关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Data Ingestion Strategies, Data Warehouses, Data Lakes, Streaming Ingestion, Batch Ingestion, Zero Etl Integrations]
导读数据摄取通常是构建数据管道的第一步。随着非结构化数据、增量数据以及像Apache Iceberg这样的开放表格式等数据类型的不断增加,构建持久的数据管道、立即落地数据、应用所需的模式结构,并为不同类型的用例提供高质量输出变得越来越重要。参加本次讨论,探索可以帮助解决不同数据摄取挑战的具体解决方案。了解如何使用Amazon Glue、Amazon Kinesis、Amazon Redshift和Amazon OpenSearch Service等服务来高效摄取和处理数据的稳健架构和关键策略。
演讲精华以下是小编为您整理的本次演讲的精华。
在不断演进的数据驱动型企业领域中,有效地从不同来源摄取和处理数据的能力已成为当务之急。这正是亚马逊云科技 re:Invent 2024活动“使用亚马逊云科技解决不同数据摄取用例”环节的核心主题。演讲者Rahul Sonavane和Chinmay Jina Shimodavara是分析和人工智能/机器学习领域的专家,他们全面探讨了数据摄取面临的挑战和解决方案。
演讲一开始就用一个发人深省的比喻,将数据摄取的过程比作灭火。正如通过管道引导水流是扑灭火灾的关键一样,将数据引导至适当的目的地对于实现预期的业务成果也至关重要。这个比喻强调了制定明确的数据摄取策略的重要性,这也贯穿了整个会议。
深入探讨现代数据架构的演进,演讲者强调了日益复杂多样的数据源,需要一种健壮且灵活的摄取方法。他们着重强调了解不同的用例和目标系统(如数据仓库和数据湖)的重要性,在这些系统中消费者可以访问和分析数据。
其中一项关键服务是亚马逊云科技 Data Replication Service (DRS),这是数据传输领域的一个游戏规则改变者。DRS简化了在源和目标之间复制数据的过程,无需创建自定义管道。演讲者强调了它与Amazon Aurora MySQL、PostgreSQL、RDS MySQL和DynamoDB无缝集成,用于将数据加载到Amazon Redshift,以及与第三方应用程序(如Salesforce、Zendesk和ServiceNow)连接的能力。
对于寻求近实时数据仓库能力的企业,演讲者阐明了Redshift直接从流应用程序(如Amazon Kinesis Data Streams或Apache Kafka(Amazon MSK))摄取数据的能力。这一功能使摄取的数据表现为物化视图,让用户能够结合实时和历史数据进行全面分析。
S3 Auto COPY功能是另一个值得关注的亮点,它允许Redshift自动将Amazon S3上的文件数据传输到表中,无需编排作业或发出COPY命令。这种精简的方法减少了运营开销,加快了洞见获取的速度。
转移到数据湖,演讲者深入探讨了它们在存储和摄取各种格式(如Parquet、Avro和CSV)数据时所提供的灵活性,并具有有效的分区机制。服务如Amazon Glue、Amazon Kinesis Data Streams、Amazon MSK和Amazon Kinesis Data Firehose被视为批量和实时数据摄取到数据湖的强大工具。Amazon Glue尤其提供了70多个开箱即用的连接器,用于与异构数据源集成,用户甚至可以引入自定义连接器。
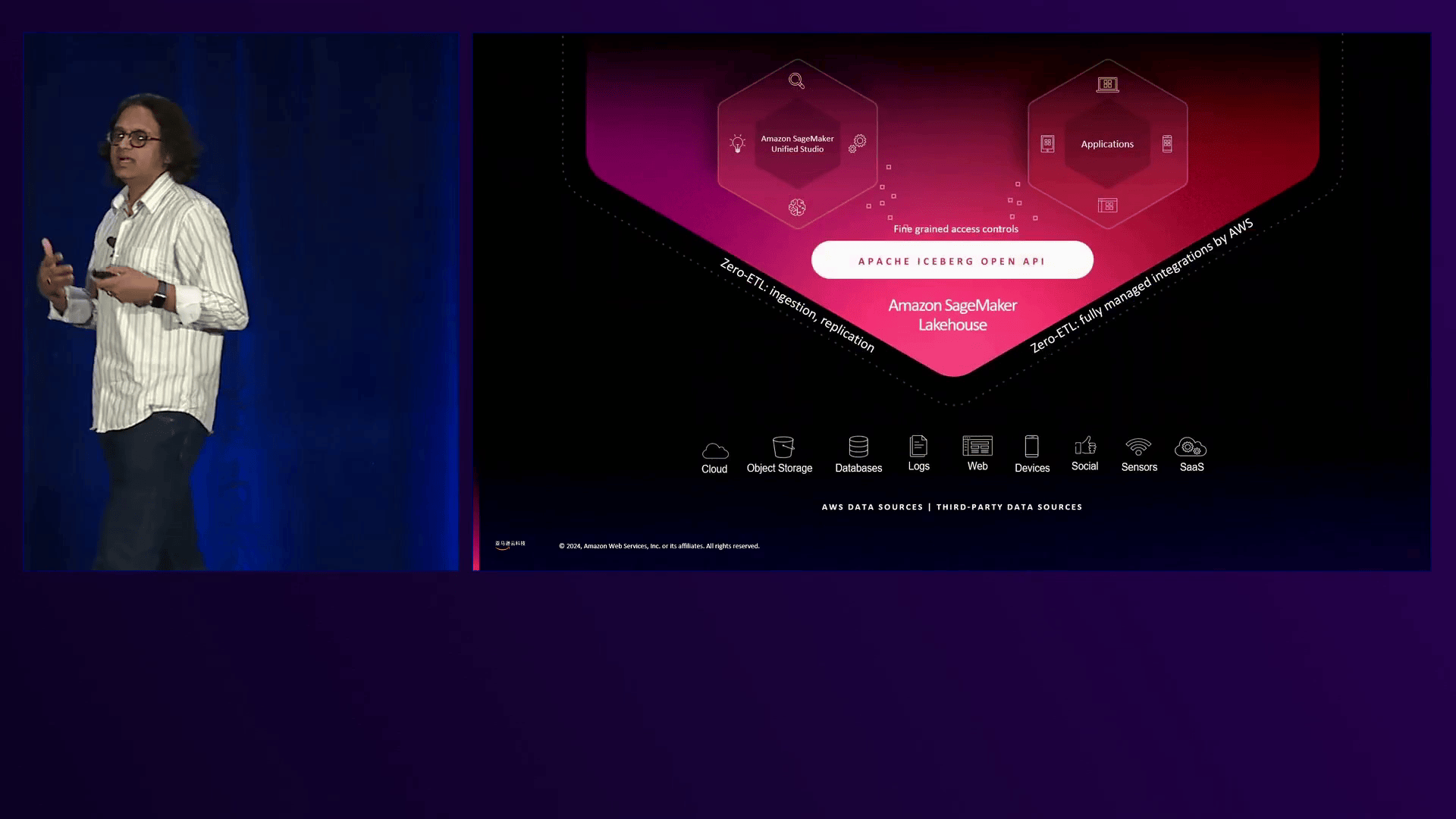
会议期间介绍的一个值得注意的概念是“lakehouse”方法,它弥合了数据仓库和数据湖之间的差距。Amazon SageMaker Lakehouse是一种前沿解决方案,它整合了来自各种源(包括数据仓库、数据湖、运营数据源和应用程序)的数据。Amazon Glue在将数据从第一方和第三方源摄取到SageMaker Lakehouse中发挥着关键作用,实现了数据的统一视图,以便进行分析。
演讲还阐述了SageMaker Lakehouse生态系统中对开放表格式(如Apache Iceberg、Hudi和Delta Lake)的支持。这些格式支持在Amazon S3上进行ACID事务,并得到Amazon Glue和Amazon EMR等工具的支持,从而实现了在现代数据湖中高效摄取和处理数据。
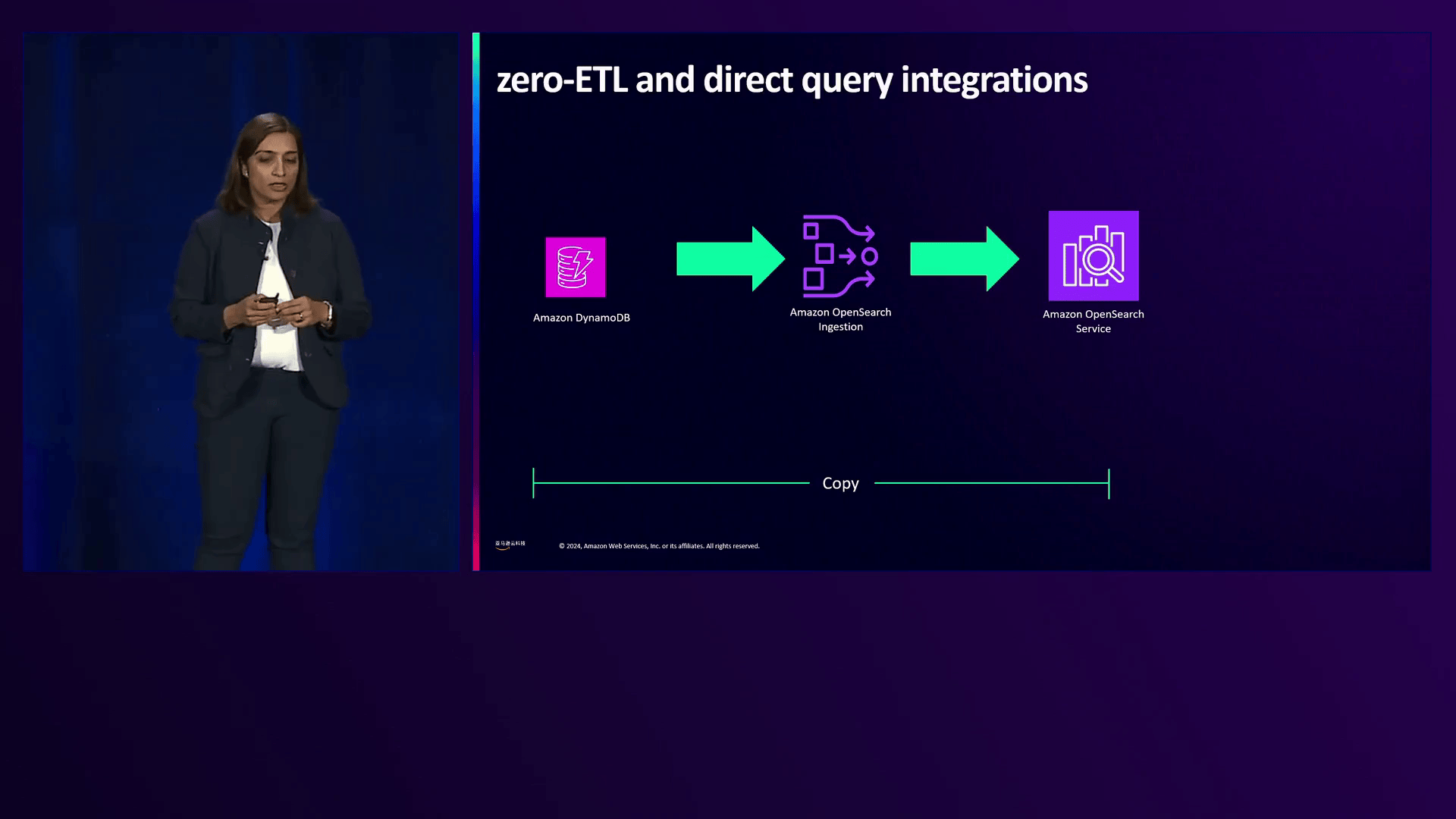
转向日志和搜索分析领域,演讲者介绍了Amazon OpenSearch Service及其零ETL集成。这些集成使用户能够直接从OpenSearch查询数据,无需摄取,从而减少了运营开销。这些集成涵盖了广泛的源,包括DynamoDB、documentDB、S3、CloudWatch Logs和Security Lake。一个客户案例突出了一个场景,其中一家公司希望使用OpenSearch分析存储在DynamoDB中的反馈数据。以前,他们必须启用DynamoDB Streams、编写自定义工作流程并将数据转换为JSON格式,但零ETL集成简化了这一过程。
对于从S3摄取数据,演讲者讨论了一个用例,其中电信客户每天产生TB级别的数据。与其将所有数据摄取到OpenSearch(这在经济上是不可行的),不如只摄取最近24小时的数据,并使用之前介绍的直接查询集成直接从S3查询剩余数据。
演讲还涵盖了与CloudWatch Logs和Security Lake的直接查询集成,使用户能够直接从OpenSearch查询高容量、高价值的数据,而无需摄取。此外,用户可以将查询的最终结果摄取到OpenSearch中,以获得低延迟访问,或构建具有复杂聚合的物化视图,只摄取几KB的数据而不是TB级别的原始数据。
为了说明这些服务的实际应用,演讲者展示了一个参考架构,阐述了针对不同目标系统(包括Redshift、数据湖、SageMaker Lakehouse和OpenSearch)的高效数据摄取模式和策略。该架构利用了托管服务、零ETL集成和最佳实践,以确保可扩展性、可靠性和经济效益。该架构包括产品数据、供应商数据、客户数据和点击流数据流入Amazon Aurora、DynamoDB和Kinesis Data Streams,以及SAP和Salesforce等SaaS应用程序、S3上的数据文件,以及来自各种应用程序的日志数据。
在整个会议过程中,演讲者强调在实施这些数据摄取解决方案时利用关键策略和最佳实践的重要性。例如,在使用Amazon Glue进行批量摄取时,他们建议选择合适的工作类型、启用自动扩展,并使用最新版本以获得性能改进。同样,对于使用Kinesis Data Streams和Amazon MSK进行流分析,他们建议采用数据聚合、压缩等技术,并利用生产者和消费者库以获得最佳吞吐量和成本效率。具体建议包括使用Kinesis Producer Library进行聚合、压缩和批处理,以及启用Enhanced Fan-Out以支持多个消费者,每个消费者实现2MB/秒的吞吐量。
对于Amazon MSK,演讲者建议对于高吞吐量需求使用Express Brokers,并监控CloudWatch指标以确保CPU使用率(约60%)和存储利用率的最佳水平。在运行Flink应用程序时,他们强调通过检查点和快照实现容错,控制并行度以获得吞吐量,并使用正确的连接器依赖项以避免数据不一致或运行时挑战。
演讲还强调了客户成功案例和用例,进一步加强了所讨论解决方案的现实世界适用性。其中一个例子涉及一位客户希望在其数据湖中分析来自Salesforce的聊天对话。通过利用零ETL集成,客户可以无缝地摄取数据,而无需自定义ETL管道或连接器管理的开销。
另一个客户案例关注一家零售公司需要从各种Web服务器和应用程序捕获和分析日志,并使用OpenSearch。在引入OpenSearch Ingestion之前,该公司必须在EC2实例上维护摄取管道,产生了大量运营开销。有了OpenSearch Ingestion,公司可以卸载这一负担,让OpenSearch根据其需求自动扩展。
总之,亚马逊云科技 re:Invent 2024活动上的“使用亚马逊云科技解决不同数据摄取用例”环节全面深入地探讨了数据摄取面临的挑战和解决方案。演讲者Rahul Sonavane和Chinmay Jina Shimodavara熟练地阐述了现代数据架构的错综复杂,介绍了一系列亚马逊云科技服务和策略,专门针对不同的用例和目标系统。无论是数据仓库、数据湖、lakehouse还是搜索分析引擎,该演讲都提供了高效、可扩展的数据摄取的整体方法,让企业能够充分发挥数据的潜力,并推动数据驱动的决策。
下面是一些演讲现场的精彩瞬间:
演讲者生动地比喻了一场火灾和消防栓的情况,以说明延迟或阻碍解决问题的做法是徒劳无益的。

Redshift能够直接从Amazon Kinesis Data Streams或Apache Kafka等源摄取流数据,通过将实时数据和历史数据结合起来进行分析,实现了近乎实时的数据仓库。
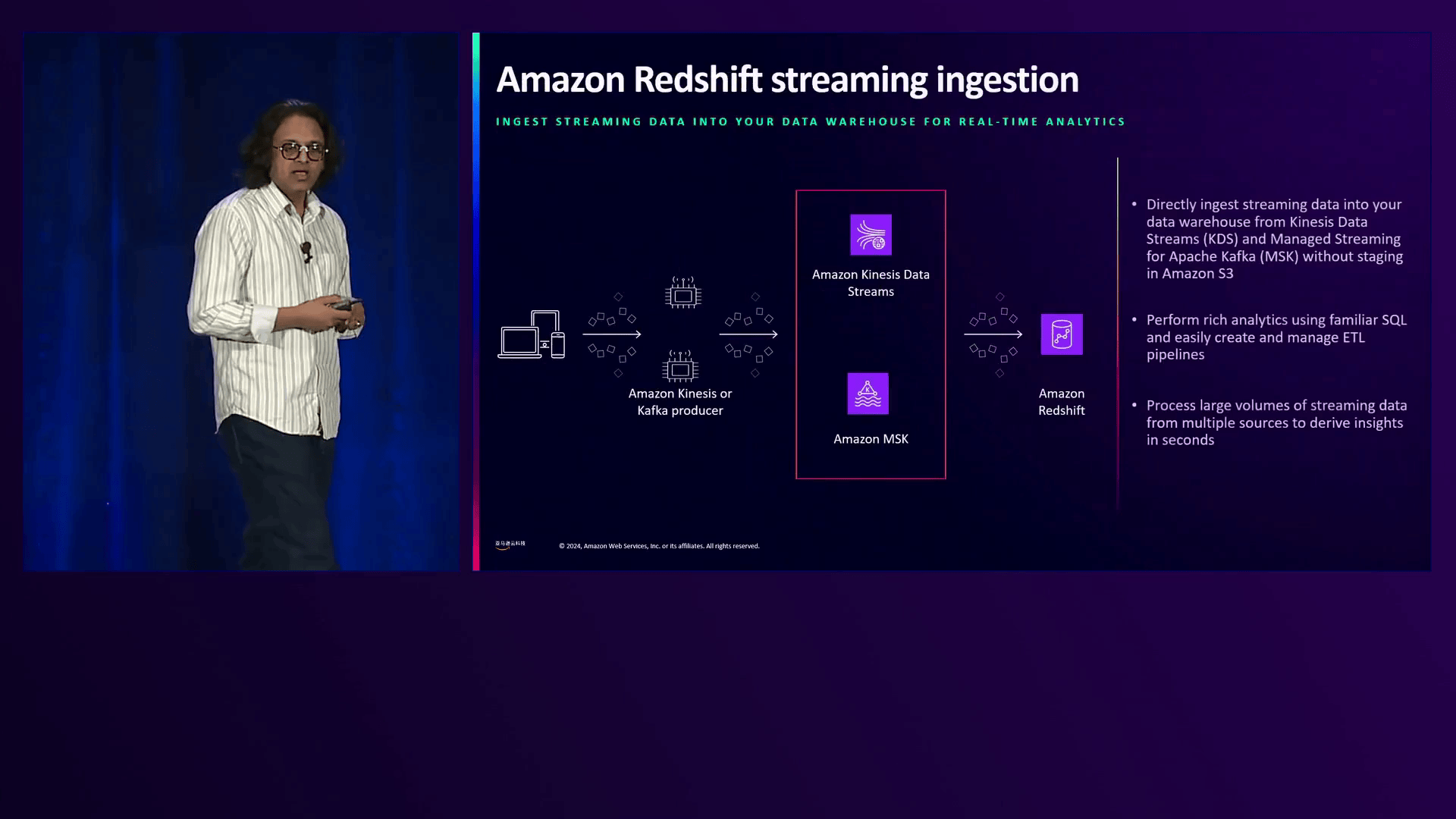
Amazon Kinesis Data Streams能够以多个GBps的速度摄取和传输大量数据,并提供完全托管和可扩展的吞吐量能力。

Amazon Kinesis Firehose能够从多个源摄取数据,并以各种格式和分区存储在S3上,配合集成的计算服务,有助于高效的数据分析。
SageMaker Lake House提供灵活的数据摄取选项,包括Amazon SageMaker Unified Studio、Amazon Glue和支持Apache Iceberg开放API的第三方工具。
介绍了DynamoDB与OpenSearch的无缝集成,无需自定义工作流程,简化了数据分析过程,有助于获得更好的业务洞见。
在这篇全面的叙述中,演讲者们深入探讨了在亚马逊云科技上进行数据摄取的复杂世界,探索了各种适用于不同用例的策略和服务。他们首先强调了有效数据摄取的重要性,将其比作引导水流以扑灭火灾。然后,叙述深入探讨了针对数据仓库(如Amazon Redshift)的摄取模式,利用亚马逊云科技 Data Replication Service (DRS)、S3 AutoCopy和流式摄取等服务。
接下来,对于数据湖,演讲者们强调了Amazon Glue从异构源进行批量和实时摄取的能力,以及Amazon Kinesis Data Streams、Amazon MSK (Managed Streaming for Apache Kafka)和Amazon Kinesis Data Firehose等服务。他们还介绍了Lakehouse架构的概念,该架构通过Amazon SageMaker Lakehouse统一了数据仓库和数据湖。
然后,叙述探讨了将数据摄取到分析和搜索引擎(如Amazon OpenSearch Service)中,展示了与DynamoDB、documentDB以及S3、CloudWatch Logs和Security Lake等各种数据源的零ETL集成。演讲者还讨论了构建一个参考架构,该架构包含这些摄取服务和针对不同目标系统的策略,强调了简单性和效率的原则。
最后,演讲者强调了在亚马逊云科技上设计良好架构、可靠、健壮和经济高效的数据摄取系统时,利用托管服务、零ETL集成和关键策略的重要性。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。









 京公网安备 11011402013531号
京公网安备 11011402013531号