ZStack 作为有着深厚技术基因的公司,在 AI 时代来临的时候,除了给客户提供 AI 平台和 AI 解决方案,在内部也不断通过AI技术进行业务创新。SupportAI 就是在这样的背景下诞生,它是 ZStack 在客户服务领域的创新,目前已经探索并成功投入运行2年以上的时间。
SupportAI 主要能力有:
· 提炼内部数据(官网、工单、论坛、Jira、Confluence)以强化RAG能力
· 无缝对接钉钉、企业微信、微信客服等系统
· 为客户、销售、售前、技术团队提供卓越支持
· 通过智能体和 ChatRobot 确保信息流通无阻,协作高效流畅
这次 DeepSeek-R1 版本的发布,给 SupportAI 带来了新的契机,可以为它换上更加“聪明”的大脑。目前,在技术团队和业务团队的共同努力下,SupportAI 已经接入了最新的 DeepSeek-R1 模型。
本文将从2022年 SupportAI 开始设计搭建,到现在最新 DeepSeek 的接入的整个过程与大家分享,希望能通过我们的经验与分享帮助更多企业进行AI数智化转型。
一、为什么搭建 SupportAI
ZStack 自2015年以来,目前已落地超过600朵信创云,助力超过4000家企业数字化转型。在这个过程中,积累了大量的实践经验和最佳实现。在业务持续发展的同时,技术支持部门的压力也在增加,过去的客户服务系统不断接受新的挑战。
2022年起随着以 OpenAI 为代表的大模型爆发,给了技术服务团队也带来一次创新的契机。公司迅速组织技术力量,搭建了 SupportAI应用。通过 SupportAI 把官网信息、企业工单、内部论坛、Jira、Confluence 进行信息整合,将信息经过处理后,通过模型微调将数据投喂给大模型,能把AI的客服能力带给技术支持部门。经过了最初的摸索,东拼西凑,到后面搬家到自家的AI平台智塔 AIOS,并不断优化大模型的部署与评估,提升技术支持效果和问题回答的准确率,目前 SupportAI 已经是技术服务部门的核心武器。
SupportAI 在解决 ZStack 自身业务问题的同时,也是一次通过大模型应用的实践来解决企业级 AI 应用落地的实践。本文将详细描述SupportAI 的搭建思路和步骤,希望对其他有类似问题的企业有所帮助。
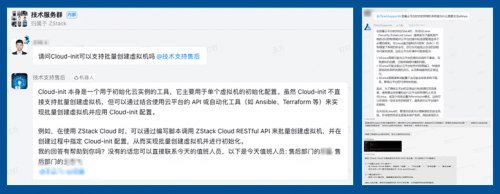
二、版本进化:SupportAI 背后的技术突破
(1)2022年 MVP 版本
2022年大模型热潮涌现之前 ZStack 已经在通过自动客服机器人,帮助技术工程师高效检索问题,并通过推荐系统链接与主题相关的文档和数据。随着 ChatGPT 和国内多个模型的发布,技术团队开始了基于大模型的方案,开始测评了包括海外模型在内的多个模型,最终选定 Qwen2 作为第一版 SupportAI 的模型底座,也是因为在实际使用中评估 Qwen 对中文语义有更好的理解和处理效果。
中间层部署了 FastGPT 来编排工作流、加载知识库文档,底层通过Qwen 来提供问答能力 ,这也是最初的架构方式。MVP 版本运行起来对技术工程师的效率提升有限,MVP 版本更多的是跑通了闭环流程、验证了技术可行性,有一定概率会回复不相关的内容、低质量的信息。
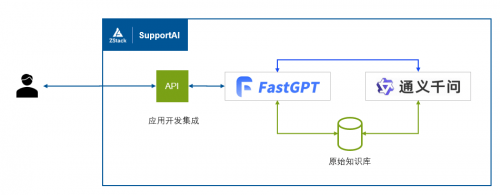
最初版本的架构图
(2) 2024年基于智塔的版本
2024年 ZStack智塔发布上线,能够非常便捷地调度资源并实现对模型的加载、评测、精调、部署推理服务等功能,经过内部的研究,决定将 SupportAI 重新通过智塔为AI基座进行搭建。
在研发人员和技术服务部的业务人员的共同努力和有了MVP版本的经验的加持下,一周内就完成了服务的迁移,数据的微调等步骤,快速完成迁移上线,投入运行。上线至今也在不断地优化和完善,得益于AIOS的模型管理和高可用的能力,在应用升级完善的同时,应用也始终保持运行。
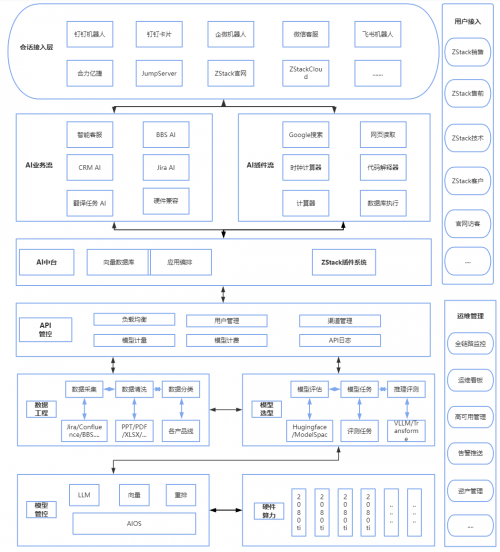
整体架构图
智塔提供模型管控、模型选型、数据工程、硬件算力、运维管理、API管控等模块,在使用智塔之前这些都需要人工开发维护,SupportAI 采用智塔之后可以解放这部分人力用于提升回答质量和准确性以及其业务应用构建。
在智塔AIOS 平台中内置了 FastGPT 和 Dify 等应用组件,这些组件均提供 Web 页面进行工作流编排、知识库上传、管理发布方式、切换支持的模型等共鞥你,这也让 SupportAI 开发维护更加方便。
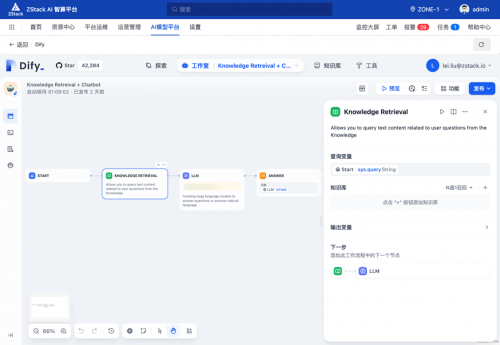
三、精准回答的实践路径
刚才提到 MVP 版本客服机器人回复质量一般,很大原因是原始数据质量不高。这时 ZStack 技术工程师在清洗数据、问题精细化分类等方面进行实践来提升知识库质量和问答回复效果。
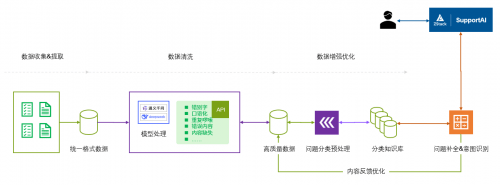
SupportAI 数据清洗&增强优化流程图
(1)通过数据清洗提升数据库质量
· 数据收集:来源比较多,内部文档有多种格式并且分散在多个平台,包括 PDF、Word 等本地文档,还有钉钉文档、在线Conflunce、内部客服 BBS 系统、工单系统、研发知识库和Jira、官网等平台,本地文档通过格式转换工具转成结构化数据,部分本地文档可转成线上文档,线上文档通过自行开发的脚本来转换数据,最终统一了原数据的格式和读写接口。
· 数据清洗:通过自行编写的脚本对数据进行清洗,包括错别字修改、口语化内容、啰嗦重复内容、主题不相关内容等等,最终输出高质量的知识库文档。
· 文档嵌入选择:直接拆分方式是直接按照 Token 拆分 Chunk,好处是不会损失细节,但缺点就是检索精度不太行;QA 提取方式能够让大模型从文档中提取出问题,好处就是能提高搜索精度,但大模型会损失细节。实测最佳实践是两者结合使用。
(2)通过问题分类进一步提升回答质量
经过以上处理,可以获得高质量的知识库,问答效果明显提升。因为用户提出的问题覆盖面很广,包括公司介绍信息、企业私有云建设方案、CPU 负载过高检测处理办法、ZStack Cloud 平台功能细节、如何对接项目需求等等。ZStack 技术工程师对知识库文档提前标注分类,这一步可以由大模型来完成。用户提出的问题也需要进行问题补全,比如提问“ ZStack 怎么样”,相对宽泛的问题可以根据用户沟通上下文(如果有)来补充更完整的信息,有了更完整的 prompt 再根据问题分类去不同的分类知识库中检索生成。
比如之前已经问了技术问题,可以将这个背景补充到 prompt 中形成“我是技术人员,之前已经问过了 CPU 负载过高检测处理办法,现在需要了解下‘ ZStack 怎么样’”,这样大模型在生成时会侧重于产品和技术细节来回答用户。同样,如果上下文是投资人相关问题则侧重于投资层面ZStack表现,如果是企业用户的问答侧重于提供 ZStack企业解决方案和成功案例。
这时候就非常急迫有一个平台能够帮助管理多个模型、进行模型评测对比,验证整体服务效果。MVP 版本是搭建在ZStack内部服务器中,人工统一管理这些服务器并更新部署大模型,这种方案在当时是能满足需求,不过并不方便后续的扩展,这也是后续切换到 ZStack智塔平台很重要的原因之一。
(3)保障生成内容安全与准确
安全性和准确性至关重要,大模型与生俱来的幻觉会导致生成的内容与主题无关、不准确甚至错误,智能客服系统在面向外部用户提供错误问答、有害信息时的影响就会很严重,对于企业应用来说是不得不考虑的。安全性和准确性至关重要,多种因素都会影响安全性和准确性,包括内部文档质量不高或者本身就有错误信息、用户输入信息不确定、当前算力不足导致生成信息中断等等。
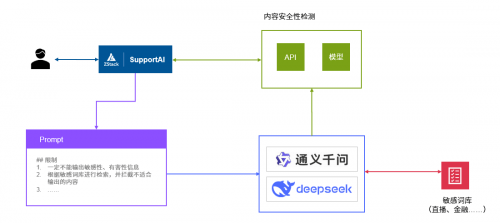
生成内容安全&准确性检测步骤
ZStack 在 SupportAI 应用中,加入了以下安全策略,来保障生成内容的安全性和准确性:
· 通过 prompt 进行限制:对 prompt 进行优化,明确限制一定不能输出敏感性信息,同时也提供了敏感词库/关键词库来让大模型去检测生成的内容是否安全。
· 通过安全内容检测并进行过滤:SupportAI 借助 AIOS 的能力,在平台内部微调一个模型推理服务担任安全检测的职能。另外,SupportAI 还与成熟的第三方安全公司进行合作,通过 API接入的方式加入到智能客服系统,进一步完善安全内容检测能力。
· 生成内容后由客服经理转发用户:在实践过程中,我们发现生成内容质量提升,是需要一个过程的。因此,智能客服系统上线初期,先在内部进行运行,由内部员工客服经理将大模型经过知识库 RAG 处理过的信息手动转发给用户,并在这个过程中进行人工审核。目前 SupportAI 运行已经基本稳定,正在逐步灰度到外部用户。
四、DeepSeek-R1来了
从上文中我们可以知道,SupportAI急缺一款有推理能力的大模型,不论是对客户意图的分析,还是最终结果回答问题的准确率,都是需要很强的推理能力。现在DeepSeek-R1来了,它有着目前行业领先的推理能力,将DeepSeek-R1应用到智能客服场景的应用是一次很有挑战的的尝试。因此,技术团队第一时间就对DeepSeek-R1模型进行了研究,并将其上架到AIOS平台的模型仓库中。SupportAI团队先在ZStack内部私有环境中进行了对DeepSeek的版本评测和选型,涉及到多个版本的模型。由于SupportAI已经将原始的物理服务器部署模型方式切换到了基于ZStack智塔平台来管理模型、部署服务,整个模型测评和替换的过程非常的丝滑。
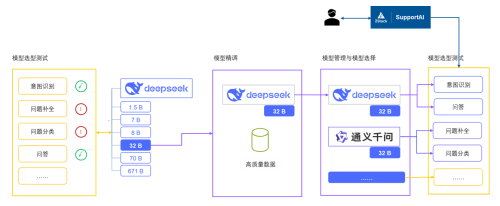
(1) 模型测试选型
先对 DeepSeek 主要版本进行了版本部署和测试,DeepSeek 有思维链更适合问题生成环节,相反因为思考过程的时间消耗会导致响应时间拉长,这样就不适合问题补全场景了。智塔平台提供模型能力评测和服务性能评测,在这里我们要评估 DeepSeek 模型能力,选择已经启动的推理服务、测评的数据集并配置采样数量,底层实例配置按需填写资源信息即可。
(2) 模型微调
在选择了性价比兼顾的 DeepSeek 版本之后(对于一般企业知识问答应用来说推荐 DeepSeek 32B 版本),在基础模型之上加载已有的数据集对模型进行精调为行业大模型,让模型更容易理解场景化专业化的知识。模型精调的过程需要涉及算力资源调配、数据集加载等环节,通过 ZStack智塔平台可以非常方便的使用 Web 界面完成模型评测、模型微调等复杂过程,企业使用者不再需要重点关注底层资源调配、中间环境安装等非业务环节。
(3)模型管理与模型选择
精调完成的模型效果如何还是如同“盲盒”,需要对精调后的模型进行评估验证。这时就非常急迫地需要一个模型管理平台,包括正在运行推理服务的模型、正在多版本测试对比的模型、正在进行精调的模型,过几周说不准有哪些亮眼新模型发布后也需要做验证,通过ZStack智塔平台能够把这些模型管理起来。智塔平台模型仓库模块提供系统内置模型,用户还可以自行导入本地模型、通过 Hugging Face、魔搭社区等平台导入在线模型。
(4)模型使用
能够发挥模型最大价值的场景各不相同,Qwen 适合问题补全、DeepSeek 适合问题生成,为了发挥各自优势选择多模型组合的使用方案。前端问答应用和后端模型进行解耦,采用最新评测验证的模型只需更改 API,或者通过负载均衡实现自动切换。模型微调完成后通过智塔AIOS平台部署推理服务,选择模型、推理模板、选择通过容器部署还是云主机部署并填写对应资源数量,等待任务运行起来,就可以通过 API 或 Web 界面方式与大模型进行交互了。
五、企业级AI应用落地启示
(1)多模型管理势在必行,推荐智塔
ZStack智塔是新一代AI基础设施操作系统,定位于帮助企业加速AI应用落地,通过算力层、模型层、运营层三大方向重构 AI 基础设施,支持从传统云平台平滑升级至智算云平台。平台兼容英伟达、海光 DCU 等多品牌 GPU,支持上万种开源模型微调,提供数据隐私安全管理与多租户资源隔离能力。凭借低建设成本、动态资源调配和全生命周期服务等优势,已在国产GPU厂商、高校、传媒等领域实现规模化应用。2月2日ZStack智塔支持 DeepSeek V3/R1/ Janus Pro 三种模型,并基于海光、昇腾、英伟达、英特尔多种 CPU/GPU 可私有化部署。

回顾 SupportAI 的搭建和演变历程,最开始基于内部通用服务器和Qwen 提供知识库问答能力,随着不同场景下需要不同的模型,推理服务正在使用以及测试/评估/选型中的模型也越来越多,非常有必要通过一个平台便捷的管理模型、屏蔽底层资源调度细节、提供模型和资源运行监控数据等,这是企业级AI应用落地方案的基座。
(2)实现4个 Ready,迎接AI应用落地
很多企业都有大量的官网等公开资料、内部知识库等资料,这些数据沉寂已久,DeepSeek 等大模型非常适合发挥数据价值。企业级 AI应用将会更深度的融入到现有应用中,企业需要进行数智化转型,需要做到4个 Ready:人员团队 Ready、资源 Ready、数据 Ready、能力 Ready。
企业应该关注的是如何通过这类应用帮助提升效率、提升客户咨询问答满意度、扩展业务影响力,不需要关注在底层基础设施上如何实现,交给专业的团队来实现即可。
企业需要灵活、便捷部署应用的平台,能够基于底层异构资源非常便捷地部署模型并提供服务。上层应用可以通过多种方式构建,可以通过魔搭社区、Hugging Face 来获取最新模型并由智塔AIOS平台统一管理并部署推理服务,底层服务器可以选用企业内部已有服务器资源或者新购。

企业需要迎接AI浪潮,不能再错过这次机会,在企业级AI应用落地过程中会有很多挑战,ZStack 作为 DeepSeek 私有化部署专家、企业级 AI 基础设施专家会为你提供更多服务。









 京公网安备 11011402013531号
京公网安备 11011402013531号