
今年才刚刚过去两个月,AI 模型竞技场的火热程度,就已经白热化了。
就在今天中午,马斯克预告的那个号称 “ 地球上最聪明的人工智能 ” Grok 3,终于发布了。
发布会还是秉承着马斯克一贯的风格,说好十二点准时开始,结果还是晾了大家快二十分钟。

将近一个小时的直播中,马斯克携 xAI 天团从各个方面介绍了 Grok 3 究竟有多厉害。从官方给出的纸面数据来看,Grok 3 吊打了诸如谷歌、OpenAI 和 DeepSeek 等一众明星公司的招牌模型。
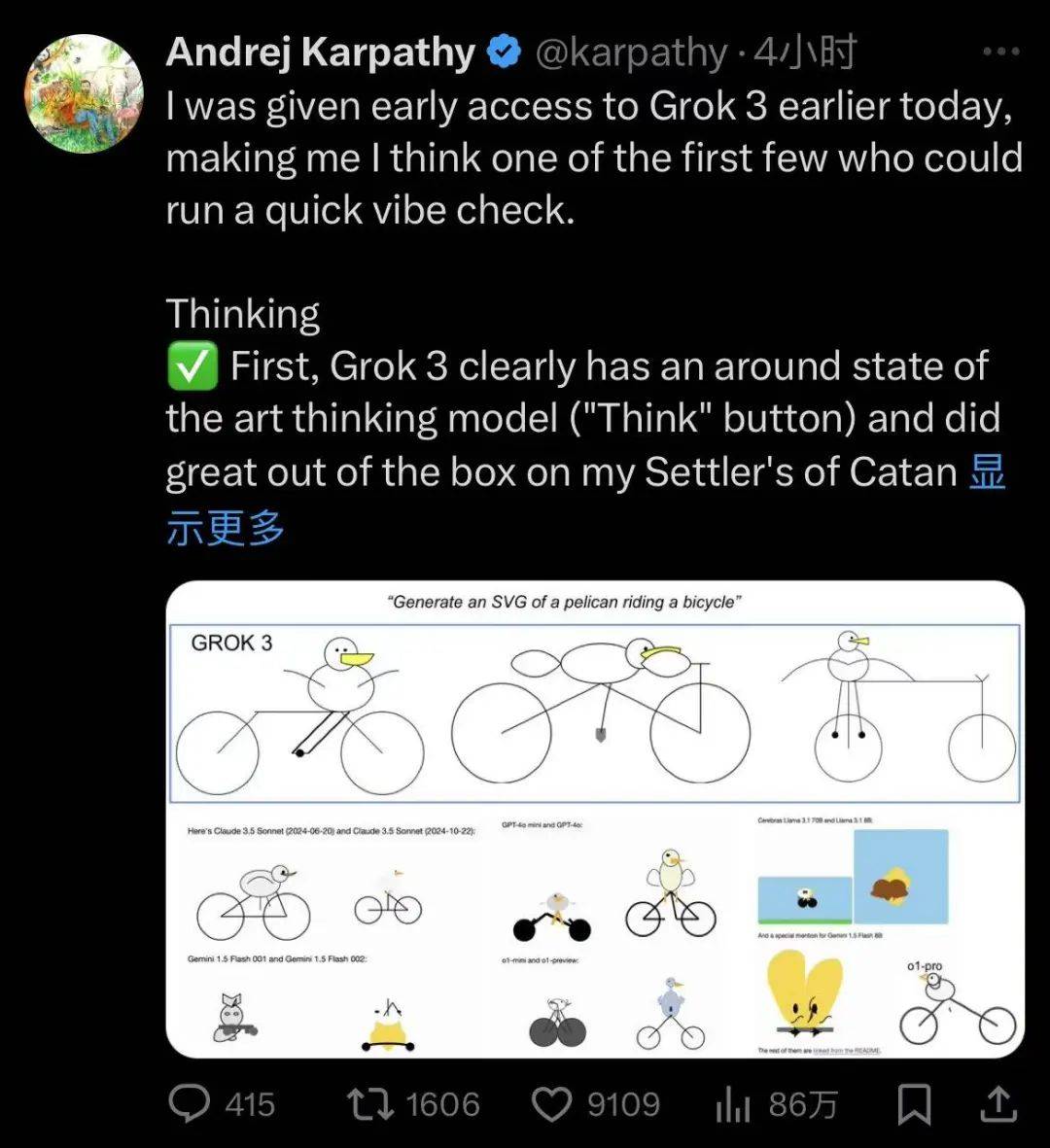
直播刚一结束,X 上就不淡定了,因为有人已经提前体验上了 Grok 3。Andrej Karpathy 说它的推理能力跟 o1-Pro 差不多,而且还要略优于DeepSeek R1 和 Gemini 的推理模型。
还有人因此用 AI 生成了一个奥特曼看到 Grok 3 发布后的视频。。。

国内外关于 Grok 3 的报道也是满天飞,“ 首个突破 1400 分( 模型在 Imarena.ai 竞技场的得分 )的模型 ”、“ 首个十万卡集群训练出来的模型 ” 等 title 看着就唬人。
在编辑部看来,Grok 3 虽然不能说炸裂,但至少从直播内容来看,它又一次延续了 AI 领域大力出奇迹的神话。
目前,Grok 3 只对部分 X 的 Premium+ 会员开放,我们的账号暂无权限,所以我们就简单从发布会的内容给大家介绍一下这个 Grok 3 究竟是什么水平。
马斯克首先是拿 Grok 和 GPT 的模型迭代速度进行了对比,针对性很强,有一种一定要分出高下的既视感。
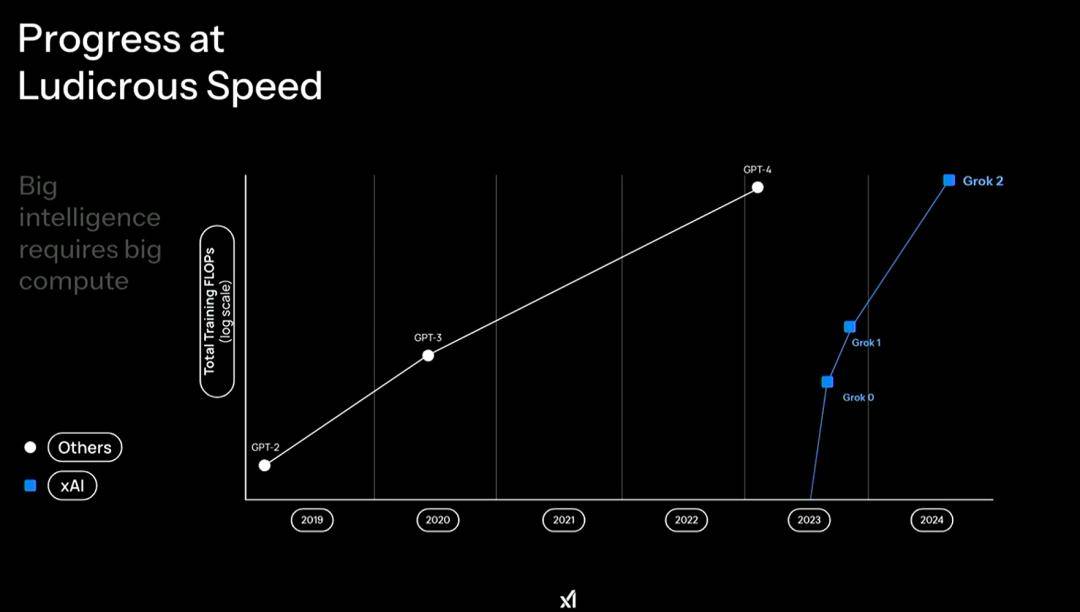
不过需要注意,这次的 Grok 3 实际上是一个模型家族,家族成员的水平各不相同,大致可以分为非推理模型和推理模型两种。
我们先来看非推理模型,也就是 Grok 3 和 Grok 3 mini。
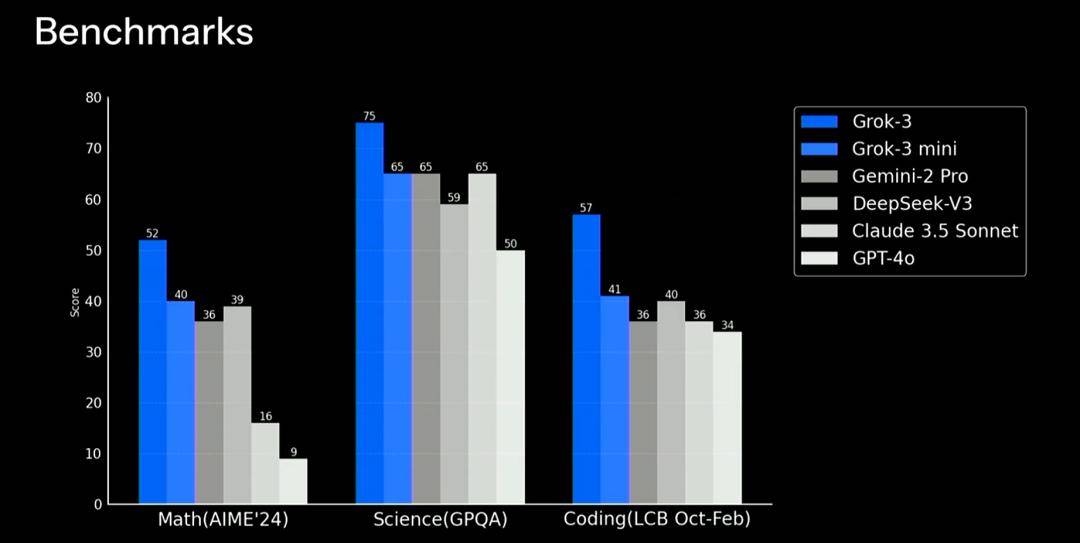
还是熟悉的Benchmark基准测试,xAI拉来了Gemini 2.0 pro、DeepSeek V3、Claude 3.5 Sonnet 还有 GPT-4o 四个模型进行对比。
在 AIME’24 美国数学竞赛、GPQA( 研究生水平科学知识问答能力的基准测试 )和代码三项测试中,Grok 3 的成绩肉眼可见高出了其他模型一大截。
Grok 3 mini 的水平虽然跟其他模型大差不差,但直播中也提到了,mini 版本可以通过牺牲一定程度的准确性,来换取更快速度的回答。
另外,在 Chatbot Arena 的盲测中,Grok 3 代号叫 “ 巧克力 ” 的早期版本也登上了榜一,分数更是史无前例破了 1400 分。
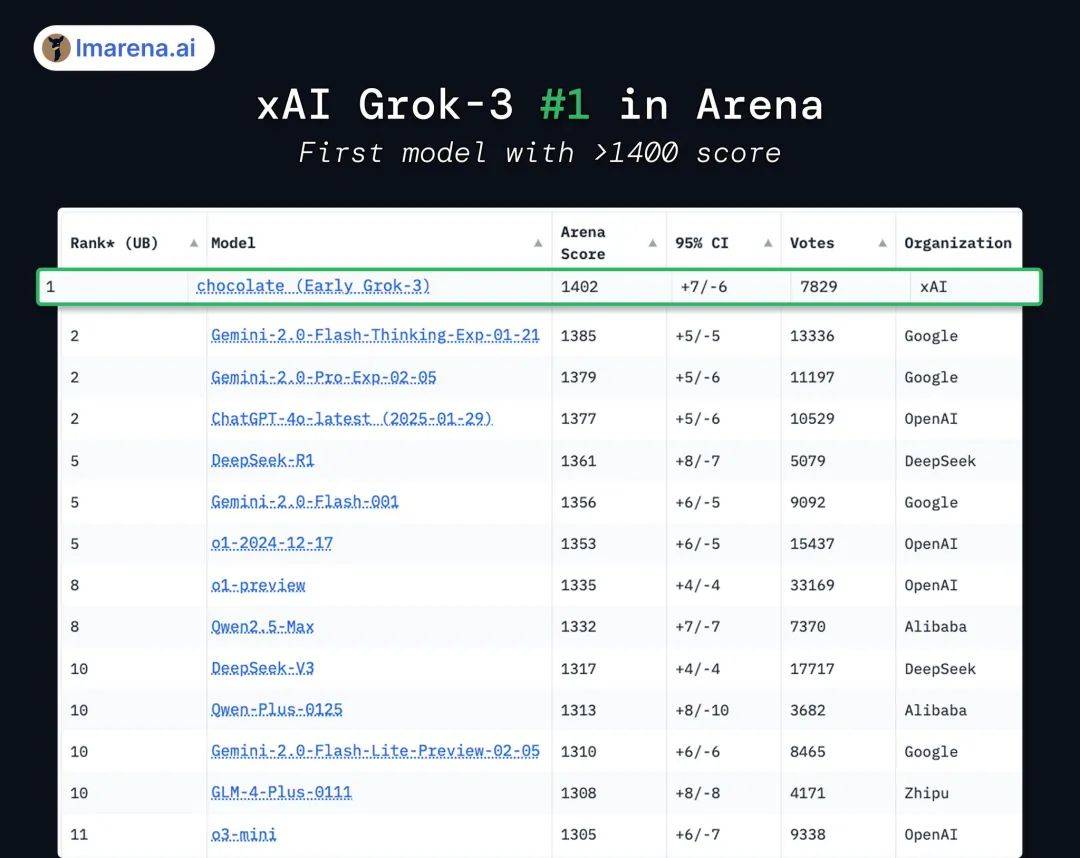
具体来看,巧克力在整体风格控制( 模型语气、表达方式的把控 )、编码、数学还有创意写作等多个方面,全都拿了第一。
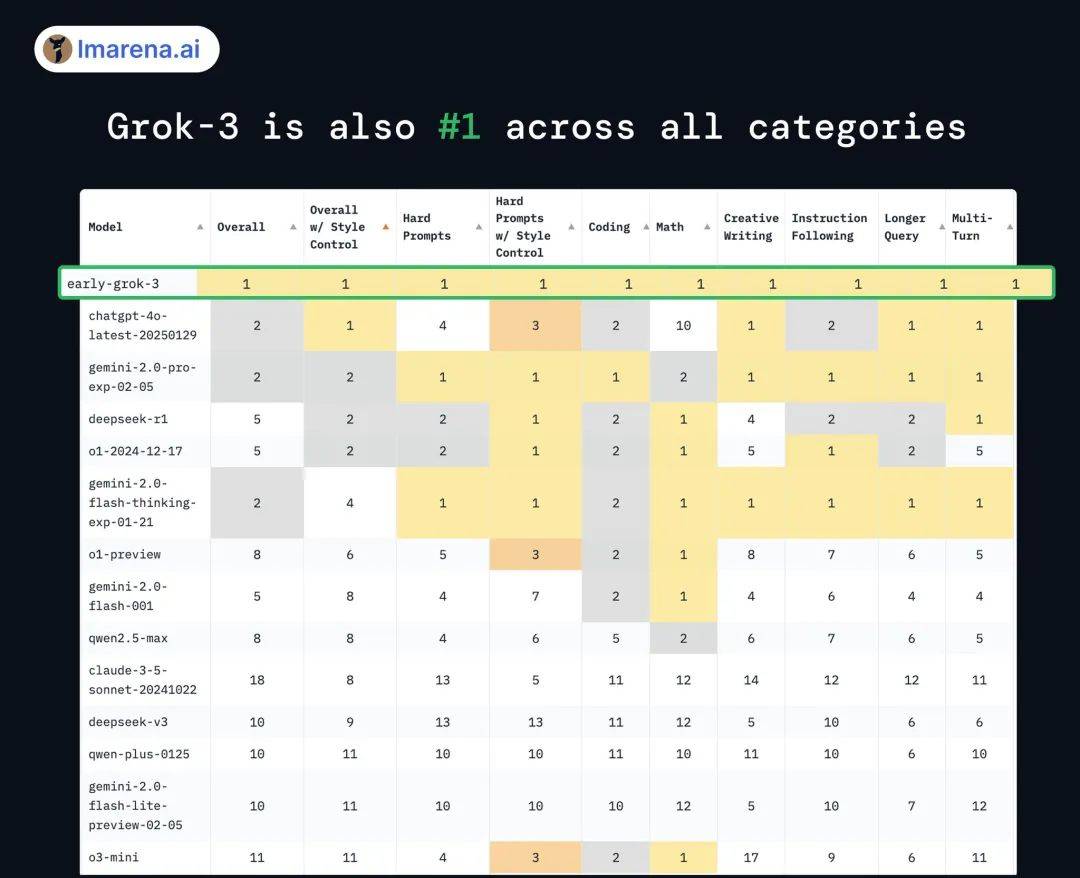
要知道,巧克力还只是早期版本的 Grok 3,今天的最新版 Grok 3 性能或许还会更强。
下面,我们再来看 Grok 3 的推理模型。
推理模型大家应该不陌生,毕竟 OpenAI 的 o1 系列、o3 mini 还有DeepSeek R1,都已经杀红眼了,思维链也是主流模型的突破方向。现在各家上新的模型里,如果不是推理模型,可能都不好意思拿出来。
所以这次,Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning 也代表 xAI 出战了。
同样还是纸面实力,表面一看还是傲视群雄的姿态。
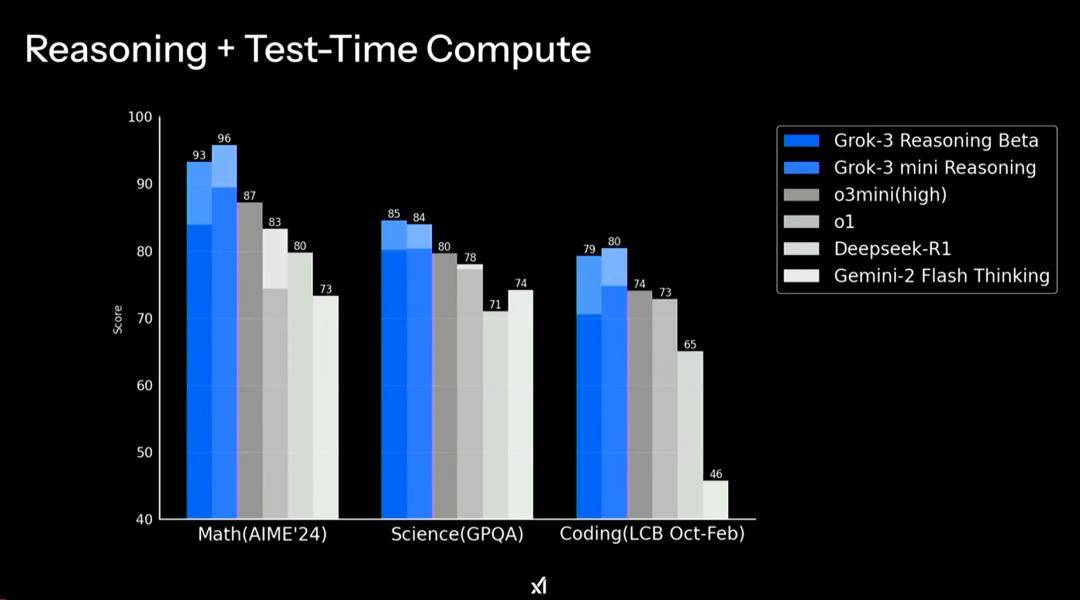
但有个需要注意的地方,这个测试中,加了 Test-Time Compute。
简单理解就是给了模型更多的时间去思考,同一个横坐标上颜色浅一点的部分,就是加时赛的成绩。
我们可以看到,如果不算上加时赛,Grok 3 两个推理模型跟其他模型的差距,并没有那么大。一旦加了时长,这差距马上就体现出来了。
换句话说,Grok 3 的推理模型思考的时间越久,表现越好,这似乎说明了 Grok 思考的质量是可以随着时间线性增长的,也代表着 Grok 有进一步的成长空间,未来有机会通过对思考的优化在更短的时间里给出更好的答案。
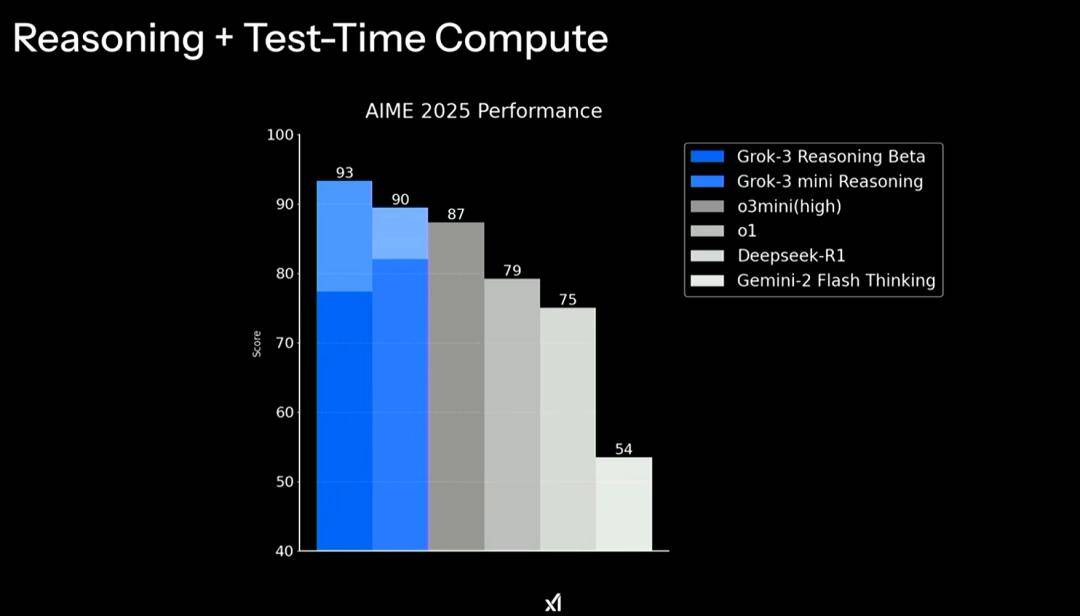
在现场,马斯克他们还展示了 Grok 3 推理模型在 2025 年 AIME 数学竞赛上的测试结果。
实际上,如果不算上 Test-Time Compute,好像还是 OpenAI 家的 o3-mini( high )的推理能力更强。
为了证明自己不是说说而已,马斯克他们在现场直接进行了效果演示。
他让 Grok 3 生成 3D 动画代码,可以看到模型一步步的思考过程。但他们也提到,这个思考过程是被模糊处理过的,理由跟 OpenAI 差不多,都说是为了防止模型被抄袭。
另外,现场还让 Grok 3 生成了一个结合俄罗斯方块和宝石迷阵两种游戏规则的新游戏。
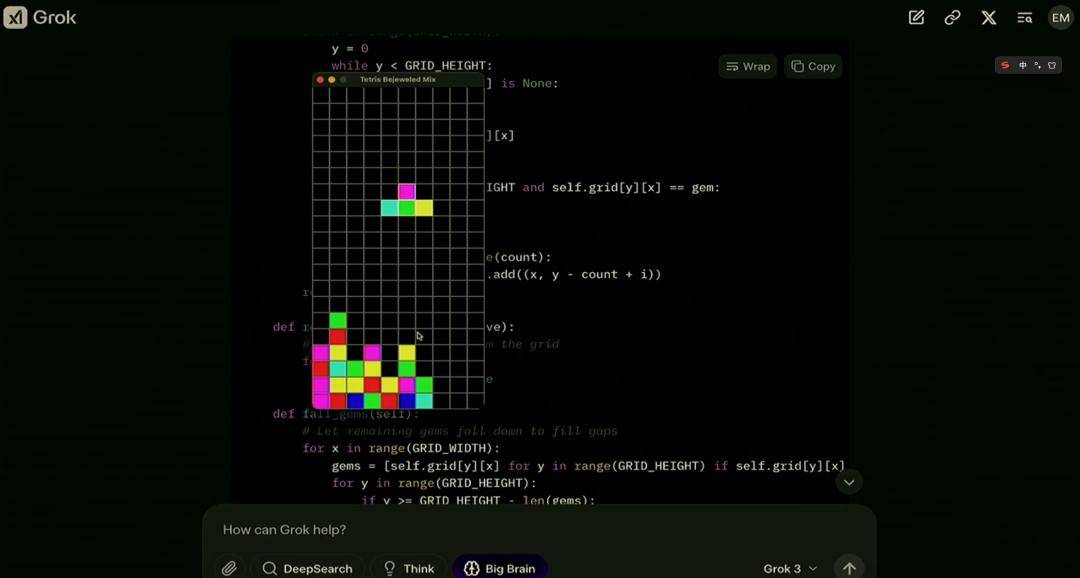
这很难不让人联想到,马斯克昨天实锤了 xAI 要成立一家 AI 游戏工作室的新闻,如果 Grok 3 的游戏制作能力真的跟现场演示的一样甚至更强,这对于整个游戏圈的影响都将是巨大的。
而且根据马斯克的说法,Grok3 在未来的两到三年内,还可能参与到特斯拉的生产还有火箭发射的过程当中。
随后,直播发布了基于 Grok 3 构建的 Deepsearch。
这个产品其实就是一个智能搜索引擎,有点像 Perplexity 的 Deep Research 和 OpenAI 的 Deep Research。
我们可以看到,当你问 Grok 3 下一次星舰发射是啥时候,左边会显示一个总体的进度条,右边则是展示浏览了哪些网页、对哪些信源进行了验证。

最后模型会得出下一次发射的时间,是 2 月 24 日。
当然,这次 Grok 3 之所以看上去如此强大,抛不开马斯克老早就在念叨的,只花了 122 天就搭建起来的 10 万卡集群。
后续,他们又花 92 天扩展到了 20 万卡集群,使出一招大力出奇迹,在不到一年的时间里,供养出了 Grok 3 。

结合这段时间大家都在争论的技术路线问题,Grok 3 的出现似乎再一次证明了算力在大模型领域的绝对力量。
不过,把 20 万卡供出来的 Grok 3 和对算力资源需求低不少的 DeepSeek V3 放在一起比较,还是有一些不公平的。
除此之外,马斯克在前几天的迪拜峰会上也提到,Grok 3 经过了合成数据的训练,能够通过检查、验证信息来反思自己的错误。
总而言之,这次的 Grok 3 的确算是拿出了点真家伙。
不过我们也注意到,在 Grok3 抢先体验的用户分享当中,有不少与宣传不符的实际测试案例。
就比如这位博主用同一组 prompt 测试了 Grok 3、o3 mini 还有Claude 3.5 Sonnet,结果 Grok 3 直接翻车。
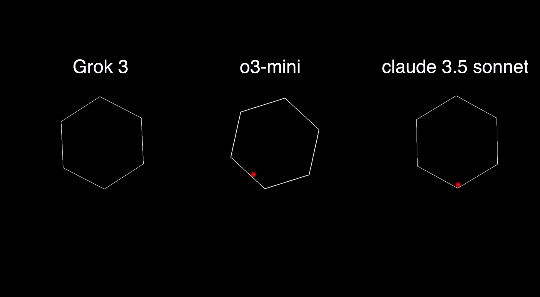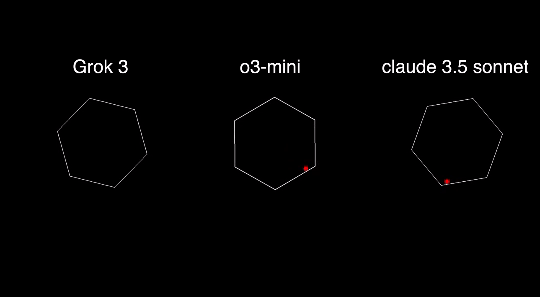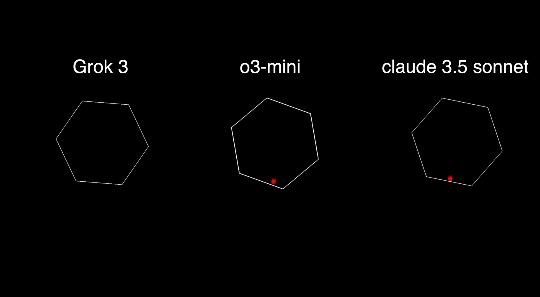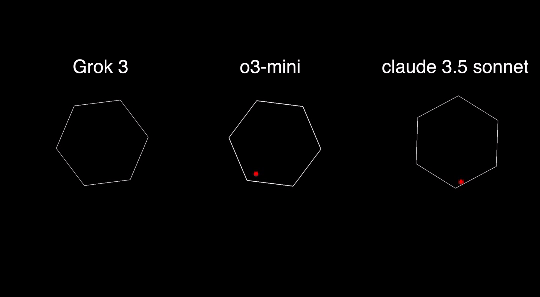
在另外一组测试中,o3 mini 的表现也要优于 Grok 3 和 DeepSeek R1。

还有放大镜选手,直接指出了发布会演示的案例里,有明显错误。
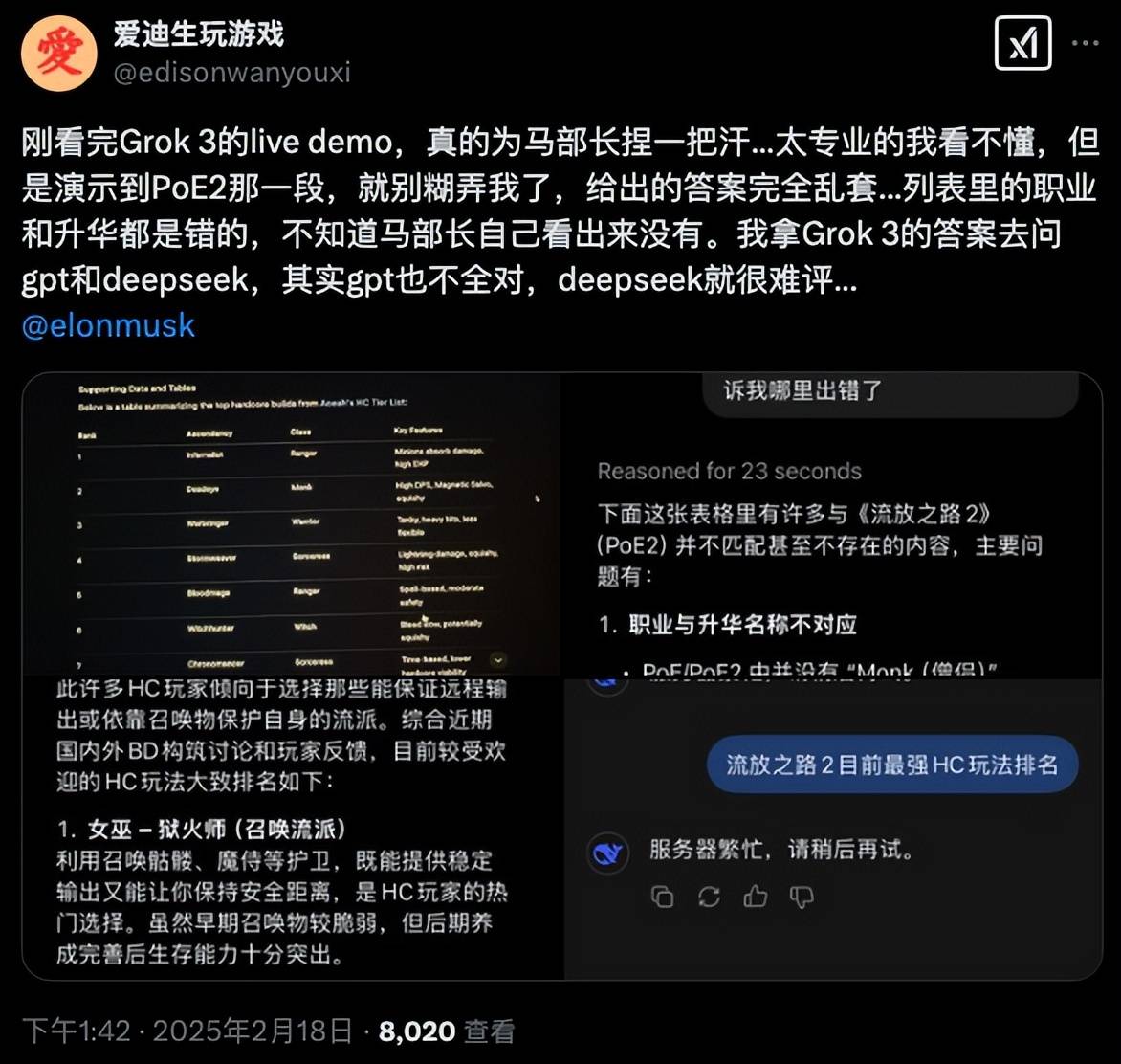
虽然我们这次没有实际上手测试,但从外部的一些实测案例来看,Grok 3 似乎也没有营销的这么神。
而且这次 Grok 3 上线后,很多人的注意力都放在了模型是否开源上。
根据马斯克的说法,xAI 一般是新模型发布后再开源旧模型,也就是说,就算开源也是老版的 Grok 2 。
看样子,来自开源阵营的压力还是不够大,马斯克想狙的还是老对手 OpenAI 。
就是不知道,已经在 X 上预告了的 GPT 4.5,能不能再反手给马斯克一个 “ 惊喜 ”。








 京公网安备 11011402013531号
京公网安备 11011402013531号