
作 者丨孙永乐
编 辑丨陈思颖
消息方面,据“豆包大模型团队”微信公众号, 字节跳动豆包大模型Foundation团队近期提出UltraMem,该架构有效解决了MoE推理时高额的访存问题,推理速度较MoE架构提升2—6倍,推理成本最高可降低83%。
据了解,随着模型规模的扩大,推理成本和访存效率已成为限制大模型规模应用的关键瓶颈。在Transformer架构下,模型的性能与其参数数量和计算复杂度呈对数关系。随着LLM规模不断增大,推理成本会急剧增加,速度变慢。
为此,字节跳动豆包大模型Foundation团队提出UltraMem,一种同样将计算和参数解耦的稀疏模型架构,在保证模型效果的前提下解决了推理的访存问题。
目前,这项创新成果已被机器学习和AI领域的顶级会议ICLR 2025接收,为解决大模型推理效率和扩展能力问题提供了全新思路。

公开资料显示,字节跳动豆包大模型团队成立于2023年,致力于开发先进的AI大模型技术,成为世界一流研究团队,为科技和社会发展作出贡献。团队研究方向涵盖深度学习、强化学习、LLM、语音、视觉、AInfra等,在中国、新加坡、美国等地设有实验室和岗位。
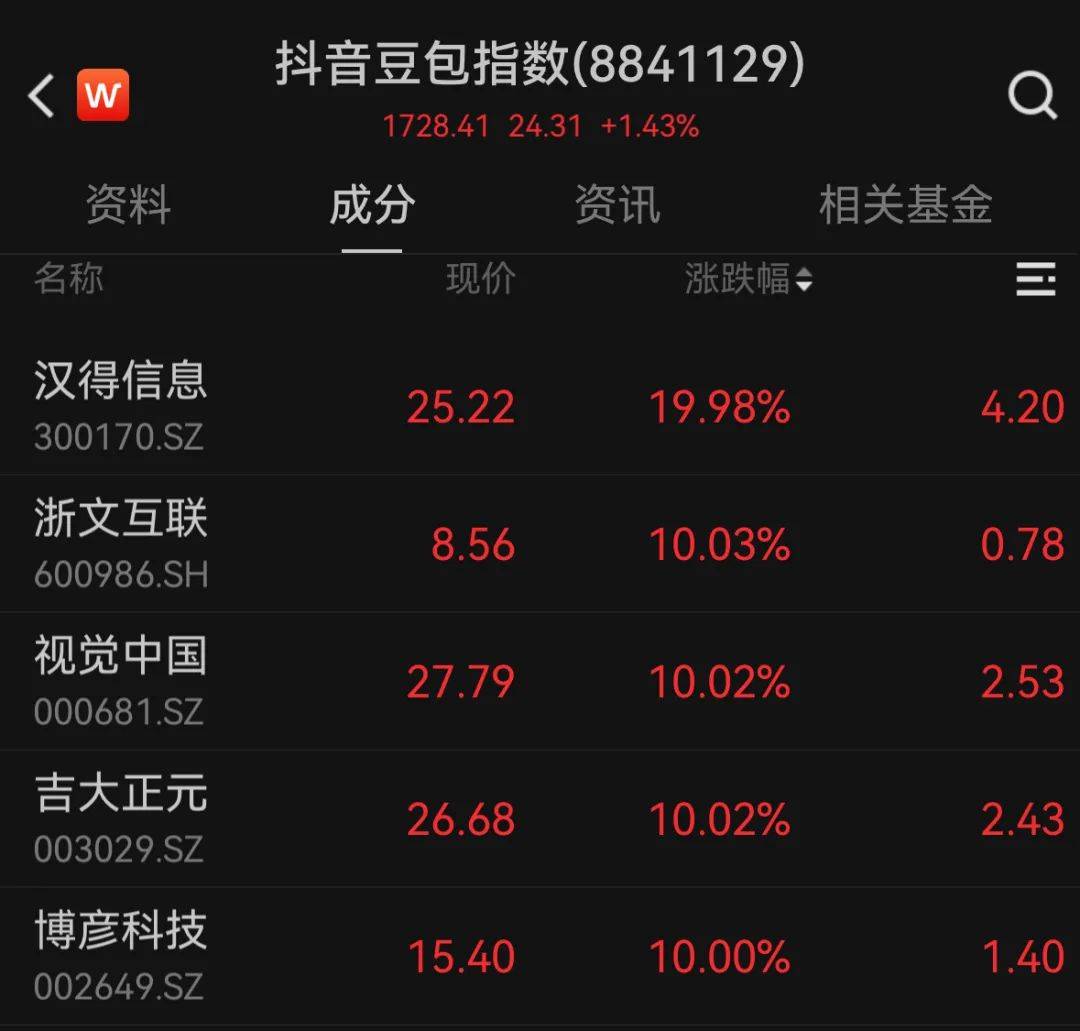
今日,一则消息再度引爆抖音豆包概念,南财快讯带你一图速览↓↓↓

(声明:文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。)
SFC
本期编辑 黎雨桐









 京公网安备 11011402013531号
京公网安备 11011402013531号