
文/ 果青
继昨天宣布文心一言免费使用后,今天,百度再发重磅消息:将在未来几个月中陆续推出文心大模型4.5系列,并于6月30日起正式开源。


文心大模型是百度自主研发的知识增强大语言模型,具备跨模态、跨语言的深度语义理解与生成能力。
作为国内大模型领域的重要力量之一,百度将自己能力最强的文心大模型4.5版本开源,无疑会利好国内大模型行业。
对于行业而言,“DeepSeek效应”还在发酵。关于大模型发展的开源、闭源道路之争,似乎也以开源获胜迎来“历史的终结”!

百度什么时候开始搞大模型闭源的?
事实上,百度也不是从一开始就走大模型闭源路线的。
百度曾在2021年开源了文心ERNIE的四大预训练模型,包括多粒度语言知识增强模型 ERNIE-Gram、长文本理解模型 ERNIE-Doc、融合场景图知识的跨模态理解模型 ERNIE-ViL、语言与视觉一体的模型 ERNIE-UNIMO等。
但是到2023年3月,百度推出文心大模型3.0,并推出了基于该模型的生成式AI产品“文心一言”。文心一言是国内大厂中最早推出的类ChatGPT产品,百度一时风光无两。
也正是这种“领先”的感觉,为百度走大模型闭源路线埋下了种子。
2023年5月百度乘胜追击发布文心大模型3.5,同年10月又发布了文心大模型4.0。

与此同时,基于文心大模型的文心一言,也在2023年11月1日开始向用户收费:文心一言专业版成为中国首个采用会员模式面向C端收费的大模型产品,专业版定价达到每月59.9元,连续包月优惠价每月49.9元。

免费用户只要使用文心大模型3.5,付费成为VIP才能使用更高版本的大模型。
就算是收费,文心一言用户也增长迅速,2023年12月,百度宣布文心一言用户规模突破1亿。
也是在2024年初,行业内关于大模型开源和闭源的路线选择成为大模型领域争论的热点。
2024年4月11日,媒体报道李彦宏的内部讲话首次谈及文心大模型为什么不开源,并列举了闭源的诸多优势。
李彦宏当时透露,一年前文心大模型刚刚发布的时候,百度内部曾有过非常激烈的讨论,最后大家决定不开源。
“为什么不开源?当时的判断是,市场上一定会有开源的模型,而且是不止一家会开源。在这种情况下,多百度一家开源不多,少百度一家开源也不少。”李彦宏说。
“今天不管是在中国也好、在美国也好,最强的基础模型都是闭源的,而各种各样的小模型、最好的小模型,都是通过大模型蒸馏来的。通过大模型降维做出来的模型就是更好的,这样也会导致闭源在成本上、在效率上也会有优势。” 李彦宏表示。
李彦宏认为,闭源模型在能力上会持续地领先,而不是一时领先,大模型开源意义不大,闭源才能走通商业模式,闭源是能够赚到钱的,能够赚到钱才能聚集算力、聚集人才。
当时,不仅百度走闭源路线,在美国,大模型最强玩家Open AI在发布GPT-2之后,也转向闭源,甚至在2024年被马斯克告上法庭嘲讽要求改名为Close AI。

DeepSeek颠覆闭源大模型领先性
用户用脚投票
但是,一切在2025年初发生了变化。DeepSeek以开源大模型之姿横空出世,给闭源玩家们带来灵魂震撼。
OpenAI的CEO萨姆·奥特曼(Sam Altman)承认,DeepSeek的出现改变了过去几年OpenAI遥遥领先的情况。他表示,DeepSeek迫使OpenAI等AI巨头重新评估自己的成本、战略和研究方法。
奥特曼在最近的一场问答活动中表示:“我认为,我们站在了历史错误的一边,须要制定不同的开源策略。”
OpenAI的求变动作很快:今年2月6日宣布,向所有用户开放ChatGPT搜索功能,且无需注册。这一功能最初于2024年5月首次上线,当时仅作为ChatGPT Plus订阅用户的附加选项推出。2月13日,OpenAI宣布GPT-5将提供无限制的免费使用机会。
相信DeepSeek对百度CEO李彦宏的冲击同样不小。
2月11日,在阿联酋迪拜举办的World Governments Summit 2025峰会上,李彦宏被提问DeepSeek的出现是否在意料之中时,说“创新是不能被计划的。你不知道创新何时何地到来,你所能做的是,营造一个有利于创新的环境。”
当然,更有实打实的用户用脚投票带来的压力。
从AI产品榜的数据来看,去年12月到今年1月,不仅DeepSeek,国内其他免费AI产品豆包、Kimi、通义千问等相比文心一言都更具吸引力。

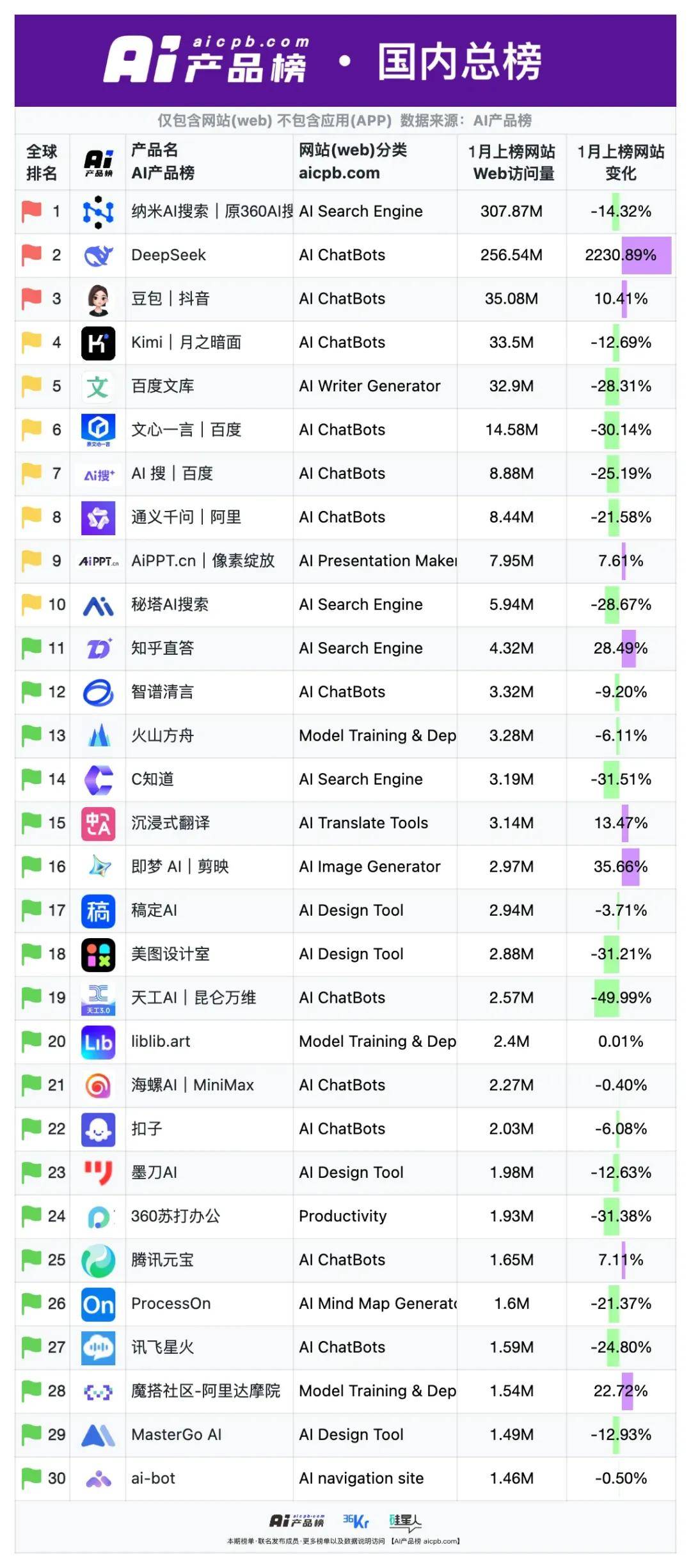
这些都迫使百度不得不调整大模型产品策略,免费和开源才是重塑竞争力的出路。
也许正如360创始人周鸿祎在12号的直播中所言:“DeepSeek不仅免费,而且开源,而且开源把自己的技术秘密都给公开了。所以它不光是能推动自己在进步,也推动友商们的进步。人类在往AGI前进路上,需要这样一个良好的一个分享。不用重复发明轮子,彼此站在成果之上,可以让人类的进步更快。”






 京公网安备 11011402013531号
京公网安备 11011402013531号