蛇年新讯
听潮TI

文/许雯雯
编辑/张晓
DeepSeek火爆出圈以来,其引发的蝴蝶效应还在加剧。
昨天(2月13日),百度官宣,文心一言将于4月1日0时起全面免费,所有PC端和App端用户均可体验文心系列最新模型,以及超长文档处理、专业检索增强、高级AI绘画、多语种对话等功能。
此外,文心一言即将在官网、App端上线的深度搜索功能,也将从4月1日起免费开放使用。

图/百度官微
再到今天(2月14日),百度再次宣布,未来几个月,百度将陆续推出文心大模型4.5系列,并于6月30日起正式开源。
值得注意的是,同样是在这两天,从OpenAI到谷歌,也加大了大模型的开放力度,宣布了旗下大模型产品免费开放的消息。
OpenAI也有望走向开源。据悉,目前OpenAI内部正讨论公开AI模型的权重等事宜。
AI巨头步调一致走向开源开放,释放出了一个强烈信号:
大模型狂奔两年后,大模型技术在B、C两端的落地范式,涌现出了新变化,对大模型厂商提出了更高的要求——他们不仅要走在大模型技术的最前沿,也要在大模型应用爆发前夜,加速探索出大模型落地的降本路径,率先抢跑。
百度文心大模型的开源开放,正是基于上述两点。
一边,过去两年的大模型浪潮里,百度是投入力度最大、技术迭代最快、B端产业落地和C端应用探索最广、最深的AI企业之一。
截至2024年11月,文心一言的用户规模为4.3亿,文心大模型日均调用量超过15亿次,较2023年增长了超过30倍。
另一边,从模型推理到模型训练,百度已经通过技术创新实现了成本的有效降低。
而当百度、OpenAI、谷歌等AI巨头率先转向,当更大限度的技术、生态开放成为产业共识,AI技术普惠,正加速照进现实。
01
从To C到TO B,开源开放为什么成了大模型产业的必经之路?
引领此轮大模型开放开源潮的,不只百度一家。
2月6日,OpenAI宣布ChatGPT Search向所有人开放,用户无需注册,来到OpenAI官网首页就可以直接使用搜索功能。同一天里,谷歌也宣布,向所有人开放其最新的Gemini 2.0模型,包括Flash、Pro Experimental和Flash-Lite三个版本。
再到昨天,百度宣布免费开放后,OpenAI快速跟进。萨姆·奥尔特曼在社交媒体X上宣布,OpenAI新的GPT-5大模型将对ChatGPT免费用户无限量开放,不过更高智能版本的GPT-5仍需付费使用。
巨头们统一摆出开放姿态,原因不难理解。
过去两个多月里,DeepSeek投向大模型产业的石子不断泛起涟漪。DeepSeek-v3呈现出的大模型训练上的低成本、DeepSeek-R1在模型推理上的低成本,以及DeepSeek应用所呈现出来的在思维逻辑、中文、编程等方面的惊艳能力,快速助推其成为春节前后最受全球瞩目的AI公司。

而其展现出来的,以低算力成本复现先进模型的可能性、DeepSeek应用的爆发,某种程度上印证了一点:
大模型产业,当前已经进入到了需要开源开放的新阶段。
客观来看,开源和闭源,这两条不同的技术路线并非完全对立,只是在产业发展的不同时期,会呈现出不同的特征。
比如早期的模型开源更像是营销,meta旗下的Llama选择了半开源,只开源了部分参数和配置文件,但这一定程度上反而会影响模型的可验证性和可信度。
但到了今年,大模型在度过初步发展阶段后,正加速进入AI应用爆发阶段,这一阶段,开源路线显然更利于大模型技术传播,提高采用率。
正如李彦宏所说,“归根结底,最重要的是应用,而不是使用哪种大模型。不管它是开源还是闭源,更重要的是可以在应用层创造什么样的价值。”
比如在B端市场,《2024中国企业AI大模型应用现状调研报告》指出,AI大模型在企业中的渗透仍处于初期阶段,不过有55%已经部署了大模型的企业和机构认为,已经看到了大模型带来的清晰业务价值。
问题在于,对很多企业尤其是中小企业而言,大模型落地过程中,成本、技术、人才和行业方案,仍然是几个主要挑战,他们对AI大模型的投入,依然保持着积极且谨慎的矛盾态度。
IDC在《中国中小企业生成式AI及大模型应用调查》中也提到,采用大型模型和AI技术所需要的在硬件、软件、培训和数据处理等方面的成本,也是众多中小企业面临的一重挑战。
再聚焦到C端市场来看,尽管业界还未出现一款真正的超级应用,但用户对大模型应用的使用习惯正加速养成,全面开放,也是大势所趋。
也就是说,全面开源开放,才能更好地满足B端企业客户、C端用户源源不断增长的市场需求。
我们看到,当风向转变时,百度、OpenAI等大模型头部玩家,敏锐捕捉到了信号,并率先以更积极的姿态开源、开放。
以百度为例,除了在C端全面开放文心一言,在B端,百度在大模型生态上也在逐步加大开放力度。
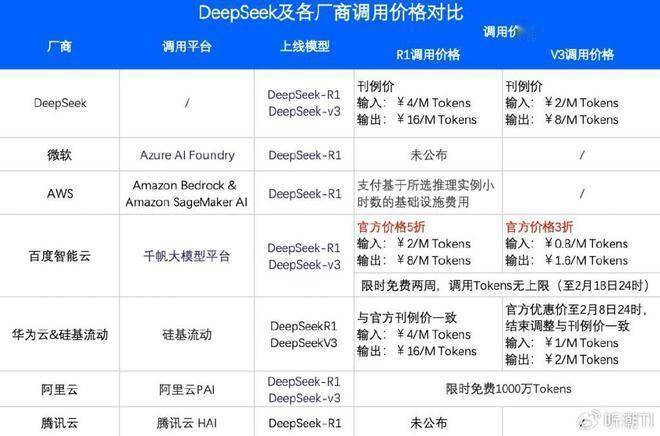
2月3日,百度智能云官宣,DeepSeek-R1及DeepSeek-V3两款模型已经上架其千帆ModelBuilder平台。
值得注意的是,百度将这两款模型的价格打了下来——客户在千帆ModelBuilder平台上调用这两款模型的价格,仅为DeepSeek-V3官方刊例价的3折、DeepSeek-R1官方刊例价的5折,同时提供限时免费服务。
另一边,过去一年里,文心旗舰大模型的降价幅度也超过了90%,并且主力模型也全面免费,最大限度降低了企业创新试错的成本。
当然,更重要的是,针对接下来即将推出的最新的文心大模型4.5系列,百度也将在6月30日起正式开源——它将以更积极的姿态面对市场,携手推动产业发展。
听潮TI也注意到,从目前释放出的信息来看,百度的开放姿态,要比OpenAI更加积极——OpenAI考虑开源的,是此前已经发布的AI模型,而百度的开源动作,则是聚焦在接下来即将发布的最新系列模型。
这意味着,面向接下来的大模型AI应用爆发潮,百度已经在提前抢跑。
02
蛇年新讯
以技术创新为基,百度跑通了大模型技术的降本路径
“回顾过去几百年,大多数创新都与降低成本有关,不仅是在人工智能领域,甚至不仅仅是在IT行业。”2月11日,在迪拜举行的World Governments Summi2025峰会上,李彦宏如此说道。
在他看来,如果能将成本降低一定数量、一定百分比,意味着生产率也会提高相同的百分比,“我认为,这几乎就是创新的本质。而今天,创新的速度比以前快得多。”
百度创始人李彦宏,图/百度官微
李彦宏此番表态背后,如今的百度,已经跑通了大模型技术的降本路径。而背后的支撑,正是技术创新。
具体来看,从大模型训练到推理,百度目前的降本效果都较为显著。
先来看训练成本。百度自研的昆仑芯芯片和万卡集群的建成,为大模型训练提供算力支持,百舸·AI异构计算平台,则可以承载大量数据的处理、超大模型的训练、高并发业务的推理,为AI任务加速,是更底层的基础设施。
其中,昆仑芯的性能优势在于,其能在更少的计算资源下运行大规模模型,进而使得大模型的推理和训练所需的计算量减少,直接降低算力成本;
大规模集群的优势则在于,其可以通过任务并行调度、弹性算力管理等方式,提高计算资源利用率,避免算力闲置,提高单任务的计算效率,降低整体算力成本。近日,百度智能云成功点亮了昆仑芯三代万卡集群,其是国内首个正式点亮的自研万卡集群,百度接下来计划将进一步扩展至3万卡。

图/百度官网
此外,在百舸平台的能力支撑下,百度也实现了对大规模集群的高效部署管理。
比如其将带宽的有效性提升到了90%以上、通过创新性散热方案有效降低了模型训练的能耗、通过不断优化并完善模型的分布式训练策略,将训练主流开源模型的集群MFU(GPU资源利用率)提升到了58%。
再来看模型的推理成本。有业内人士分析称,这一次文心一言全面开放,背后最大的原因之一,或许正是推理成本不断降低。
“百度在模型推理部署方面有比较大的优势,尤其是在飞桨深度学习框架的支持下,其中并行推理、量化推理等都是飞桨在大模型推理上的自研技术。飞桨和文心的联合优化,可以实现推理性能提升,推理成本降低。”他进一步分析道。
具体来看,百度是中国唯一拥有“芯片-框架-模型-应用”这四层AI技术全栈架构的AI企业,这意味着,百度有着中国最“厚实且灵活”的技术底座,能够实现端到端优化,不仅大幅提升了模型训练和推理的效率,还进一步降低了综合成本。
举个例子,DeepSeek-R1和DeepSeek-V3在千帆ModelBuilder平台更低的推理价格,正是是基于技术创新——百度智能云在推理引擎性能优化技术、推理服务工程架构创新,以及推理服务全链路安全保障上的深度融合,是把价格打下来的重要原因。
基于上述几点来看,百度的降本路径其实尤为清晰——基于自研技术创新,提升大模型在训练、推理过程中的资源利用率。
我们也看到,遵循这一大模型技术的降本路径,萝卜快跑,也在加速以更低成本落地。
去年5月,萝卜快跑发布了全球首个支持L4级自动驾驶的大模型,进一步提升了自动驾驶技术的安全性和泛化性,用大模型的力量让自动驾驶“更快上路”,处理复杂交通场景的能力,完全不输Waymo。
再聚焦到萝卜快跑第六代无人车,其全面应用了“百度Apollo ADFM大模型 硬件产品 安全架构”的方案,通过10重安全冗余方案、6重MRC安全策略确保车辆稳定可靠,安全水平甚至接近国产大飞机C919。
值得注意的是,这一过程中,萝卜快跑无人车的成本,已经达到或接近业界最低水平。其第六代无人车,比特斯计划在2026年量产的cybercab成本还要低,甚至是Waymo的1/7。
这某种程度上也加速了萝卜快跑的落地进程。
截至目前,萝卜快跑已经在北上广深等十多个城市,以及中国香港开启道路测试。百度此前透露,萝卜快跑累计订单已经超过800万单。李彦宏也提到,萝卜快跑的L4级自动驾驶安全测试里程累计已超过1.3亿公里,出险率仅为人类司机的1/14/。
与此同时,萝卜快跑在中国市场更复杂的城市路况下积累的测试里程,也为其开拓中东、东南亚等新兴市场埋下了伏笔。
03
应用爆发年,百度的下一步怎么走?
“我们生活在一个非常激动人心的时代。在过去,当我们谈论摩尔定律时说,每18个月性能会翻倍、成本会减半;但今天,当我们谈论大语言模型时,可以说每12个月,推理成本就可以降低90%以上。这比我们过去几十年经历的计算机革命要快得多。”2月11日的那场峰会上,李彦宏如此说道。
事实上,回顾过去一年里大模型赛道的动态,从价格战到大模型厂商的路径分化,到kimi的出圈,到AI Agent的爆发之势,再到DeepSeek的异军突起,以及其所带来的大模型开源开放潮,不难发现:
当下,大模型产业正加速迈入新的周期——技术迭代的速度越来越快了、技术创新的未知想象空间更广阔了、大模型技术降本的速度更快了、大模型应用的爆发点更近了。
这同时也意味着,从市场竞争的视角来看,大模型厂商接下来的比拼维度,也将更加丰富。
他们既要拼技术创新、拼生态赋能、也要拼开放力度和降本能力、还要拼应用。
不过,参考百度的降本路径,长远来看,最核心的比拼,依然聚焦在一点——谁能持续走在大模型技术创新的最前沿。

我们注意到,这也是百度的长期思路。
“创新是不能被计划的。你不知道创新何时何地到来,你所能做的是,营造一个有利于创新的环境。”李彦宏如此表示。
这对应的是,尽管技术进步和技术创新在不断降本,百度接下来还是会在芯片、数据中心、云基础设施上持续大力投入,来打造出更好、更智能的下一代、下下一代模型。
比如百度还在不断丰富其大模型矩阵。
目前,文心大模型矩阵中,包括了Ernie 4.0 Turbo等旗舰大模型、Ernie Speed等轻量模型,也包括基于基础模型生产的系列思考模型和场景模型,以满足不同应用的需求。
去年三季度,百度还推出了Ernie Speed Pro和Ernie Lite Pro两款增强版的轻量模型。
再到今年,从已经释放出的消息看,文心大模型4.5系列、5.0系列也将发布。
另一方面,我们也看到,百度更加积极的开源开放姿态背后,其实继续延续了此前的理念——加速推动大模型在B端业务场景中的应用进程,以及在C端应用上的探索。
最后,如李彦宏所说,“也许,在某个时刻你会找到一条捷径,比如说只需600万美元就能训练出一个模型,但在此之前,你可能已经花费了数十亿美元,用来探索哪条路才是花费这600万美元的正确途径。”
对百度而言,用持续高压强式的技术投入营造创新环境,其实是一门“笨功夫”,但好在这足够稳健、足够踏实,潜在的机会也更大。
一来,此前文心大模型的调用量就已经是国内最高,如今开源之后,其调用量预计将明显提升,进一步扩大文心大模型的使用范围;
二来,从大模型生态来看,百度过去已经基于开放姿态建立起了生态优势。
比如百度早在2016年就推出了开源的飞桨框架;百度的千帆大模型平台,也是当前业内接入模型数量最多的,支持国内外近百家主流模型。
由此可以预见,如今在更大力度推动大模型开源、开放后,在新一轮大模型竞争中,百度已经开始抢跑了。
蛇年新讯








 京公网安备 11011402013531号
京公网安备 11011402013531号