马斯克又放大招!就在刚刚,全球科技圈被马斯克扔下了一颗AI核弹!Grok3大模型登场,测试结果超越主流大模型!
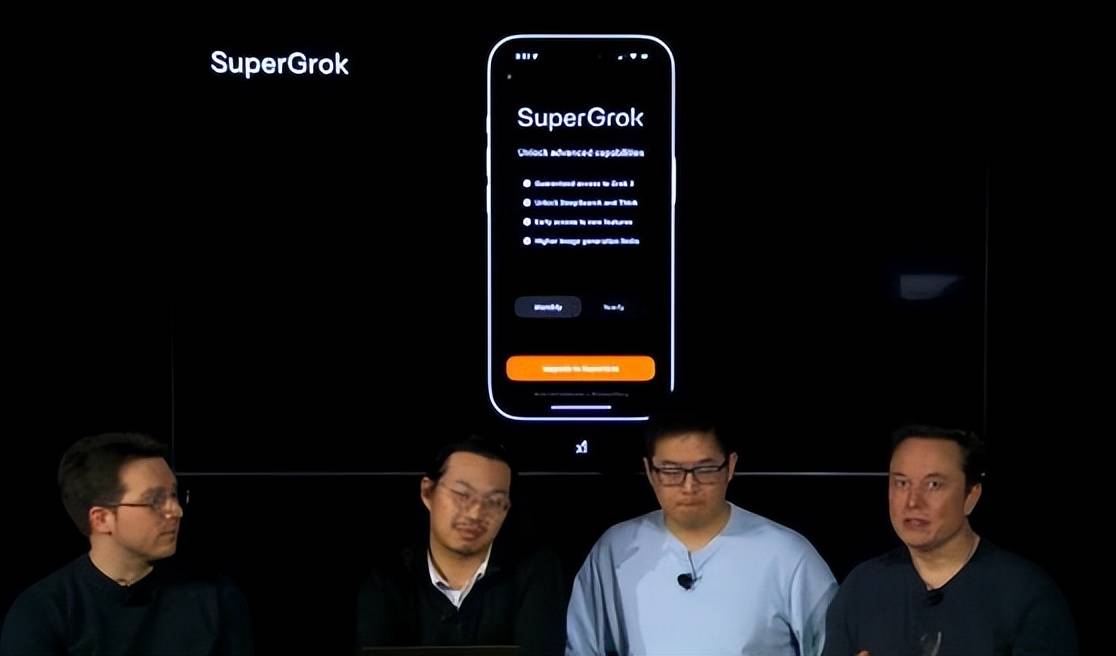
日前,马斯克旗下人工智能公司xAI开发的Grok-3模型正式发布。马斯克表示,Grok-3为地球上最聪明的AI,Grok 3的计算能力是Grok 2的10倍以上。
的确,在直播现场演示过程中,Grok 3在数学、科学和编程基准测试中,Grok 3击败了谷歌Gemini、DeepSeek的V3模型、Anthropic的Claude和OpenAI的GPT-4o。
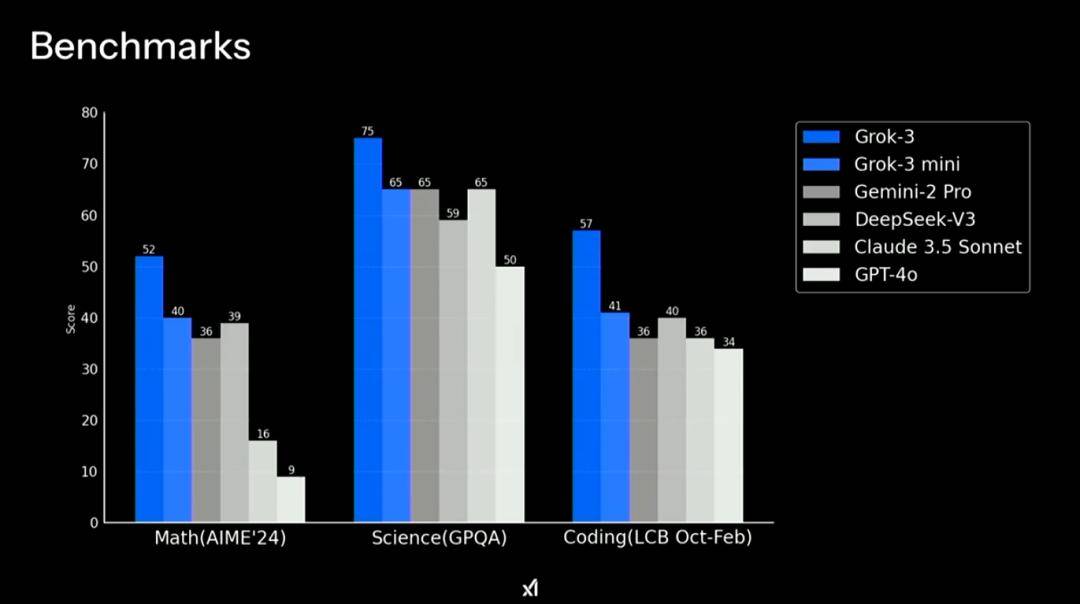
另外,演示还使用Grok3帮助火星飞船计算航天发射窗口,以及把俄罗斯方块和消消乐两款游戏“融合成一款”等等,性能可以称得上强大。
同时,马斯克还强调,Grok-3可以减少AI幻觉,方法是通过来回检查数据并尝试实现逻辑一致性。
AI幻觉,是指大语言模型编造它认为是真实存在的甚至看起来合理或可信的信息,与现实世界事实或用户输入不一致的现象,说白了就是“胡说八道”,这也是AI大模型使用过程中普遍存在的现象。能解决或者减少AI幻觉,会极大的提高用户使用体验。
另外需要注意的是,Grok-3的训练成本极高,使用了高达20万块的英伟达GPU,远超此前的版本。不过马斯克在2024年7月透露, Grok 3用了10万块英伟达H100芯片进行训练,有可能是进行了扩容。但不管怎样,这显然跟DeepSeek形成了鲜明的对比。

首先,OpenAI前联合创始人、特斯拉前AI总监安德烈·卡帕西在使用了2个小时Grok3后表示,Grok 3加上深度思考模式与OpenAI最强推理模型o1 pro大致相等,并且略优于DeepSeek的推理模型R1。也就是说,Grok3并没有太大的领先优势。
其次,目前来看,美国AI大模型有点大力出奇迹的意思,毕竟他们在算力方面有着充足的保障。
根据于此,Grok3可能比DeepSeek-V3的6710亿参数要大一个数量级。

但这也从侧面再次证明,国产大模型在技术方面没有任何问题,甚至做到了领先。因为先进的AI芯片一直被美国限制着,算力储备和应用方面美国处于领先,这或许也倒逼了国产大模型在参数压缩、算法等方面不断创新。所以说,在AI大模型领域,算力并非唯一的决定性因素。
通过大量数据和超大的算力进行长时间训练,然后获得一定的定性,并不一定是AI行业发展的最优方式,毕竟除了美国,其他国家难有这样的能力。
以xAI之前拥有的10万个英伟达GPU卡的计算机集群为例,这种规模在美国是科技巨头们的标配,由于数量巨大,不仅需要巨额资金,对电力也有极高的要求。根据相关机构的估计,一个10万卡集群一年消耗电量约为15.9亿度电,相当于15 万个家庭一年的用电量,在美国,这种集群仅电力支出就高达约1.3亿美元。
虽然AI的发展趋势,很重要,但目前还远远没有到能改变人类世界的地步,如此巨大的电力消耗,显然是有些暴殄天物了,甚至有些只是有钱人游戏的味道。
要知道,人们的日常生活、工作,工业生产,科学研究,全社会的运行都需要电,即便是到了科技高度发达的今天,现在仍然有很多国家面临缺电的问题,影响到无数人。所以,无休止的发展算力规模,并不健康。需要在大模型、数据、算力之间找到一个合适的关系,才能发挥出AI的真正意义。
总之,随着Grok3的问世,全球AI大模型的竞赛还将继续下去,但我们可以预见,这条赛道的未来将会是百花齐放的格局,因为开源、低成本、高性能三位一体的DeepSeek出现后,玩法已经变了,谁都可以通过DeepSeek去构建自己的大模型。
再有,马斯克还表示,Grok3 将在后面开源。并且,OpenAI CEO山姆·奥特曼在网上发起了一个投票,询问网友,是做一个相当小但仍需要在GPU上运行的o3-mini级开源模型更有用,还是做一个能做得最好的手机大小的开源模型。就连openai也要开源了。
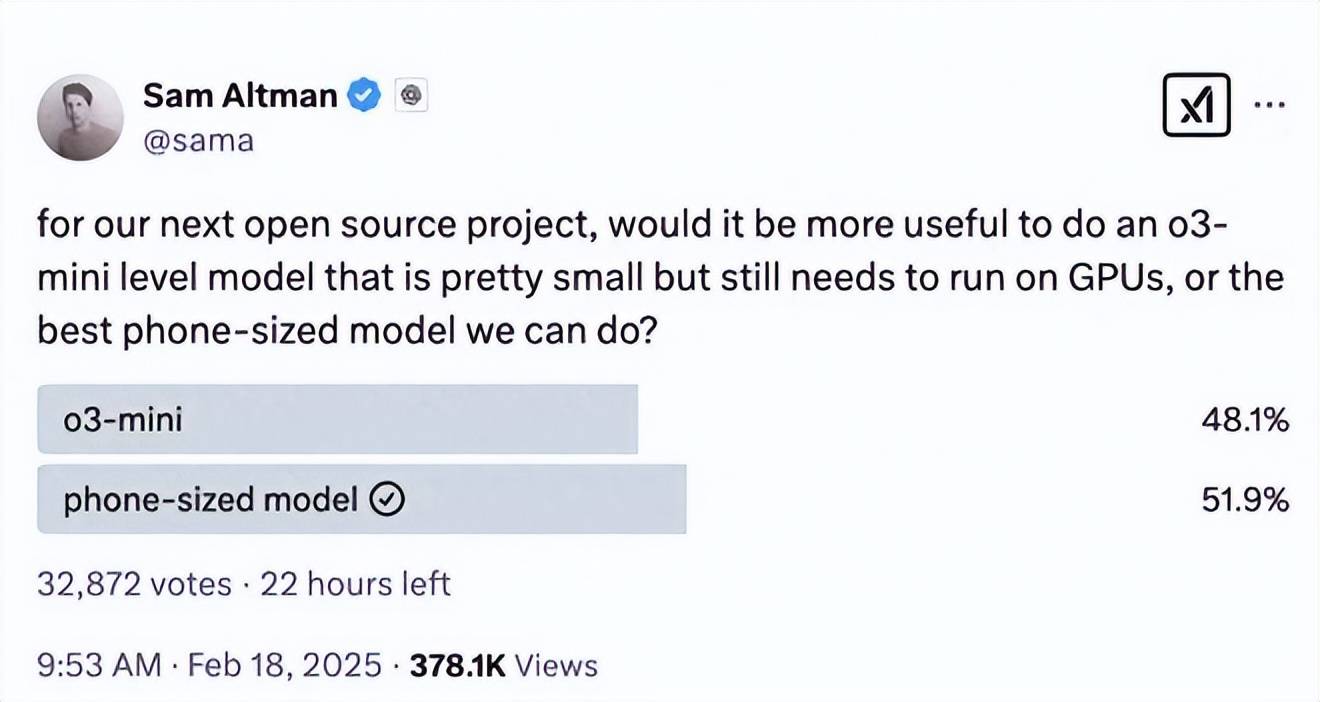
可见,开源才才是方向。
不管怎样,盲目堆积算力的时代已经过去,属于全民大模型的时代正在到来,那么,你准备在AI领域大干一番吗?







 京公网安备 11011402013531号
京公网安备 11011402013531号