
谁也没有想到,DeepSeek-R1的影响居然这么大。
腾讯、百度、360、华为、OPPO等科技巨头纷纷点赞DeepSeek,并为旗下的部分AI工具接入了R1模型。曾公开反对开源模型且一直收费的百度,则宣布文心大模型将于4月1日起免费服务,6月30日起开源模型。
就连全球AI大模型领导者OpenAI也在反思一直践行的闭源策略,走向开源,其CEO山姆·奥特曼宣布,将开发一款非常小,但仍需在GPU上运行的开源小模型。
然而一家欢喜几家愁。在我们热议DeepSeek时,曾经红极一时的AI大模型六小强(亦称“AI六小龙”或“AI六小虎”)零一万物、百川智能、阶跃星辰、智谱华章、月之暗面、MiniMax却似乎渐渐被大众遗忘。
AI六小强的进步,没人在意了?
在DeepSeek凭借R1模型搅动AI行业风云的同时,六小强也动作频频,如零一万物与阿里云联合成立“产业大模型联合实验室”,基地落户苏州高新区;百川智能于1月25日发布同时具备语言、视觉、搜索三种推理能力的全场景模型Baichuan-M1-preview,并在2月13日正式上线了基于Baichuan-M1底座打造的AI儿科医生。
1月20日DeepSeek-R1模型发布当天,六小强中有三家也发布了新品,其中MiniMax推出了T2A-01系列语音模型和海螺语音产品,支持17种语言和上百种预设音色,可以提供更自然的AI配音。
阶跃星辰则于当天发布了轻量级、高性价比的Step-2-mini和主打文字创作的Step-2模型,后续两天又接连发布了Step-1o Audio升级版、多模态理解大模型 Step-1o Vision、视频生成模型Step-Video V2。
在AI大模型六小强中,月之暗面未必实力最强,但热度一定最高。月之暗面开发的Kimi一度登上素材买量榜第一,曾是小雷使用频率最高的AI大模型。1月20日,月之暗面发布了Kimi k1.5多模态思考模型,上下文窗口扩展至128k,加入了视觉模态识别能力。

(图源:Kimi截图)
拥有清华大学背景的智谱华章,前段时间与三星合作,携手三星为国内用户提供AI服务,也小小地火了一把。只可惜,三星手机国内销量已沦为others,未能带给智谱华章更多流量。前段时间,智谱华章也推出了清影2.0大模型,视频生成速度和效果均显著提升。
六小强努力吗?很努力,各类型AI大模型一个接着一个发布。六小强有实力吗?有,阶跃星辰去年发布了8款多模态相关大模型,并斩获多个权威榜单第一,刚发布不久的Step-1o模型,又在大模型测试平台OpenCompass的测试中再次拿下多模态模型评测实时榜第一。
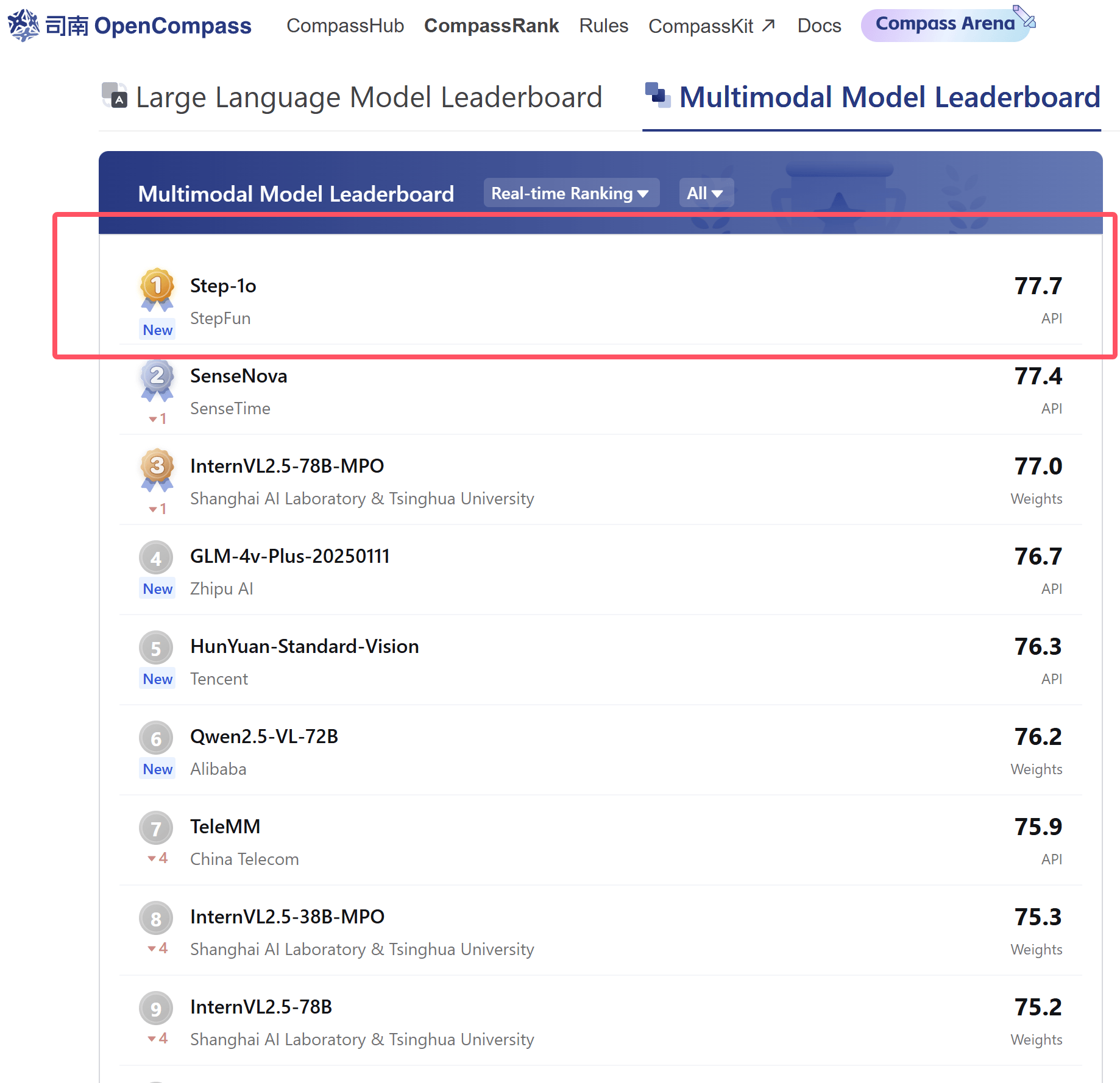
(图源:OpenCompass截图)
OpenAI在取得国际信息学奥林匹克竞赛(IOI 2024)金牌的报告中,还特地指出的DeepSeek-R1和Kimi k1.5分别通过CoT(思维链)提升了模型的数学推理和编程能力。
问题是,这一切都不重要,互联网时代酒香也怕巷子深,他们的人气太低了。百度指数显示(注明:百度指数未收录“零一万物”词条),最近30天,AI大模型六小强中,只有月之暗面的人气较高,其他几家人气均较为一般,百川智能和阶跃星辰的日均搜索指数更是只有三位数。
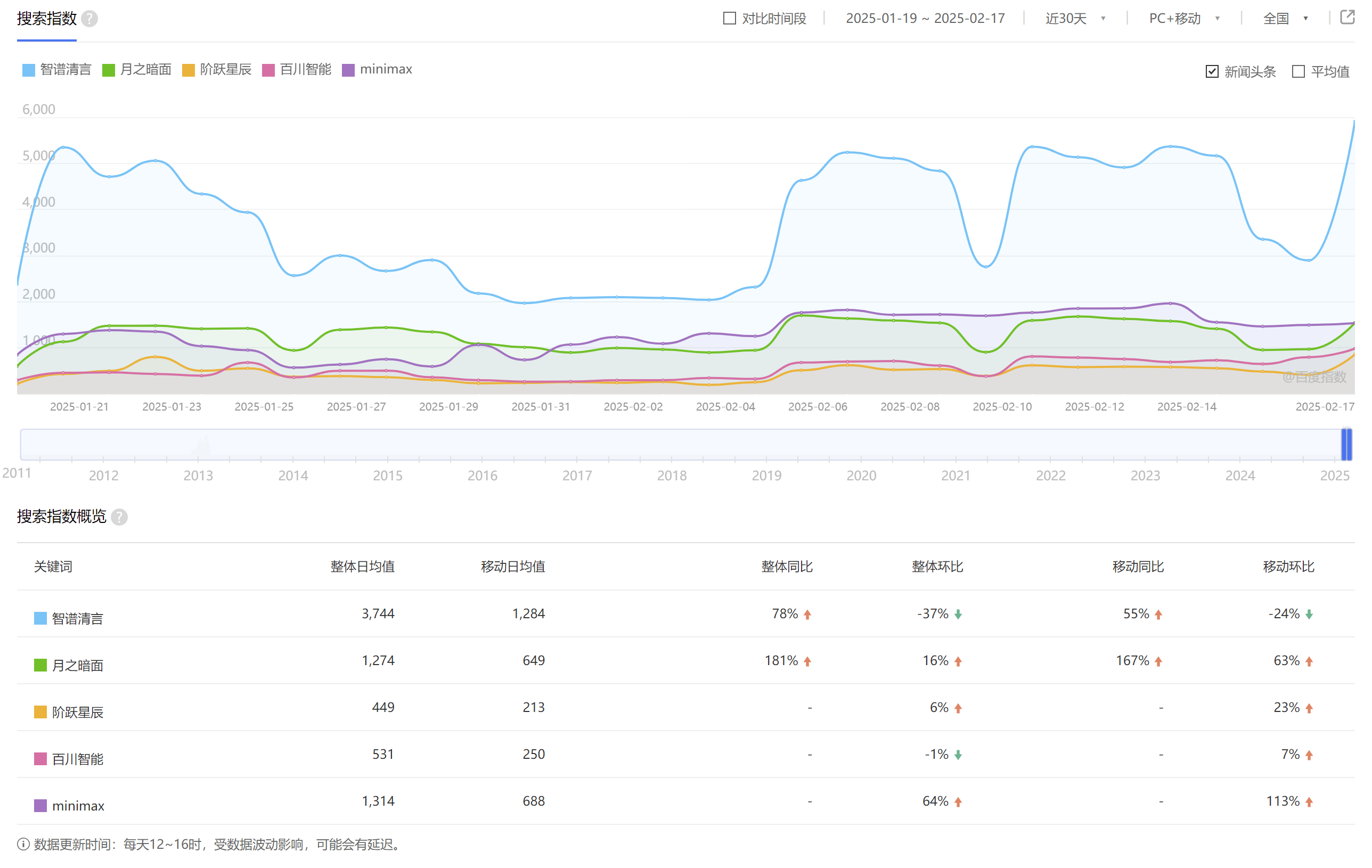
(图源:百度指数截图)
若是输给百度、阿里巴巴、腾讯等互联网巨头,AI大模型六小强还能自我安慰,财力和资源落后那么多,输了倒也正常。可偏偏让AI六小强尴尬的是,DeepSeek训练出V3模型只花费了557.6万美元,又付出了几十万美元成本,将其调整至R1模型,花小钱办成了大事。
C端失守、B端难攻,六小强何去何从?
DeepSeek搅动风波后,国内外各大互联网巨头迅速作出了回应。小米 CEO雷军直言DeepSeek非常了不起,很钦佩他们。
阿里巴巴联合创始人、董事局主席蔡崇信表示,DeepSeek证明了开源的价值,未来会将更多资源投入AI应用中。腾讯、百度、360将AI应用接入R1模型,更是用实际行动表达了对DeepSeek的认可。
再回过头来看AI六小强,目前应该没有任何一家公司站出来点评DeepSeek,只有阶跃星辰默默为跃问接入了DeepSeek-R1。零一万物和MiniMax虽然也接入了DeepSeek-R1,但只有海外版产品才能用,国内用户无缘。
互联网巨头资源丰富,开发的顶级大模型与DeepSeek-R1处于同一梯队,哪怕部分领域有所落后,大量资源砸下去,追上来也不是难事。正因如此,互联网巨头更加坦然,AI工具主动接入R1模型,为用户提供更好的体验。
(图源:腾讯元宝截图)
AI六小强拼资源比不过互联网巨头,又没能像DeepSeek低成本打造出影响整个行业的R1模型,难免处境会有些尴尬。零一万物和MiniMax为海外产品接入DeepSeek-R1,国内产品却暂未接入,原因或许就在于担心丢了面子。
对于AI六小强而言,唯一的好消息是AI大模型面向C端用户基本免费提供服务,不会导致因市场丢失造成C端收入下滑,B端市场才是AI六小强的生命线。
但DeepSeek-R1的MIT开源协议允许用户自由使用、复制、修改、分发,而且无需支付费用即可将其用于商用目的,任何企业都可以轻松部署R1模型,显然影响到了AI六小强B端市场的根基。企业将DeepSeek-R1稍作修改,用于B端场景,成本可能比与AI公司合作更低。
DeepSeek-R1性能或许并非国内第一,但低成本和开源的特性改变了AI行业。据科技媒体The Information报道,苹果都曾考虑过找DeepSeek合作,为中国用户提供AI服务,最终因DeepSeek没有为大型客户服务的能力和经验而放弃。
(如愿:DeepSeek截图)
AI大模型商业模式差,企业的变现能力弱,如今AI六小强又遭遇DeepSeek的冲击,调整方向并增强融资能力已成关键。
智谱华章和阶跃星辰在2024年底分别收到了北京市国资和上海市国资的认可,完成了一轮融资,短期内没有资金焦虑。月之暗面和百川智能2024年融资规模均超过50亿元,暂时资金充裕。较为危险的是零一万物和MiniMax,自身融资能力相对较弱,亟需投资者的支持。
不仅如此,AI行业的竞争导致人才战愈演愈烈,字节跳动前CEO张一鸣被曝亲自监督从竞争对手挖人工作。2024年下半年以来,AI六小强人才流失严重,零一万物副总裁黄文灏、百川智能商业化负责人洪涛、MiniMax产品负责人张川等纷纷离职,月之暗面更是因多位负责人离职收缩海外布局。
强如OpenAI与百度也面临DeepSeek的挑战,AI六小强面临的竞争形势正愈发紧迫。
六小强放弃争先,找到立足之地才是关键
英诺天使基金合伙人、北京市前沿国际人工智能研究院理事长王晟表示,AI的上升曲线已经放缓,预训练数据几乎被耗尽,DeepSeek-R1标志着整个行业正在从对标OpenAI的宏大叙事转向场景优先的实用主义。
AI行业结束拼资源的时代,对于AI六小强这类底蕴不足的企业并非坏事。所有AI企业提升顶级大模型能力会越来越难,通过知识蒸馏、架构优化、改进训练策略、分布式训练等技术或方案,以低成本训练更实用的AI大模型将成为主流。
事实上,零一万物创始人李开复在DeepSeek-R1发布之前,就认识到了行业的变化,并表示零一万物不再追求训练超级大模型,参数适中同时性能优异、推理速度更快、推理成本更低的轻量化模型更适合商用场景。

(图源:豆包AI生成)
2025年2月18日,月之暗面在推出终极模型Kimi Latest的同时,还被曝将削减广告投放预算。的确,Kimi一年多时间的广告投入,只带来了不足千万的日活用户,而DeepSeek凭借R1模型,短短一个月左右时间,就获得了3500万日活用户,导致官方频频崩溃,腾讯、360等互联网巨头提供的接口反而体验更好。疯狂打广告吸引C端用户却难以增加营收,倒不如减少广告投放,降低支出成本。
好在,AI行业尚未进入赢者通吃的局面,AI六小强仍有机会。承认自己的不足,效仿DeepSeek以低成本训练大模型,甚至接入R1模型,主动为C端和B端用户提供更完善的服务体验,并同步提升自己,或许才是更适合AI六小强的生存之道。AI时代,国内最终能留下多少巨头企业犹未可知,但一定会有小型企业的生存空间。
财力和资源有限的企业,放弃追求领导行业,如零一万物一般着重开发低成本轻量化模型,主攻商用场景,或许是更好的选择。
这一波开源浪潮来袭,也是小型互联网公司的机会,无需付出大量成本开发AI大模型,仅需在开源模型上调整,也能为B端用户提供AI服务。实力较弱的AI企业可以考虑转型成以通义千问、DeepSeek等企业开发的免费可商用开源大模型为基础,针对B端用户的需求进行修改和定制AI大模型的模式,降低整体成本,快速实现盈利。
聚焦DeepSeek:







 京公网安备 11011402013531号
京公网安备 11011402013531号