字母榜

首个被DeepSeek逼得在大模型上左右互搏的科技大厂,终于出现了。
近期,腾讯AI助手腾讯元宝,宣布接入DeepSeek-R1,允许用户在选择模型时,自由切换腾讯混元大模型和DeepSeek-R1。在一众自研大模型厂商中,腾讯也由此成为首家将DeepSeek接入自家主力产品的公司。
在此之前,一众科技大厂更多选择的是,仅在自家云服务平台上接入DeepSeek模型,供外部开发者调用,刻意避开了在C端跟自家AI助手产品打擂台的情况。
有AI大厂员工向字母榜(ID:wujicaijing)分析,对于自研大模型的科技大厂而言,是否选择接入DeepSeek,本身便是个两难选择。“尤其在自家AI助手上直接接入,这意味着间接承认当前DeepSeek-R1的表现要好于自家。”
对于上述推测,字母榜从腾讯内部知情人士处了解到,选择在腾讯元宝中接入DeepSeek,内部更多是出于能力互补的考量,且未来在大模型自研上,腾讯仍会坚持到底。
但不容忽视的客观现实是,在过去两年的大模型发展进程中,不论是自研大模型的上线时间,还是AI助手的发布节奏,腾讯都成了科技大厂中最不着急的一家。这也被外界视为腾讯在接入DeepSeek上,敢于第一个吃螃蟹的原因之一。
相比腾讯在AI上不温不火的表现,同样在大模型领域落后其他科技大厂一步的字节,则在过去一年中奋起直追。在DeepSeek爆火之前,字节旗下AI助手豆包,已成为中国月活用户数最多的AI对话应用。
但面对DeepSeek的异军突起,去年的豆包有多火爆,进入2025年的豆包或许就有多难受。近期的一场内部会上,百度智能云事业群总裁沈抖就点评道,面对DeepSeek的来势汹汹,首当其冲的AI产品,便是字节的豆包,认为后者的训练成本和投流成本都很高。
尽管沈抖的言论很快便得到火山引擎总裁谭待的隔空回应,后者称豆包1.5 Pro的预训练、推理成本均低于DeepSeek V3,且在当前的价格下仍有可观的毛利。但不能否认的是,作为两款都在年初亮相的新模型,豆包的这些产品亮点,完全被淹没在了DeepSeek所带来的“神秘东方力量”之中。
数据给出了直观有力的说明。根据近期QuestMobile给出的数据,DeepSeek日活跃用户(DAU)在1月28日首次超越豆包(约1695万),随后在2月1日突破3000万大关,成为国内DAU最高的AI 对话产品。做到这一切,DeepSeek只用了20天。
OpenAI CEO奥特曼认为,DeepSeek所展示出来的思维链、免费且大规模可用等特性,助推了人们争相体验的热情。
这也得到了字节CEO梁汝波的认同。据晚点LatePost爆料,在本周四举办的新一期All Hands全员会上,梁汝波提到DeepSeek-R1创新点之一的长链思考模式并非业界首创,在去年9月OpenAI发布长链思考模型o1后,字节也意识到了技术的重大变化,但没有及时跟进,选择将技术快速复现出来,“现在回头看,如果一开始重大问题就争先,我们有机会更早实现。”
在承认DeepSeek技术能力强劲之外,字节并未透露出可能在豆包中接入DeepSeek的迹象。
对于2025年的重点目标,梁汝波一方面要求团队加强规模效应,继续做大豆包用户群,另一方面则明确将继续追求AI技术研发和创新。
被誉为全球最强产品经理的苹果创始人乔布斯,曾说过一句话——“好产品自己会说话”。借助技术创新给用户带来全新AI体验的DeepSeek,无疑是这句话的最新注脚。
在接下来的大模型竞赛中,留给字节和其他AI厂商的最大压力,便是它们能否做出一款比DeepSeek更好的产品呢?
A
慢,在某种程度上成了腾讯AI在当下敢于率先接入DeepSeek的“优点”。
2022年11月ChatGPT发布之后,百度、阿里等国内大厂相继在2023年三四月份推出自研大模型,并配套上线自家的AI助手产品。
但腾讯比晚了一步的字节还慢了些。在字节对外亮相云雀大模型(豆包大模型前身)后的一个月,即2023年9月份,腾讯才正式上线了自研的混元大模型,官方AI助手腾讯元宝,更是直到去年5月才上线。
速度缓慢的代价之一便是,在一众科技大厂的AI助手产品中,腾讯元宝在月活用户侧排名垫底。
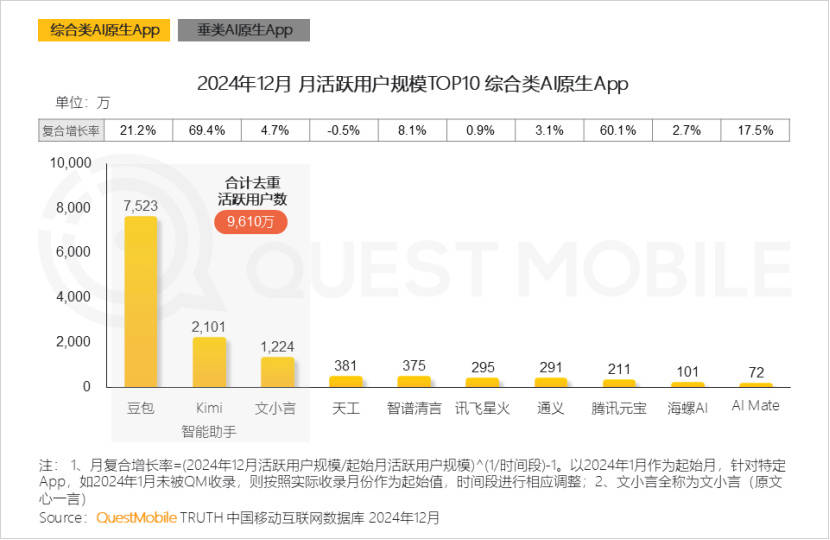
QuestMobile数据显示,截至2024年12月,AI原生APP月度活跃用户排行榜中,豆包、Kimi、文小言分别以7523万、2101万、1224万位列前三,阿里通义月活291万,腾讯元宝月活则只有211万。
但在DeepSeek掀起的风暴面前,腾讯也有点坐不住了。更重要的是,DeepSeek正在带动AI需求使用量的激增,C端AI应用有望在2025年爆发,已成为AI行业新共识之一。
从斯坦福大学计算机科学系客座教授、谷歌大脑联合创始人吴恩达,到百川智能创始人王小川、零一万物创始人李开复,他们均给出了AI应用将在2025年爆发的预测。
过去两年,为了普及AI应用,一众大模型厂商没少努力。2024年5月,DeepSeek借助大模型价格战一跃成名。当时,DeepSeek发布了DeepSeek V2开源模型,并在行业内率先降价,将推理成本降到每百万token仅1块钱,约等于GPT-4 Turbo的七十分之一。
随后,字节、腾讯、百度、阿里等科技大厂纷纷降价跟进。中国大模型价格战由此揭幕。
但降价后的大模型调用成本,对中小AI应用开发者而言,仍显得高不可攀。当时,有业内人士开始预测,等到推理成本再下降100倍后,AI应用便大概率会迎来爆发期。
更重要的是,成本之外,当时普通用户缺乏对大模型产品的信任度,后者在内容生成幻觉方面的屡屡翻车,让其可靠性大打折扣。
及至DeepSeek R1模型的出现,这些担忧都开始得到初步改变,模型调用成本尽管没有下降到100倍,但DeepSeek已经做到了比OpenAI o1的运行成本,便宜近30倍,且生成内容还保持了高可靠性。
在AI应用这列即将疾驰而来的火车上,腾讯原本有望搭着苹果超速。
去年11月,就有传闻称苹果正与腾讯讨论合作,将后者AI引入国产iPhone等硬件中。但消息飘了三个多月后,近期,据The Information,苹果在国内的首批AI合作伙伴,选定了阿里和百度,暂未有腾讯身影出现。
在错失苹果AI的合作机会之后,率先接入DeepSeek的举动,成了腾讯当下为自身争取C端用户的Plan B。
B
相比腾讯,同样比百度和阿里慢了一步的字节,经过过去一年的疯狂补课,在张一鸣继续践行“大力出奇迹”方法论的基础上,使得字节AI开始有了后来居上的对外表现。
张一鸣追赶同行的第一步,选择从定下全面自研的策略开始。据腾讯科技报道,2023年中,字节跳动在自研和收购上徘徊,并一度下场寻觅大模型标的,但在跟Minimax达成SPA(股份认购协议)的最后一刻,选择了放弃,重心转向内部自研。
自研策略定下之后,字节开始在内部组建多个小型AI产品团队,每个团队由10到15人组成,以开发新应用程序并相互竞争,来争取字节的资源支持力度。
与此同时,为了推广自家豆包应用,字节旗下巨量引擎成了首家限制其他同类产品投放的平台。从去年4月2日开始,抖音巨量广告正式要求,非字节系AI产品不能使用抖音、头条的流量池做营销推广。
在抖音的全系流量灌溉之下,加入投流之战的豆包,一度是DeepSeek爆火前用户量增速最快的AI产品,并最终拿下国内月活用户数第一的宝座。
与字节重投流策略不同,在大模型发布上抢占先机的阿里,一开始将重心放在了AI to B上。光子星球报道称,阿里内部人士曾透露,通义应用最初与大模型一同被打包进To B服务中,其作用是“秀肌肉”,即通过上架模型的各项功能,来吸引B端用户关注,以展示场景落地的潜力。
但到了去年12月底,眼看着AI应用爆发在即,阿里也不得不调整策略,开始将通义应用从阿里云分拆,并入阿里智能信息事业群。这被视为阿里加码“AI to C”的重要信号。
但随着字节、阿里纷纷重注自家AI助手,硬币的反面弊端也开始凸显——它们在接入第三方大模型上变得更加纠结和有压力。
更重要的是,一旦选择在自家核心AI应用上接入DeepSeek,还可能导致团队争抢内部资源分配权,从而引发意外的混乱。
一旦用户更愿意调用DeepSeek,公司内部的资源便势必会向其倾斜。参与大模型投资的恒业资本创始合伙人江一解释称,尤其在B端客户上,每调用一次DeepSeek,便意味着公司云服务的资源变现。“公司内部的商业化团队,与大模型训练团队,不可避免会迎来一场新的资源分配权争夺战。”
更重要的是,即便冒着自家资源混乱的风险,接入DeepSeek,究竟能否给自家产品带来预期中的流量, 还是未知数。
不同于此前云服务厂商接入DeepSeek的举措,前者是为了最终吸引开发者使用自家的算力资源,本质上是在卖铲子的路上继续跟进。
但在AI助手中接入DeepSeek,直面的则是C端用户。在当前的免费策略之下,普通用户对大模型产品尚未产生忠诚度,用户心智被体验优劣所左右。一旦出现比DeepSeek体验更好的模型,或者DeepSeek解决了自身的服务卡顿难题,用户难免会用脚投票。
C
为了迎接DeepSeek所带来的冲击,部分大模型头部玩家正在改变自身的竞争策略。
国外的OpenAI,国内的百度,近期都开始改变其在大模型上的传统竞争方式。OpenAI官宣了GPT-5的消息,百度也传出了文心5.0即将面试的计划,两家都希望通过新模型的发布,增强外界对自身在技术体验上的信任度。
同时,包括OpenAI和百度在内,两家都一改过去的收费、闭源策略:OpenAI即将发布的GPT-5,届时将向所有用户免费开放;文心一言将于4月1日起,全面免费,且未来几个月内推出的文心大模型4.5系列,也将走向开源。
DeepSeek带来的压力,并没有改变大模型头部玩家对算力需求的追逐,科技大厂依然在信仰缩放定律(Scaling Laws)的路上前进。
这也部分解释了英伟达股价从暴跌再到大涨的起伏变化。
北京时间1月27日晚,受DeepSeek低成本训练策略的影响,英伟达美股股价一夜暴跌超10%,市值蒸发超3000亿美元,总市值跌破3万亿美元。近20天后,截至美东时间2月14日收盘,英伟达股价回撤基本修复,总市值再次重回34000亿美元。

但对大模型厂商的价值重估,仍在继续。在DeepSeek引发的蝴蝶效应到来之前,融资环境就有了变难的趋势,江一也深有感受,在他看来,进入2025年,行业对大模型的投资会变得更为谨慎,“类似李开复做出放弃预训练的决定,在六小虎中几乎都不同程度存在,就看它们资金能撑到什么时候来对外宣布自己的战略调整了。”
无论是大模型六小虎,还是科技大厂,想要在大模型领域重获用户青睐,唯一的捷径便是学习DeepSeek,通过技术创新证明自己。
这方面从谷歌到豆包,都先后成了反面教材。晚于DeepSeek-R1近两天发布的豆包1.5 Pro大模型,尽管在预训练和推理成本上还要低于DeepSeek-V3,但却因为模型体验不如前者,而未能在舆论场上激起太多水花。
同样赶在DeepSeek-R1之后发布的谷歌Gemini 2.0系列大模型,尽管其Gemini 2.0 Flash-Lite版本的调用价格,比DeepSeek-V3更低,但仅靠价格优势,也依然难以俘获用户的芳心。
更糟糕的是,DeepSeek在20天内狂揽3000万月活的事实,让外界开始重新审视大模型厂商所谓的“先发优势”。
在过去两年内,大模型行业一度认为谁能够跑得更快一些,获取更多的应用,拿到更多的数据反馈,谁就能持续地保持一定程度的模型领先。
但上述数据飞轮效应被DeepSeek证伪了。近期在接受腾讯新闻采访中,金沙江创投主管合伙人朱啸虎便说道,“以前我觉得这波AI最大壁垒在数据飞轮上,但现在看来数据飞轮价值不大。因为大部分用户数据都是重复的,是低信息含量的,没有意义的。”这成了朱啸虎在过去两年中得到的最大一个教训。
一切竞争的原点,又回到了底层的技术创新和突破上。据字母榜了解,目前包括腾讯、阿里、字节、百度等在内的科技大厂,均表示将坚持大模型自研路线,并推动基础大模型的持续迭代升级。
但留给这些科技大厂的更大挑战在于,自家的新一代模型,在体验上究竟能超出DeepSeek的表现有多少?
参考资料:
《字节全员会:重提“务实的浪漫”,要做能发明新技术的科技公司》晚点LatePost
《阿里蔡崇信迪拜最新讲话:最初我为什么选择了“疯狂”的马云》蓝鲸TMT《百度云全员会上,沈抖聊了业绩、模型混战、以及DeepSeek》36氪
《苹果选阿里,为什么不是腾讯字节或DeepSeek?》财经杂志
《朱啸虎现实主义故事1周年连载:“DeepSeek快让我相信AGI了”》张小珺
《通义赶“末班车”》光子星球








 京公网安备 11011402013531号
京公网安备 11011402013531号