众所周知,在春节前,杭州的Deepseek横空出世,让整个华尔街都崩了,投资人是寝食难安。
因为DeepSeek(深度求索)发布的一款开源AI模型,多项指标都比OpenAI的产品更强,但研发成本不到600万美元,相比之下,OpenAI的研发成本,是几十亿美元。

所以Deepseek爆火之后,整个华尔街都担忧,之前各大公司都要用数十亿美元买显卡,这种构建大型AI模型的做法,是不是错误的,靠算力来堆,是不是一个谎言?
于是,紧接着美股科技巨头股价集体下跌,英伟达一夜跌了17%,一夜之间就跌没了4万多亿元,另外博通、AMD、微软、台积电等都是爆跌,大家认为之前的AI估值逻辑,可能出了问题。
这些AI芯片,可能并没有想象中的值钱了,甚至整个AI领域的衍生品,比如电力供应商等,都受到了大影响。

很多人以为,接下来整个AI领域的创新,会围绕着Deepseek的模式进行,那就是低成本,高效率。
但是,马斯克明显就不学Deepseek,他反而再次向大家证明,AI还是要堆芯片。
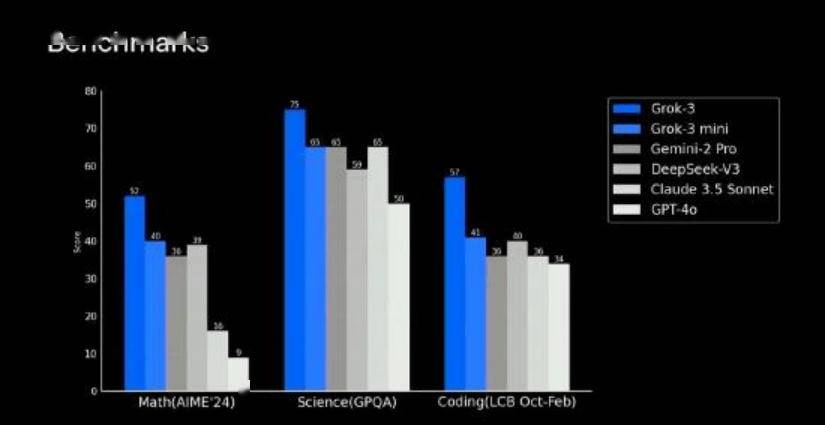
马斯克旗下的xAI公司,发布了新的大模型Grok 3,这个大模型Grok 3不管是LMSYS盲测,还是AIME竞赛,都是领先于友商,马斯克称其是全球最聪明的AI。

这个Grok3,最大的特点就是堆了20万张H100显卡的算力,主打一个“大力出奇迹”。
而Grok3的成功,其实也向大家证明规模定律(Scaling Law)仍然有效。只要显卡堆的多,那么确实会给大模型带来更强的能力,如果有钱,有显卡,就没必要“没苦硬吃”,直接土豪一点,堆算力就行了。
所以,虽然有了Deepseek,但我们还是要清楚的认识到,对芯片、数据中心和云基础设施持续投入才是硬道理,没算力时可以去“四两拨千斤”,但算力依然还是基础,马虎不得。







 京公网安备 11011402013531号
京公网安备 11011402013531号