作者丨青橙财经 青风
DeepSeek的冲击波仍然在持续扩散。
春节期间DeepSeek登顶中国、美国、德国等全球超100个国家和地区的iOS应用总榜第1,下载量超越ChatGPT;上线20天,日活用户突破2000万;72小时内16家国内芯片企业完成适配;国内外云计算平台争先恐后上线支持,国内三大运营商集体接入其服务,国家超算互联网同步上线;众手机品牌和汽车品牌纷纷官宣接入……
如今DeepSeek不仅成为全球增速最快的AI应用,更引爆了一场横跨芯片、云计算、运营商、应用层、终端设备甚至资本市场的全产业链狂欢。这场狂欢背后,不仅是技术的胜利,更是国内AI商业生态的集体突围。
01「国产算力极速适配」
过去十年,国产AI芯片始终活在英伟达的阴影下。华为昇腾团队负责人曾坦言:“没有生态的芯片,就像没有子弹的枪。”而DeepSeek的出现,让这把枪终于扣动了扳机。
DeepSeek通过融合MLA(多头潜在注意力)与MOE(专家混合模型)技术,并采用RL(强化学习)推理算法,实现了PTX算力的优化。这些技术创新不仅提升了AI模型的性能,还大幅降低了训练和推理成本。DeepSeek的低成本和高性能特性为国产AI芯片厂商提供了技术验证和商业化机会。
据不完全统计,DeepSeek开源协议发布72小时内,已有至少16家国产AI芯片企业陆续宣布完成对DeepSeek模型的适配或上架服务。这些企业包括华为昇腾、沐曦、天数智芯、摩尔线程、海光信息、壁仞科技、太初元碁、云天励飞、燧原科技、昆仑芯、灵汐科技、鲲云科技、希姆计算、算能、清微智能和芯动力。

*图源华为云公众号
华为昇腾与硅基流动联合发布的DeepSeek推理服务,首次实现了国产芯片与国际顶级GPU的性能对标;燧原科技在庆阳、无锡等地的智算中心部署数万张自研加速卡,将模型推理成本降低40%;壁仞科技仅用数小时就完成对DeepSeek全系列模型的适配,创下国产芯片响应速度新纪录。这场适配竞赛背后,是国产芯片企业憋了多年的技术积累——摩尔线程的夸娥智算集群、天数智芯的FP8混合精度架构,都在与DeepSeek的碰撞中找到了商业化落地的突破口。
国产芯片厂商通过与DeepSeek的合作,加速了深度学习框架优化和分布式训练适配,有助于推动“国产算力+国产大模型”闭环生态的构建。中信证券测算,2025年国产AI芯片市场份额有望从不足15%跃升至35%。
市场正在用真金白银投票。中信证券数据显示,2025年1月国产AI芯片出货量环比暴涨180%,英伟达A100二手价格暴跌40%。华为昇腾产品线总裁李振亚直言:“过去客户总问‘能不能兼容CUDA’,现在问题变成了‘什么时候适配DeepSeek’。”
02「云厂商和运营商的狂欢」
DeepSeek晋升科技顶流,给各行各业和普通民众进行了一次空前的AI普及,尤其DeepSeek极致的使用成本,例如DeepSeek-R1的API定价仅为OpenAI旗舰模型的约3%。这必将催生海量的智能升级需求。另外,DeepSeek还完全开源,允许开发者自由调用和二次开发,中小软件企业可基于开源模型开发行业专属AI应用。
DeepSeek低成本、高性能且开源的特点将不仅吸引大量开发者和企业参与,更为云计算公司及运营商带来了新的商业化机会。“得模型者得天下。”
国际巨头争相“倒戈”,微软Azure、亚马逊AWS早已悄然接入DeepSeek,英伟达NIM平台甚至为其优化CUDA兼容方案。当西方还在讨论“技术脱钩”时,商业利益已让巨头们用脚投票。

*图源国家超算互联网平台
国内的云厂商和智算企业也在积极发力。截至目前,已有华为云、天翼云、腾讯云、阿里云、百度智能云、火山引擎、京东云、联通云、移动云、浪潮云等至少10家国内云服务巨头,无问芯穹、硅基流动、云轴科技ZStack、PPIO派欧云、超算互联网、青云科技、算力互联、并济科技、优刻得、神州数码、并行科技、北京超算等至少12家智算企业宣布了对DeepSeek的支持。与此同时,中国移动、中国电信、中国联通三大基础电信企业均已全面接入DeepSeek开源大模型,并在多场景、多产品中实现应用。
当三大运营商带着自家机房杀入战场,算力价格战比预想中更猛烈——中国电信“息壤”平台实现全栈国产化推理,移动云推出“开箱即用”的DeepSeek定制方案,联通云甚至允许客户在私有化与公有化部署间自由切换。咨询机构Omdia的数据显示,中国AI算力单价在三个月内下降27%,而利用率提升了1.8倍。
在资本市场,DeepSeek已摇身变成了点金石,最近几日,青云科技、并行科技等公司股价大幅攀升,三大运营商虽体量庞大,也一度录得较高的提升。
这场革命正在改写游戏规则。就像当年云计算颠覆IT基础设施,如今云厂商主导的算力民主化,让中小企业的AI门槛从“攀登珠峰”变成了“地铁通勤”。民生证券认为,云厂商是DeepSeek能力的“放大器”,算力门槛的下降,给予云厂商们以低门槛部署“杀手级”应用的机遇将不断扩大。
03「AI应用迎来爆发元年」
DeepSeek激活创新竞争,AI应用迎来“安卓时刻”。中信建投证券近日发布研报称,回顾安卓与i0S应用的发展,我们率先提出不应只关注大模型本身的用户数及活跃度,更应该关注开发者,尤其是中小开发者的数量。
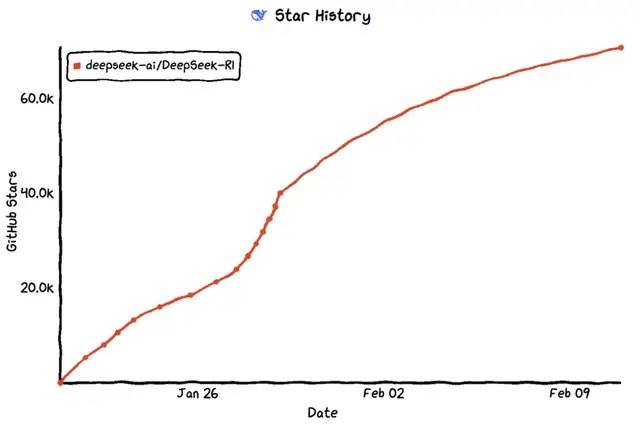
*图源GitHub
GitHub的Stars是项目在社区中受欢迎程度的直接指标,Fok则表示项目累计被用户拷贝的数量,两个指标均代表项目上线至今的关注度和用户喜爱度。DeepSeek V3和R1两个项目上线至今均不足2个月,但它们的累计Star和Fork均与上线时间更早的Llama接近,显著高于24年4月发布的Llama3,直接反映了开发者对DeepSeek开源模型的高认可度。目前DeepSeek R1在GitHub上的开发者点赞数量已经达到约5.7万。根据GitHub、Hugging Face社区上的开发者实测,经过R1微调的80亿参数小模型可以在个人笔记本中运行,本地化部署门槛显著下降,应用的开发将迎来百花齐放。
事实上,DeepSeek也正在为众多行业的智能化转型注入了强大动力。“当全社会都在谈论DeepSeek的时候,无疑会加速AI的普及。这对我国深入开展‘人工智能+’行动是巨大的机遇,AI在制造、医疗、教育、交通、农业等多个领域都有机会发展壮大。”有分析师表示。
例如,阅文集团将DeepSeek-R1模型应用于智能写作辅助工具中;网易有道全面拥抱 DeepSeek-R1加速在线教育智能化升级;钉钉AI助理接入DeepSeek三天后,用户创建的智能助手数量突破百万;联想“小天”个人智能体上线首日,客服咨询量下降60%……
这些只是冰山一角。中信建投证券研报预测,2025年将成为中国AI应用爆发元年:医疗领域的辅助诊断系统响应速度快过医生翻病历,金融风控模型的决策时间缩短至毫秒级,甚至直播电商的虚拟主播已能连续八小时不“卡壳”。
*图源华为小艺助手
另外一个有意思的现象是,最近,手机厂商和汽车厂商也纷纷加入DeepSeek的怀抱。短短几天,华为、荣耀、OPPO、中兴旗下努比亚、红魔等手机品牌全部官宣接入DeepSeek-R1。有爆料人称vivo也确认将接入DeepSeek。在汽车领域,吉利和广汽也相继宣布与DeepSeek完成深度融合,推动智能汽车AI科技的发展。
其实,现在不管是各大手机品牌,还是汽车品牌,早已推出了自己的智能助手,比如华为小艺、荣耀YOYO等,多数还将AI融入到了操作系统中。而之所以还要接入一个外来的DeepSeek,无非是想借势其热度,增加一个吸引消费者的买点而已。
此外,DeepSeek低成本模型还有望推动AI眼镜、AI玩具等终端设备的商业化落地,2025年预计还有可能成为AI硬件爆发元年。很多分析认为,眼镜是非常好的AI创新载体,今年极有可能迎来“百镜大战”。对比而言,当前AI眼镜搭载的大模型,在性能上还难以比肩DeepSeek,资源消耗也更高。横空出世的DeepSeek预计将为AI眼镜再填一把火。
可以说,DeepSeek 就像一把万能钥匙,为各行业打开了智能化升级的大门,让传统产业在 AI 的加持下焕发出新的生机与活力。
04「其他大模型厂商有点懵」
汝之蜜糖,彼之砒霜。DeepSeek的崛起对全球大模型竞争格局产生了显著冲击,国内外主流厂商纷纷采取技术升级、生态合作、定价调整等策略应对挑战。
OpenAI首当其冲。2月1日凌晨,OpenAI紧急发布全新推理模型o3-mini,复杂推理和对话能力显著提升,可与联网搜索功能搭配使用,并展示完整的思考过程。新的o3-mini模型提供免费使用权限,不过其定价仍高于竞争对手DeepSeek。2月6日,OpenAI又宣布扩大ChatGPT搜索功能的用户范围,任何人无需注册,就可以使用ChatGPT的搜索功能,降低用户使用门槛。
OpenAI首席执行官山姆・奥特曼承认DeepSeek的崛起削弱了OpenAI的技术领先优势,表示未来将重新制定开源战略,首席产品官Kevin Well也表示公司正考虑将非前沿的旧模型如 GPT-2、GPT-3 等开源。
在DeepSeek的光芒之下,国内不论是互联网大厂,还是“AI六小龙”也均显得有些黯然失色。
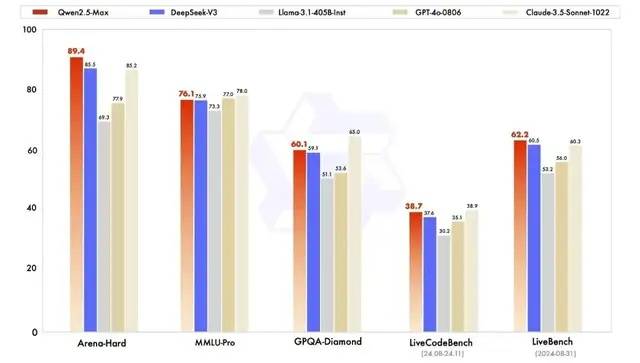
*图源通义千问
不过,阿里通义反应最为迅速。1月29日,阿里云正式升级了通义千问旗舰版模型Qwen2.5-Max,预训练数据超过20万亿 tokens,在多项公开主流模型评测基准上录得高分,超越了包括DeepSeek-V3在内的目前全球领先的开源 MoE 模型以及最大的开源稠密模型。
最近几天,据科技媒体The Information等援引消息人士报道,苹果智能可能会接入阿里通义。iOS 18.4或将于4月正式发布,中文版的Apple Intelligence也将于该版本中正式亮相,届时可能会融入阿里巴巴的通义千问Qwen系列大模型,为用户带来更高效的语音助手、智能推荐以及个性化服务等。苹果庞大的用户量无疑将成为通义千问大模型的发展助推力。
而在国内所有的大模型厂商中,最尴尬的或许是百度。百度几乎是国内最早宣布“All in AI”的大厂,距今已经有十年时间了。但截至目前,不管是技术水平,还是产品体验及用户口碑,百度文心大模型正逐步滑出市场中心。
百度很早就曾提出过与Scale Law(尺度定律)相似的观点。或许是太迷恋于此,百度在大模型研发上过于依赖传统的大规模投入和“万卡集群”等方式,在技术路线的选择上不够多元化和灵活,对新的技术方向和方法的探索不够及时。
在技术路线上,百度文心大模型与DeepSeek也背道而驰,选择的是闭源模式。李彦宏曾表示,开源模型如果要追平闭源模型,需要有更大的参数规模,这意味着推理成本更高、反应速度更慢。他还在 2024 年直言开源模型就是“智商税”,认为在同样参数规模之下,闭源模型能力比开源模型要更好。而现在全面开源的DeepSeek受到整个行业热捧,连OpenAI都在反思其闭源路线,百度大模型的发展路径恐面临两难选择。
百度的问题不止于表面,更核心的是其经营理念。百度大模型研发从一开始就较为注重商业化,以收回成本为重要目标,这导致在技术探索上不够纯粹,相比DeepSeek以推动技术生态发展为出发点,在创新的源动力上显得格局不够开阔,带来的后果就是限制一些前沿技术的探索和突破。因小失大,贻误战机。
百度是这波大模型竞赛中,为数不多赚到钱的公司。在To C领域,除了最低端、落后一代的文心大模型3.5是免费的,其他4.0系列都是需要用户充值付费才能够使用。百度副总裁曾透露,百度文库AI功能MAU已突破9000万,付费用户超4000万,位列国内第一、全球第二,仅次于微软Copilot。
免费向普通用户开放使用、且更好用的DeepSeek,无疑给百度的收费模式带来巨大的冲击。2月13日,百度终于坐不住了,宣布旗下大模型产品文心一言自4月1日0时起将全面免费开放,其新上线的深度搜索功能将于4月1日免费开放使用。亡羊补牢,犹未晚也。

*图源百度文心大模型
DeepSeek是鲶鱼,也是点燃的火种,已蔓延至整个AI产业链。但狂欢之下,冷思考不可或缺:当算力不再是瓶颈,算法创新的短板会更刺眼;当技术奇点来临,我们准备好成为执火者,还是又一次追赶者?





 京公网安备 11011402013531号
京公网安备 11011402013531号