2 月 19 日消息,昨天马斯克及其 xAI 团队在直播中正式发布了 Grok 3,此前马斯克通过持续的预热宣传,将外界对 Grok3 的期待值推向了前所未有的高度。马斯克称 Grok 3 为,然而其实际表现似乎对不起这个名号。

注意到,在发布会上,马斯克宣称 Grok 3 在数学、科学与编程的基准测试中超越了所有主流模型,并计划将其应用于 SpaceX 的火星任务计算,甚至预测未来三年内将实现诺贝尔奖级别的突破。
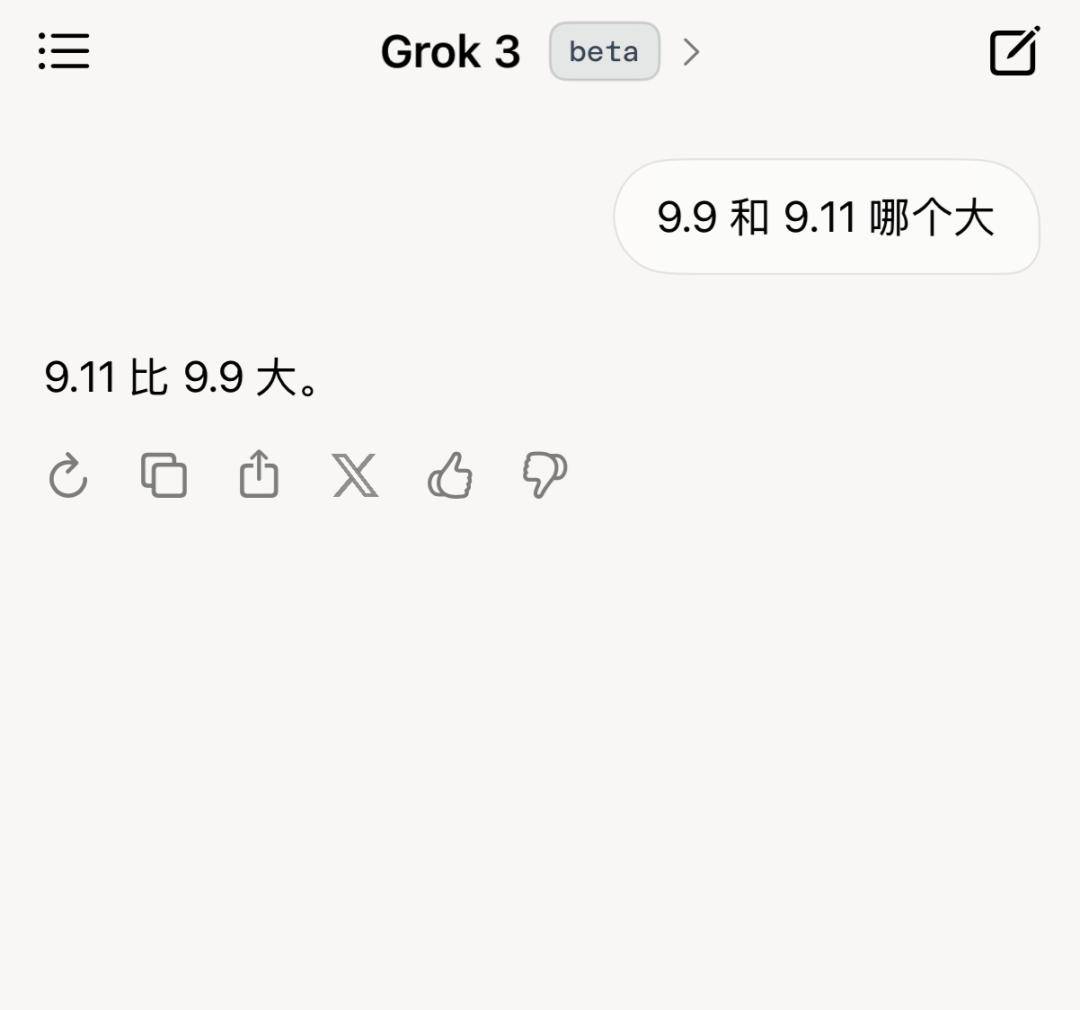
但 Grok 3 的实际测试表现却让人大跌眼镜。发布后,一些媒体测试了最新的 Beta 版 Grok 3,并提出了那个经典的用来刁难大模型的问题:“9.11 与 9.9 哪个大?”遗憾的是,号称目前最聪明的 Grok 3,仍然无法正确回答这个问题,被网友戏称为“天才不愿意回答简单问题”。
此外,在 xAI 发布会直播中,在分析游戏《流放之路 2》的职业与升华效果时,Grok 3 也给出了大量错误答案,并且马斯克也没有看出这些明显的错误。
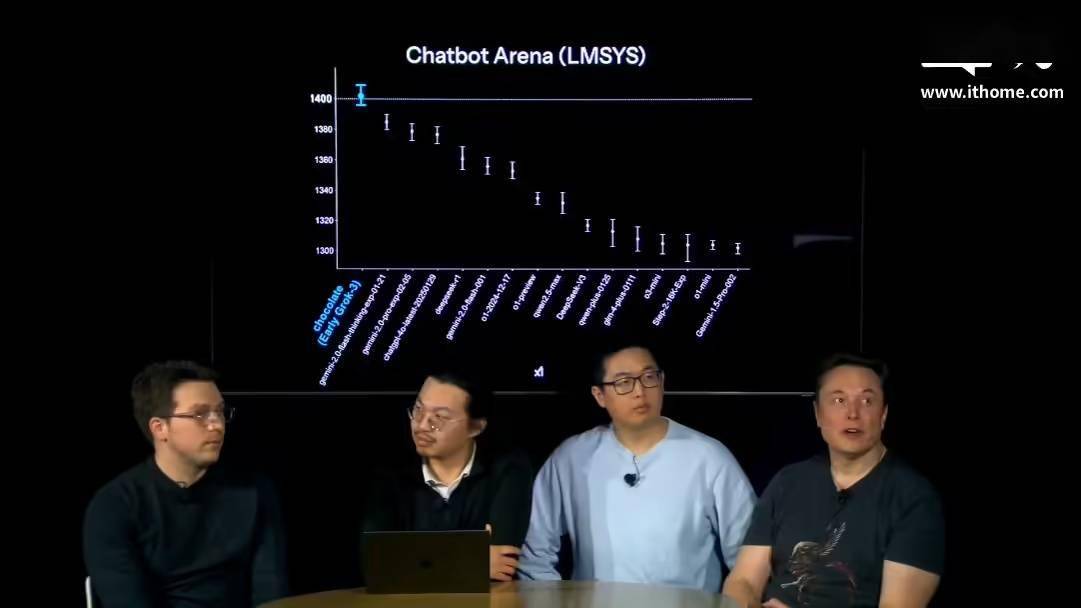
尽管在官方 PPT 中,Grok3 在大模型竞技场 Chatbot Arena 中看似“遥遥领先”,但实际上其与 DeepSeek R1 和 GPT4.0 的差距仅为 1% 到 2%。
马斯克在发布会上透露,Grok 3 使用了超过 20 万张 H100 芯片,总训练小时数达到两亿小时。作为对比,DeepSeek V3 仅使用 2000 张 H800 芯片训练两个月,其性能却与 Grok 3 相差无几。这表明,随着模型规模的不断扩大,性能提升的边际效应已经显现。
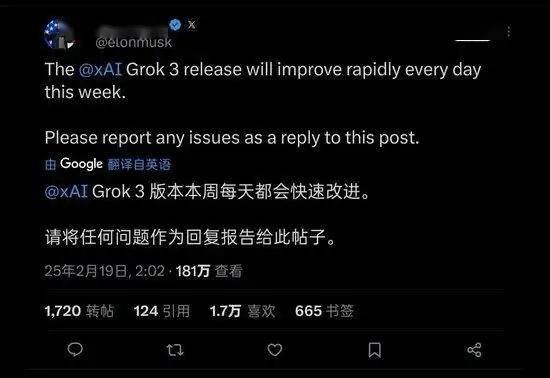
值得一提的是,马斯克在社交媒体上表示,当前的 Grok 3 仅是测试版,完整版将在未来几个月推出,并邀请用户反馈使用问题。







 京公网安备 11011402013531号
京公网安备 11011402013531号