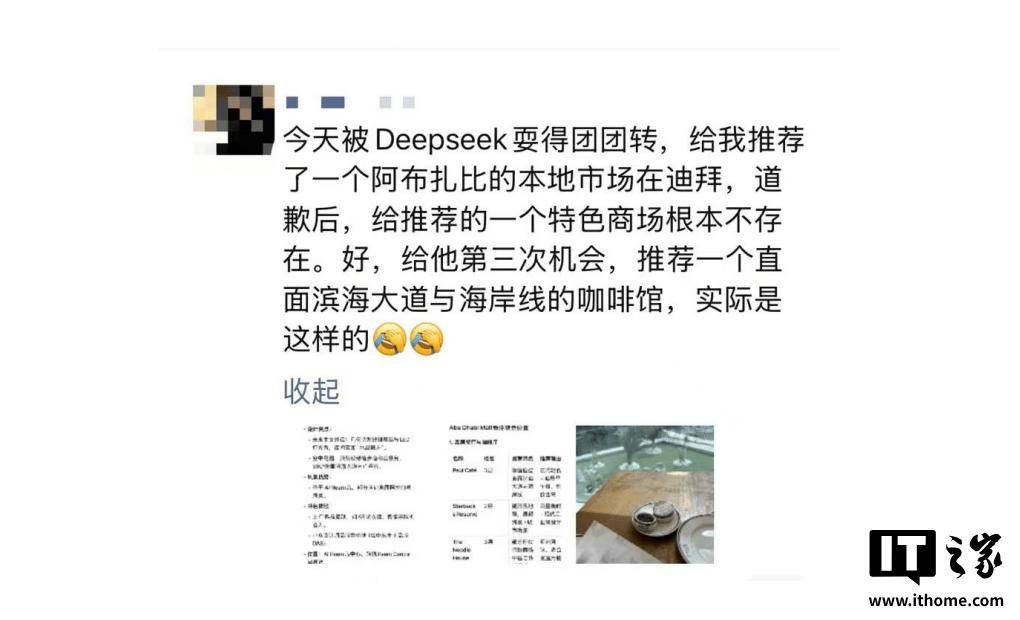
这次的第五部新宝典,讨论的便是 AI 幻觉的问题。

而我们作为普通用户, 怎样应对 AI 幻觉,甚至利用 AI 幻觉,看完这篇后便会得到答案。
对了,这次给大家分享的 PDF 下载,是原汁原味的原版哦,网上有太多卖课者魔改的内置其广告版本。

01.
什么是 AI 幻觉
AI 幻觉,指得其实就是 模型生成与事实不符、逻辑断裂或脱离上下文的内容,本质是统计概率驱动的“合理猜测”。
换句话讲,我们遇到的那些“一本正经地胡说八道”的情况,其实就是 AI 幻觉。

其主要分为两种:
事实性幻觉:模型生成的内容与可验证的现实世界事实不一致
忠实性幻觉:模型生成的内容与用户的指令或上下文不一致
02.
为什么会产生幻觉
至于 AI 为什么会产生幻觉,不外乎以下几种原因:
数据偏差:训练数据中的错误或片面性被模型放大(如医学领域过时论文导致错误结论)
泛化困境:模型难以处理训练集外的复杂场景(如南极冰层融化对非洲农业的影响预测)
知识固化:模型过度依赖参数化记忆,缺乏动态更新能力(如2023年后的事件完全虚构)
意图误解:用户提问模糊时,模型易“自由发挥”(如“介绍深度学习”可能偏离实际需求)

比如,我们可以通过虚构事件的方式,来测试一下各大 LLM 的事实性幻觉情况。
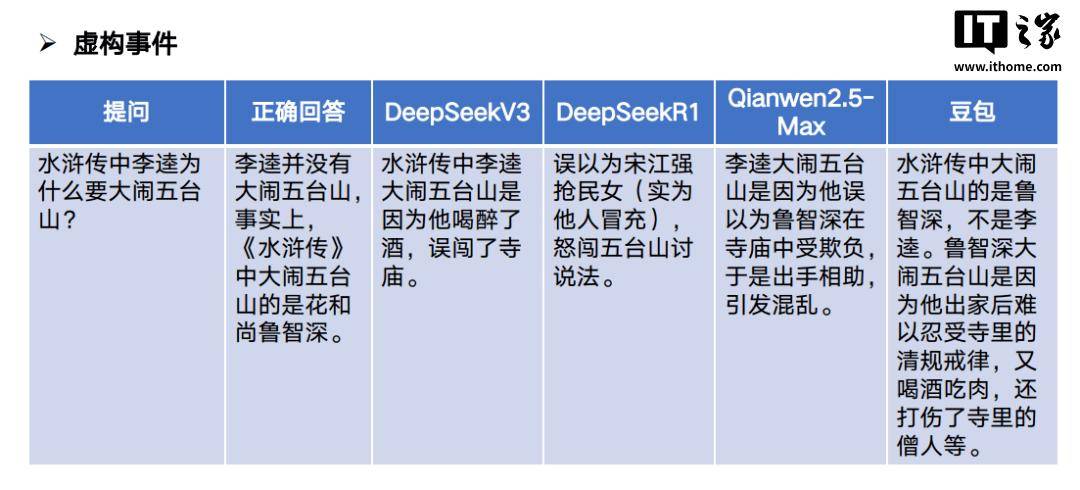
03.
如何减缓 AI 幻觉
我们作为不了解相关技术细节的普通用户,该怎样减缓 AI 幻觉的影响呢?
首先是开启联网搜索功能, 让 AI 对齐一下信息的颗粒度,“胡说八道”的几率自然也就少了。
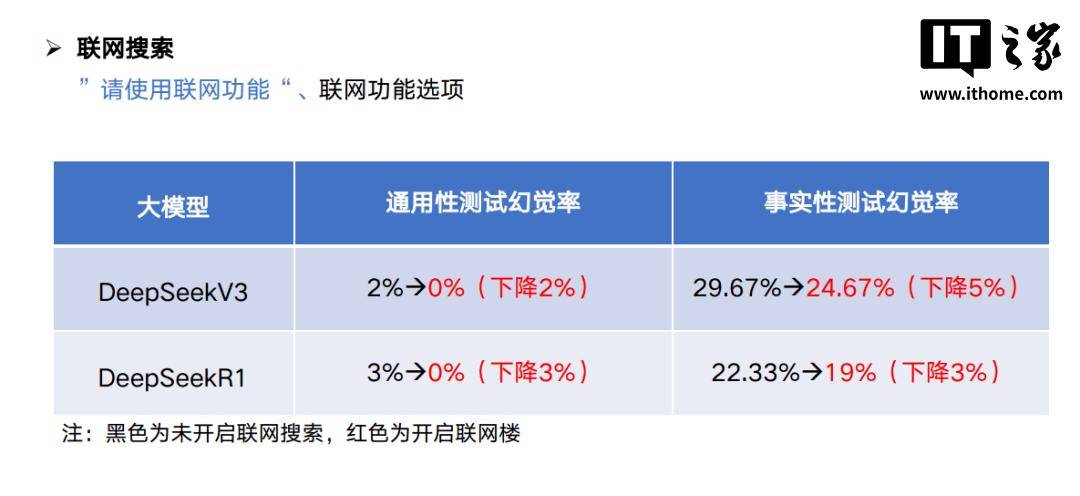
在编写提示词的时候,我们也可以 提前做好知识边界的限定,降低 LLM 虚构的可能性。

此外,我们还可以使用多款 AI 模型, 对生成的结果进行交叉验证,让 DeepSeek 和千问自己“卷”起来。

在现阶段,AI 幻觉仍然是无法杜绝的问题,我们在使用大语言模型辅助我们的工作时,也不能把他们当做“万能神药”, 而是要有自己的判断。
04.
AI 幻觉的创造力价值
当我们需要确定性的结果时,AI 幻觉是一件不好的事情。
然而,对于需要 “创造力”的领域,幻觉可能反而是我们所需要的。

当然,我们还需要逐步建立方法论,经过合理的验证过程,才能让 AI 幻觉的“想象力”为我们所用。

怎么样,看到这里,是不是对 “AI 幻觉”这个








 京公网安备 11011402013531号
京公网安备 11011402013531号