当马斯克高调推出、Sam Altman在开源策略上反复权衡之际,DeepSeek悄然发布了一项可能改变游戏规则的技术。
18日,DeepSeek CEO公布了一项由梁文锋亲自参与的研究论文成果——原生稀疏注意力(Native Sparse Attention, NSA)机制。这是DeepSeek团队在稀疏注意力领域的创新性工作,结合了算法创新和硬件优化,旨在解决长上下文建模中的计算瓶颈。
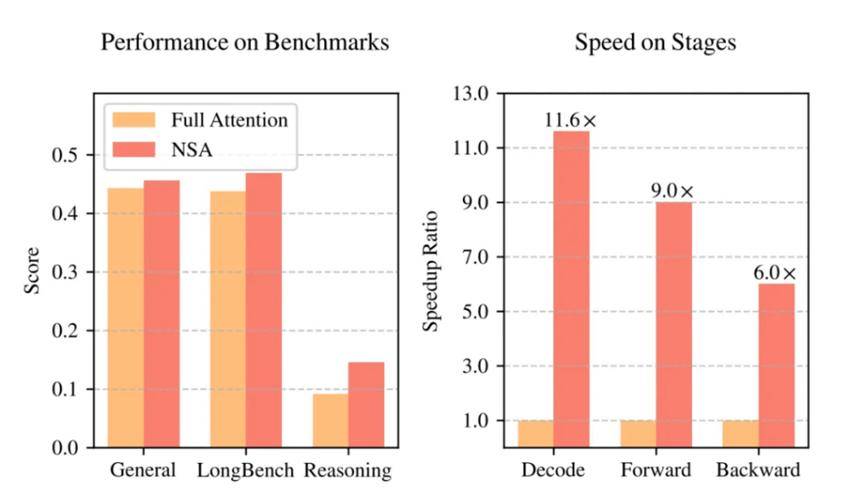
DeepSeek论文显示,NSA不仅将大语言模型处理64k长文本的速度最高提升11.6倍,更在通用基准测试中实现性能反超传统全注意力模型。在全球AI竞赛转向"硬核创新"的当口,这家低调的中国公司展示了技术破局的新范式。

值得注意的是,NSA尚未应用于DeepSeek V3的训练中。这意味着,如果后续DeepSeek将NSA整合到模型训练中,其基座模型的能力有望实现显著提升。论文中明确指出:“使用NSA预训练的模型超过了全注意力模型”。
与DeepSeek形成鲜明对比的是,xAI选择了另一条道路:对工程规模的极致追求。今日马斯克发布的Grok3使用了20万块GPU集群,而未来的Grok4更是计划使用百万块GPU、1.2GW的集群。这种“财大气粗”的做法,体现了北美在AI领域一贯的“大力出奇迹”风格。
稀疏注意力:DeepSeek NSA的创新之道
“AI革命”狂飙突进,长文本建模在AI领域的重要性日益凸显。OpenAI的o-series模型、DeepSeek-R1以及Google Gemini 1.5 Pro等,都展示了处理超长文本的强大潜力。
然而,传统Attention机制的计算复杂度随序列长度呈平方级增长,成为制约大语言模型(LLM)发展的关键瓶颈。
稀疏注意力机制被认为是解决这一难题的希望所在。DeepSeek今日提出的NSA机制,正对去年5月MLA(Multi-Layer Attention)工作的补充。NSA的核心在于将算法创新与硬件优化相结合,实现了高效的长文本建模。
动态分层稀疏策略:结合粗粒度Token压缩和细粒度Token选择,兼顾全局上下文感知和局部信息精确性。 算术强度平衡的设计:针对现代硬件进行优化,显著提升计算速度。 端到端可训练:支持端到端训练,减少预训练计算量,同时保持模型性能。
NSA的核心组件:三位一体,逐层优化
科技自媒体分析,NSA架构采用了分层Token建模,通过三个并行的注意力分支处理输入序列:
压缩注意力(Compressed Attention):通过压缩Token块来捕获全局信息,处理粗粒度的模式。 选择注意力(Selected Attention):处理重要的Token块,选择性地保留细粒度的信息。 滑动窗口注意力(Sliding Window Attention):处理局部上下文信息。
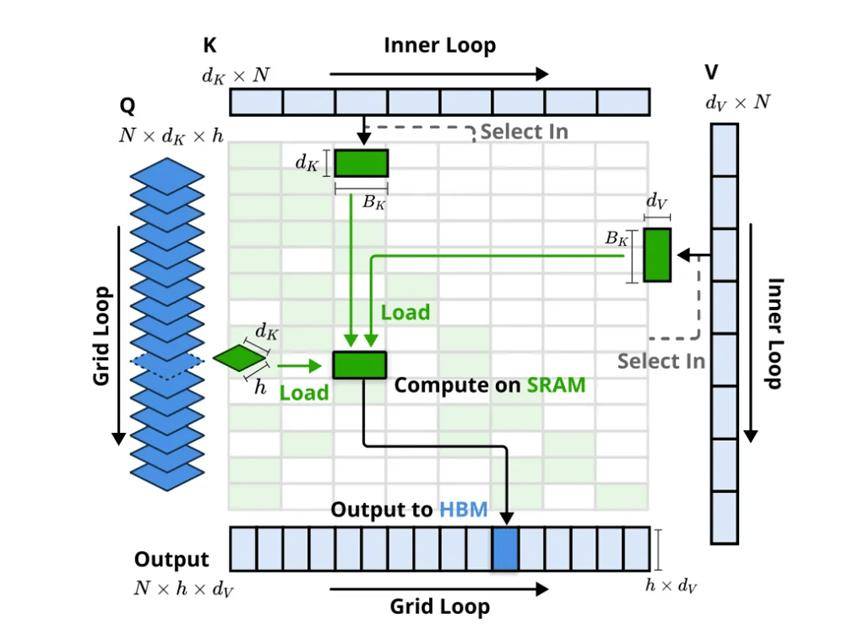
这三个分支的输出通过一个门控机制进行聚合。为了最大化效率,NSA还专门设计了硬件优化的Kernel。
具体而言,NSA在Token Compression部分,基于block粒度进行压缩计算,并插入位置信息编码。在Token Selection部分,则巧妙地借用Compression的注意力分数作为block的重要性分数,进行top-N选择,以保留关键的细粒度信息。Sliding Window部分则负责处理局部上下文。最后,通过Gating函数综合三种注意力的输出。
实验结果:性能与效率的双重飞跃
根据DeepSeek发布的实验数据,NSA技术在多个方面展现出卓越表现。
在通用基准测试、长文本任务和指令推理方面,使用NSA预训练的模型性能不仅没有下降,反而超越了Full Attention模型。更重要的是,在处理64k长度的序列时,NSA在解码、前向传播和反向传播等各个阶段都实现了显著的速度提升,最高可达11.6倍,证明了NSA在模型生命周期各个阶段的效率优势。
AI寒武纪表示:
“DeepSeek 的 NSA 技术为长文本建模带来了新的突破。它不仅在性能上超越了传统的 Full Attention 模型,更在效率方面实现了显著的提升,尤其是在长序列场景下。NSA 的 硬件友好设计和 训推一体化特性,使其在实际应用中更具优势,有望加速下一代 LLM 在长文本处理领域的应用落地。”
“DeepSeek此次使用了Triton,而没有提及英伟达专用库和框架。Triton底层可以调用CUDA,也可以调用其他计算平台的框架,如AMD的ROCM,甚至国产计算卡。结合NSA降低了浮点算力和内存占用门槛的特性,这或许暗示了DeepSeek在模型研发阶段,就已经开始考虑未来适配更多类型计算卡,为更广泛、更普遍的开源做准备。”
xAI的Grok3:算力堆砌的“极致”
与DeepSeek形成鲜明对比的是,xAI选择了另一条道路:对工程规模的极致追求。Grok3使用了20万块GPU集群,而未来的Grok4更是计划使用百万块GPU、1.2GW的集群。这种“财大气粗”的做法,体现了北美在AI领域一贯的“大力出奇迹”风格。
然而,信息平权的分析指出,尽管xAI通过超大集群在短时间内实现了对之前SOTA(State-of-the-Art)模型的反超,但其投入产出比并不理想。相比DeepSeek V3,xAI以50倍的成本实现了30%的性能提升。这表明,单纯在预训练阶段投入巨额算力,其收益可能并不如预期,将资源投入到RL(强化学习)后训练阶段可能更为划算。








 京公网安备 11011402013531号
京公网安备 11011402013531号