适逢2024年第四季度及全年财报发布,百度2024年总营收达1331亿元,归属百度核心的净利润达234亿元,同比增长21%,不过相比于财报中的数字,行业更想知道百度未来的方向。
在财报电话会上,李彦宏也抛出了自己的回答,“无论开源还是闭源,基础模型只有在能够大规模有效解决现实世界问题时才真正有价值,我们致力于以应用为导向,持续迭代文心大模型。秉持这种理念,自推出以来,我们一边利用文心大模型升级内部产品,一边服务企业客户。”
太多人关注开源与不开源的表象,大模型本质还是要解决问题、创造价值,以及用更高性价比的解决方案在实践中落地,在大模型进入应用爆发期之际,百度选择“免费+开源”的路线,反而让百度AI的核心价值更清晰了。
百度从DeepSeek学到的一件事
DeepSeek带来的热度是现象级的。有行业观点认为,DeepSeek所带来的影响已超越单一技术突破,其通过成本重构、开源生态和效率革命,正在重塑AI行业的底层逻辑。
今年春节期间DeepSeek降本出圈,2月13日文心宣布免费,紧急着当日凌晨OpenAI也释放了下一代模型驱向免费的信号,OpenAI首席执行官Sam Altman公布了GPT-4.5和GPT-5的消息,免费版ChatGPT能在标准智能设置下无限制地使用GPT - 5进行对话,ChatGPT Search向所有人开放,无需注册,在OpenAI官网首页就可以直接使用搜索功能。今年年初,有消息称Open AI内部在讨论开源AI模型权重。
国内外模型厂商的密集动作反映出,免费+开源正在成为最新的行业大趋势。而策略转向则是顺应时代变化的适时选择。随着大模型竞速赛迈入以“应用”为主题的下半场,开源+免费既能让自身应用生态更扩大,又是长期“不下牌桌”的关键武器。
回到百度本身,DeepSeek的一些特质是百度、OpenAI和其他大公司都不具备的,而百度等所具备的资源和属性,也是DeepSeek所没有的,在不少公司还在踌躇之际,百度动作很快,抓住先机。
昨晚的2024及全年Q4财报电话会议上,李彦宏表示,“我们从DeepSeek学到的一件事是,那就是将最为优秀的模型开源供所有人使用,将可以极大地推动其应用,因为大家出于好奇自然会想去尝试开源模型,进而推动其更广泛的应用。”
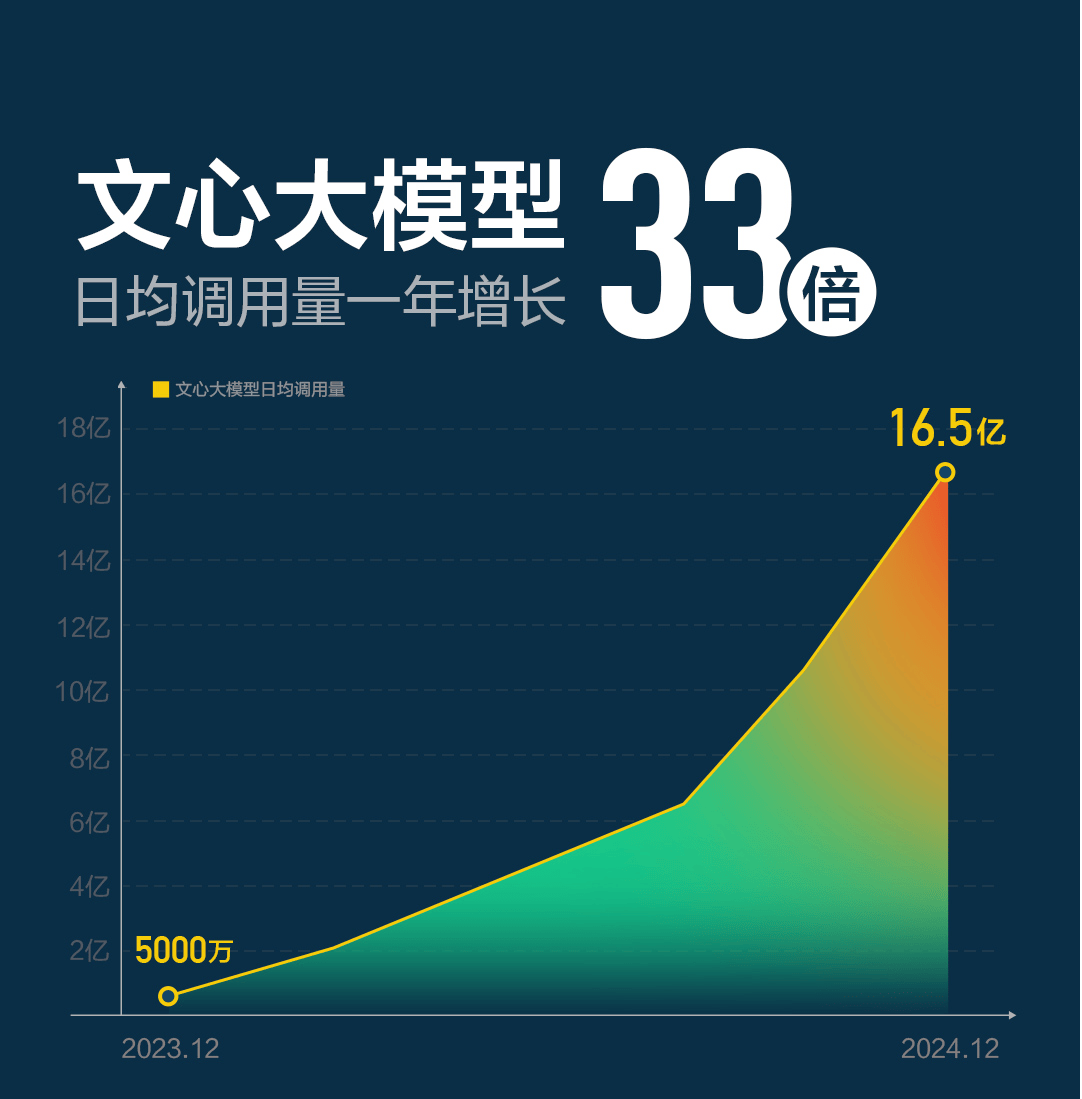
百度的大模型在行业颇具竞争力,文心大模型已经展现出强大的市场吸引力,日API调用量在短短一年内从5000万激增至16.5亿。他提到,文心大模型4.5将是百度有史以来最出色的模型,希望用户和客户试用起来能比以往更容易,更轻松。
“我们决定将文心大模型4.5系列进行开源,也源于对自身技术领先地位的坚定信心,这种信心源自我们数十年在研发方面的持续投入、不断的技术创新,以及我们作为全球为数不多具备全栈人工智能能力公司之一的独特地位。”他补充表示。
只有当大模型不再是极客人群和专业人群的专属,而是走向田间地头,同时大模型进入低价时代,大模型的使用量才会进入激增时期,这也是百度AI战略的核心,即推动大模型的应用普及。
“免费”的百度,更有想象力
第一代互联网企业依靠免费策略崛起,成就了一个时代的辉煌,至今仍在影响互联网行业的商业模式,用免费的产品和服务去吸引用户,然后再用增值服务或其他产品收费,遂成为互联网公司的普遍成长规律。
大模型产业的情况稍有不同,它显著拉高了入局者的门槛,无论是动辄以亿元计数的资本投入,还是上万卡的资源投入,更逞论人才密度等背后潜藏的高竞争门槛,如果产品不好用或者烧钱不可持续,只会加速大模型企业的衰败。
百度为什么敢于“免费”?一方面,大模型本身对C端用户免费,但是AI驱动其他业务可以带来增长;另一方面,百度AI全栈的能力,能够大幅降本增效。
以直接受益的百度智能云业务为例,电话会介绍,智能云业务在2024年四季度增长强劲,营收同比增长26%,经营利润率持续增长;2024年,智能云AI相关收入同比增长近3倍。
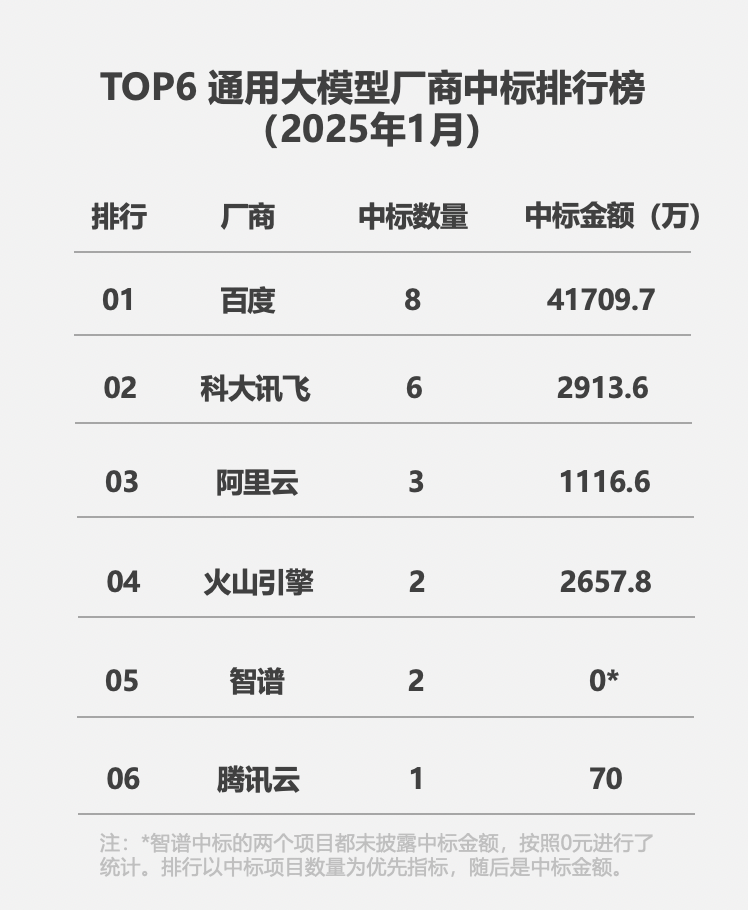
公开信息显示,百度智能云拥有中国最大的大模型产业落地规模,为超60%央企和大量的民营企业提供AI服务。在2024年大模型中标盘点中,百度智能云在中标项目数、行业覆盖数、央国企中标项目数这三个维度里均为第一。
财报电话会披露,2024年Q4季度,百度将统一GPU集群规模扩大了一倍,并实现99%的有效训练时间。得益于更快、更先进的网络架构,百度百舸异构计算平台能使不同地理位置的GPU无缝协作,将性能损失降至最低,并自动解决大规模计算中固有的网络问题,降低对客户影响。
近期,百度智能云成功点亮昆仑芯三代万卡集群,也是国内首个正式点亮的自研万卡集群,未来,将进一步点亮三万卡集群。
李彦宏介绍,百度正持续增强千帆大模型平台,不断改善客户的模型和应用开发体验。千帆大模型平台不仅接入了各种型号的文心大模型,还提供国内外上百个主流大模型,并且为所有接入的模型提供后训练、SFT、数据标签和模型准备等工作,以便为不同的企业提供最合适的模型和工具。
值得一提的是,依托全栈的AI架构和端到端优化能力,千帆大模型平台能够在保障任何模型的最佳性能和稳定性的同时,提供极具竞争力的调用价格。以最新接入的DeepSeek-R1和V3模型为例,千帆平台上的推理价格最低至DeepSeek官方定价的30%。接入首日,即有超过1.5万家客户通过千帆平台进行模型调用。
百度是全球少有的具有全栈AI能力的公司,其自研的四层AI架构和端到端优化能力,让百度以更低的成本实现模型的高可靠性、安全性与高性能。
百度大模型的双线策略:技术“摸高”与应用普惠
昨日马斯克最新发布了Grok-3,并将其称为“地球上最聪明的AI”,只是20万张GPU的训练成本以及坚持不开源的举动,也带来一些争议。基础大模型仍将继续演进,但边际效应在逐渐递减,马斯克批评OpenAI不开源,自己却也没有开源最新的模型。
对比之下,百度的策略则相当直接,一方面继续投入基础大模型的迭代演进,另一方面拿出最大的诚意做AI应用普及。
譬如文心一言已上线的深度搜索功能,具备更强大的思考规划和工具调用能力,可为用户提供专家级内容回复,并处理多场景任务,实现多模态输入与输出。该功能也将于4月1日起对用户免费。
检索增强也是衡量大模型优劣的重要维度,百度基于搜索技术的积累在文本生成领域的RAG上具备明显优势。百度研发了「理解-检索-生成」协同优化的检索增强技术,显著提升了大模型技术及应用的效果。
24年,百度发布了自研的iRAG(image based RAG-检索增强的文生图技术),以加快文生图领域的应用速度。iRAG将百度搜索的亿级图片资源跟强大的基础模型能力相结合,生成各种超真实的图片,整体效果远远超过文生图原生系统,去掉了AI味儿,而且成本很低。
“生成式人工智能和基础模型市场仍处于初期阶段,但发展速度极快,DeepSeek的成功案例肯定会加快基础模型的采用率。随着基础模型变得更容易获得和可负担得起,我们正进入一个真正的变革阶段,我们会看到新的人工智能应用和使用案例在数量上呈爆发式增长,这将为所有人带来巨大的机遇,并拓展人工智能的边界,增加更多可能性。”李彦宏在昨晚财报电话会议上说道。
目前百度借助文心大模型成功改造了面向消费者的产品,如百度搜索和百度文库;此外,百度通过千帆平台提升了企业客户的模型和应用开发体验。文心一言在指令遵循、先进的检索增强生成技术(该技术将幻觉问题降至最低)等方面的行业领先能力,使其在各种场景中得到广泛应用,千帆平台的综合工具链让客户能够针对自身应用场景定制任何模型。
“展望未来,我们将瞄准性能提升和成本削减的潜力,加快文心大模型的迭代,继续在对现实世界影响潜力最大的领域对其进行开发,我们对人工智能发展的新篇章感到兴奋,期待看到人工智能技术带来更多具有开创性且对社会有持久价值的应用。”李彦宏总结表示。(本文首发于)








 京公网安备 11011402013531号
京公网安备 11011402013531号