
2月18日,百度(09888.HK;BIDU.O)发布了四季度及全年财报。
2024年,百度全年总营收1331亿元,归属百度核心的净利润达234亿元,同比增长21%。其中,第四季度营收341亿元人民币,核心收入277亿元。
具体从业务方面来看,百度智能云业务脱颖而出,在第四季度智能云业务同比增速达26%,其中AI相关收入同比增长近3倍,令市场确认了百度智能云业务的价值。
“2024年是我们从以互联网为中心转向以人工智能为先的关键一年。随着我们全栈AI技术得到广泛的市场认可,智能云的增长态势愈发强劲。在移动生态中,我们一直坚定推动搜索的AI原生化重构,提升用户体验。”百度创始人、董事长兼首席执行官李彦宏表示,“随着我们的AI战略不断被验证,我们相信AI相关投入将在2025年带来更大的成果。”
AI驱动云业务高速增长
百度2024年最大的惊喜在于AI与云业务的成绩单。
先看几组数据:
一是2024年百度智能云AI相关收入同比增长近3倍,在第四季度智能云业务同比增速达26%。二是2024年12月文心系列模型处理的日均API调用量达到16.5亿次,与23年同期的5000万次相比增长33倍;三是2024年12月百度文库AI功能的月活跃用户达到9400万,同比增长216%,环比增长83%;
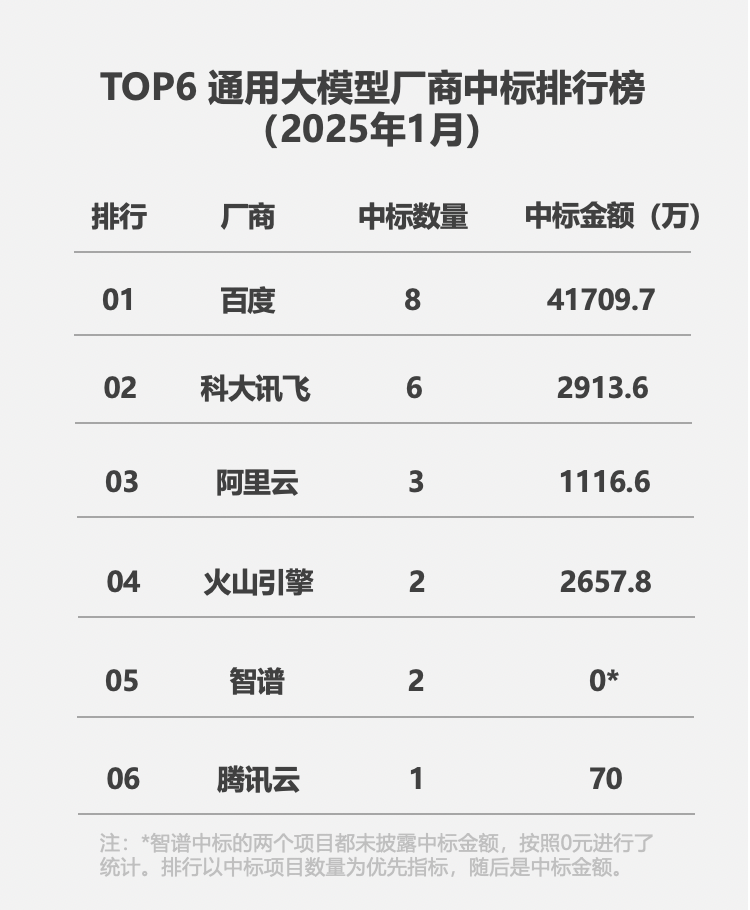
据统计,2024全年国内大模型相关中标项目共910个,是2023年的4.5倍,中标金额25.2亿元,是2023年的4倍。其中,百度领跑中标单位排行,在中标项目数、行业覆盖数、央国企中标项目数这三个维度里均为第一,对应项目采购单位包括中华全国总工会、国家电网等央国企头部客户。在今年1月发布的通用大模型厂商中标排行榜中,百度也获得双项第一。

当然,这与百度AI技术的落地密不可分。
2019年,在大多数人对生成式AI还一无所知的时候,百度发布了文心大模型。2023年随着生成式AI浪潮席卷全球,百度快速推出文心一言且始终保持快人一步的节奏,基于高效的模型生产机制建设了文心大模型矩阵。2024年第三季度,百度推出两款新模型,从旗舰款4.0、速度更快的Tubro,到增强的轻量级模型Speed Pro、Lite Pro等。近日,百度又再次宣布文心一言将免费,并将在未来几个月中陆续推出文心大模型4.5系列,并于6月30日起正式开源。
持续投入研发领先的基础大模型的同时,百度也在积极解决模型应用落地时遇到的技术卡点,如百度世界2024大会上刚刚发布的iRAG技术,极大解决了文生图的幻觉问题,提升图片生产力。
智能云应用落地方面,百度推出的千帆ModelBuilder模型工具链升级模型训练方法;目前,千帆大模型平台接入了各种型号的文心大模型,还提供国内外上百个主流大模型,并且为所有接入的模型提供后训练、SFT、数据标签和模型准备等工作,让企业在行业场景高效精调出更稳定、效果更好的专用大模型;
值得一提的是,依托全栈的AI架构和端到端优化能力,千帆大模型平台能够在保障任何模型的最佳性能和稳定性的同时,提供极具竞争力的调用价格。目前,DeepSeek-R1和 DeepSeek-V3模型现已接入千帆大模型平台,提供行业领先的超低推理价格,最低至DeepSeek官方定价的30%。数据显示,模型上线首日,就有超过1.5万家客户通过千帆平台进行模型调用。
据介绍,百度是全球少有的具有全栈AI能力的公司,其自研的四层AI架构和端到端优化能力,让百度以更低的成本实现模型的高可靠性、安全性与高性能。
“DeepSeek现象”驱动智能云价值空间拓展
2025年1月,DeepSeek横空出世且迅速火爆全球,同时也给AI行业带来两点切实变化:
一是DeepSeek将大模型训练成本拉低了两个数量级,大模型进入低价时代,正如李彦宏说的“12个月内推理成本基本上可以降低90%以上”。
二是随着国内科技大厂如百度、腾讯、阿里都已选择加入开源阵营,这意味着大模型的技术高墙某种程度上被打破,不再是极客人群和专业人群的专属,开始走向田间地头。
上述两点变化降低了大模型的计算资源需求,将全行业的聚焦从训练为中心拉到了以推理为中心。聚焦点转变的一个重要表现是应用的大发展,而不再仅仅是对话了。
可预见的是,应用开发需求的增长必然大幅提升云资源消耗量,云市场也将从粗放经营演变为精细创新,云服务商的价值将不再局限于提供计算、存储、网络和安全等资源层服务,而是需要能提供更高性价比、更低部署门槛、更方便开发AI应用的云智一体服务。
显然,这正是百度智能云的优势。
全球人工智能公司中,百度是为数不多在芯片、框架、模型、应用四个层面全栈实现自研的,这也让百度能够实现端到端优化,不仅大幅提升了模型训练和推理的效率,还能进一步降低综合成本。
以云基础设施为例,近日百度成功点亮昆仑芯三代万卡集群,这也是国内首个正式点亮的自研万卡集群,百度表示将进一步点亮3万卡集群。
成熟的万卡集群管理和部署能力也意味着,百度将进一步降低模型训练成本。资料显示,百舸AI异构计算平台4.0已具备成熟的10万卡集群部署和管理能力,且在万卡集群上实现了99.5%以上的有效训练时长,能够将两种芯片混合训练大模型的效率折损控制在5%以内,达到业界最领先的水平。
而在框架层,百度拥有中国开发者使用最广的飞桨开源框架。在模型层,百度具有丰富的文心大模型矩阵,还将在今年内还将发布多款模型,如文心4.5、5.0等等,多模态能力将显著增强;与此同时,优秀的MaaS平台还将提供丰富且极具性价比的模型资源和开发工具:目前,千帆已经帮助客户精调了3.3万个模型、开发了77万个企业应用。
在应用层百度有最激进进行AI重构的百度搜索、近亿AI用户的百度文库等等。
抢占AI应用爆发先机
2月18日的百度财报电话会上,李彦宏透露,文心大模型4.5将开源,且4.5将是百度有史以来最强大的大模型。
而在此之前,文心一言一直采取了和ChatGPT类似的收费模型,在前不久,百度宣布文心一言将全部免费。
显然,随着DeepSeek等开源模型的崛起,也让更多人意识到开源模型在推动AI技术普及与应用方面的巨大潜力。
“从DeepSeek的成功中,我们认识到,将最为优秀的模型开源,能够极大地促进应用。当模型开源后,人们出于好奇自然会去尝试,这将扩大模型在更多场景中的影响力。”李彦宏说,“无论模型开源还是闭源,只有当基础模型能够大规模有效解决实际问题时,才真正具有价值。”
文心大模型的开源,将让更多开发者和企业用户可以零门槛、低成本地使用模型,既可以扩大文心影响力,也是其“开源引流+云服务变现”双轮驱动新支点的打造。
核心的机制是,通过开源吸引更多开发者加入文心大模型的研发和应用中来,避免被竞争对手超越的同时,通过免费开放,厂商可以迅速吸引大量用户,形成数据积累,进而通过数据反馈优化模型,建立用户黏性,巩固市场地位,最终形成“技术开放—生态壮大—商业变现”的良性循环。
而这种良性循环一旦形成,无疑将为百度在未来的应用大发展中扩大赢面,为未来的商业模式创新奠定了坚实基础,乃至成为行业可复制的范式。






 京公网安备 11011402013531号
京公网安备 11011402013531号