文 | 阑夕
DeepSeek火出圈的这十几天,其实也是噪音最多的一段时间,说实话大部分的讨论成品都有种加班硬赶KPI的味道,是人是鬼都在掰扯,有留存价值的屈指可数,倒是有两期播客让我听后受益匪浅,非常推荐。
一个是张小珺请来加州伯克利大学AI实验室博士潘家怡对DeepSeek论文的逐句讲解,接近3个小时的高密度输出,非常能杀脑细胞,但杀完之后分泌出来的内啡肽,也含量爆炸。
另一个是Ben Thompson关于DeepSeek的3集播客合集,加起来1个多小时,这哥们是News Letter的开创者,也是全球最懂技术的分析师之一,常年旅居台北,对中国/亚洲的近距离洞察比美国同行要高很多。
先说张小珺的那期,嘉宾潘家怡当时是在读完DeepSeek的论文之后,最快开发出了小规模复现R1-Zero模型的项目,在GitHub上已经接近1万Stars。
这种薪火相传式的知识接力,其实是技术领域理想主义的投射,就像月之暗面的研究员Flood Sung也说,Kimi的推理模型k1.5最初就是基于OpenAI放出来的两个视频得到了启发,更早一点,当Google发布「Attention Is All You Need」之后,OpenAI立刻就意识到了Transformer的未来,智慧的流动性才是一切进步的先决条件。
所以大家才对Anthropic创始人Dario Amodei那番「科学没有国界,但科学家有祖国」的封锁表态大为失望,他在否定竞争的同时,也在挑战基本常识。
继续回到播客内容上,我还是试着划些重点出来给你们看,推荐有时间的还是听完原版:
- OpenAI o1在惊艳登场的同时做了非常深厚的隐藏工作,不希望被其他厂商破解原理,但从局势上有点像是在给行业提了一个谜语,赌的是在座各位没那么快解出来,DeepSeek-R1是第一个找出答案的,而且找答案的过程相当漂亮;
- 开源能够比闭源提供更多的确定性,这对人力的增长和成果的产出都是很有帮助的,R1相当于把整个技术路线都明示了出来,所以它在激发科研投入上的的贡献要胜过藏招的o1;
- 尽管AI产业的烧钱规模越来越大,但事实上就是我们已经有接近2年时间没有获得下一代模型了,主流模型还在对齐GPT-4,这在一个主张「日新月异」的市场里是很罕见的,即便不去追究Scaling Laws有没有撞墙,OpenAI o1本身也是一次新的技术线尝试,用语言模型的方式让AI学会思考;
- o1在基准测试里重新实现了智力水平的线形提升,这很牛逼,发的技术报告里没有披露太多细节,但关键的地方都讲到了,比如强化学习的价值,预训练和监督微调相当于是给模型提供正确答案用来模仿,久而久之模型就学会依葫芦画瓢了,但强化学习是让模型自己去完成任务,你只告诉它结果是对还是不对,如果对就多这么干,如果不对就少这么干;
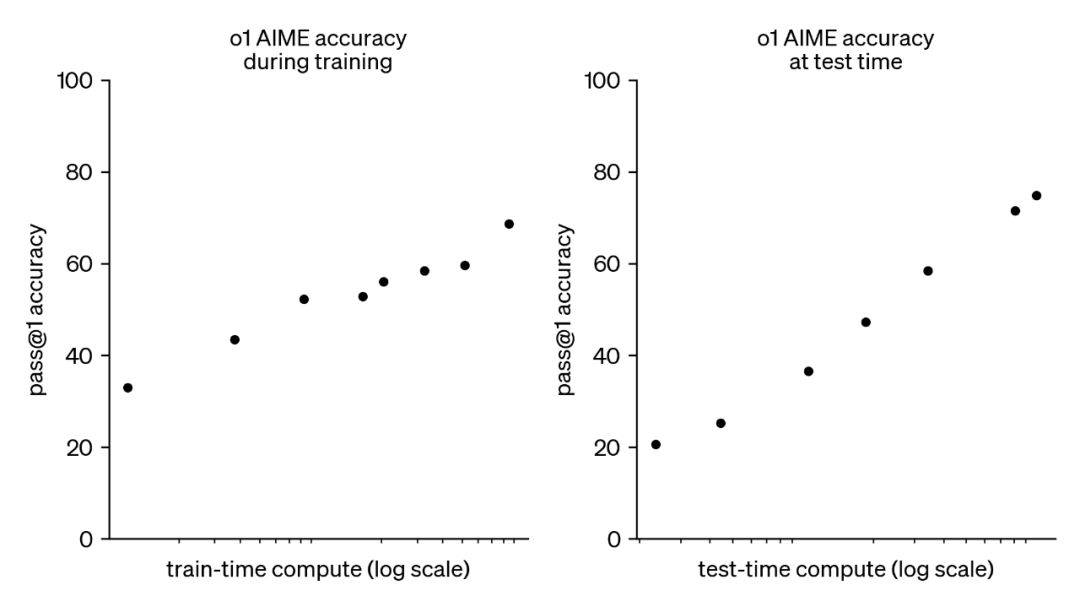
- OpenAI发现强化学习可以让模型产生接近人类思考的效果,也就是CoT(思维链),它会在解题步骤出错时回到上一步尝试想些新办法,这些都不是人类研究员教出来的,而是模型自己为了完成任务被逼,哦不,是涌现出来的能力,后来当DeepSeek-R1也复现出了类似的「顿悟时刻」,o1的核心堡垒也就被实锤攻破了;
- 推理模型本质上是一个经济计算的产物,如果强行堆砌算力,可能到了GPT-6仍然可以硬怼出类似o1的效果,但那就不是大力出奇迹了,而是奇迹出奇迹,可以但没必要,模型能力可以理解为训练算力x推理算力,前者已经太贵了,后者还很便宜,但乘数效应是差不多相等的,所以现在行业都开始扎走搞性价比更优的推理路线;
- 上个月末o3-mini的发布和DeepSeek-R1可能关系不大,但o3-mini的定价降到了o1-mini的1/3,肯定是受到了很大的影响,OpenAI内部认为ChatGPT的商业模式是有护城河的,但卖API没有,可替代性太强了,国内最近也有关于ChatBot是不是一门好生意的争议,甚至DeepSeek很明显都没有太想明白怎么承接这波泼天流量,做消费级市场和做前沿研究可能是有天然冲突的;
- 在技术专家看来,DeepSeek-R1-Zero要比R1更加漂亮,因为人工干预的成分更低,纯粹是模型自己摸索出了在推理几千步里寻找到最优解的流程,对先验知识的依赖没那么高,但因为没有做对齐处理,R1-Zero基本上没法交付给用户使用,比如它会各种语言夹杂着输出,所以实际上DeepSeek在大众市场得到认同的R1,还是用了蒸馏、微调甚至预先植入思维链这些旧手段;
- 这里涉及到一个能力和表现并不同步的问题,能力最好的模型未必是表现最好的,反之亦然,R1表现出色很大程度上还是因为人工使劲的方向到位,在训练语料上R1没有独占的,大家的语料库里都会包含古典诗词那些,不存在R1懂得更多,真正的原因可能在于数据标注这块,据说DeepSeek找了北大中文系的学生来做标注,这会显著提高文采表达的奖励函数,一般行业里不会太喜欢用文科生,包括梁文锋自己有时也会做标注的说法不只是说明他的热情,而是标注工程早就到了需要专业做题家去辅导AI的地步,OpenAI也是付100-200美金的时薪去请博士生为o1做标注;
- 数据、算力、算法是大模型行业的三个飞轮,这一波的主要突破来自算法,DeepSeek-R1发现了一个误区,就是传统算法里对于价值函数的重视可能是陷阱,价值函数倾向于对推理过程的每一步去做判断,由此事无巨细的把模型向正确的道路上引导,比如模型在解答1+1等于几的时候,当它产生1+1=3的幻觉了,就开始惩罚它,有点像电击疗法,不许它犯错;
- 这种算法理论上没毛病,但也非常完美主义,不是每道题目都是1+1这样简单的,尤其是在长思维链里动辄推理几千个Token序列的情况下,要对每一步都进行监督,投入产出比会变得非常低,所以DeepSeek做出了一个违背祖训的决定,不再用价值函数去满足研究时的强迫症,只对答案进行打分,让模型自己去解决怎么用正确的步骤得到答案,即便它存在1+1=3的解题思路,也不去过度纠正,它反而会在推理过程里意识到不对劲,发现这么算下去得不出正确答案,然后做出自我纠正;
- 算法是DeepSeek之于整个行业的最大创新,包括要怎么分辨模型是在模仿还是推理,我记得o1出来后有很多人声称通过提示词让通用模型也能输出思维链,但那些模型都没有推理能力,实际上就是模仿,它还是按照常规模式给出了答案,但是因为要满足用户要求,又回过头基于答案给出思路,这就是模仿,是先射箭后画靶的无意义动作,而DeepSeek在对抗模型破解奖励方面也做了很多努力,主要就是针对模型变得鸡贼的问题,它逐渐猜到怎么思考会得到奖励,却没有真的理解为什么要这么思考;
- 这几年来行业里一直在期待模型诞生涌现行为,以前会觉得知识量足够多了,模型就能自然演化出智慧,但o1之后发现推理好像才是最关键的那块跳板,DeepSeek就在论文里强调了R1-Zero有哪些行为是自主涌现而非人为命令的,像是当它意识到生成更多的Token才能思考得更加完善、并最终提高自己的性能时,它就开始主动的把思维链越变越长,这在人类世界是本能——长考当然比快棋更有策略——但让模型自个得出这样的经验,非常让人惊喜;
- DeepSeek-R1的训练成本可能在10万-100万美金之间,比起V3的600万美金更少,加上开源之后DeepSeek还演示了用R1去蒸馏其他模型的结果,以及蒸馏之后还能继续强化学习,可以说开源社区对于DeepSeek的拥戴不是没有理由的,它把通往AGI的门票从奢侈品变成了快消品,让更多的人可以进来尝试了;
- Kimi k1.5是和DeepSeek-R1同时发布的,但因为没有开源,加上国际上积累不足,所以虽然也贡献了类似的算法创新,影响力却相当有限,再就是Kimi因为受到2C业务的影响,会比较突出用短思维链实现接近长思维链的方法,所以它会奖励k1.5用更短的推理,这个初衷虽然是迎合用户——不想让人在提问后等太久——但好像有些事与愿违的回报,DeepSeek-R1的很多出圈素材都是思维链里的亮点被用户发现并传播,对于头一次接触推理模型的人来说,他们似乎并不介意模型的冗长效率;
- 数据标注是全行业都在藏的一个点,但这也只是一项过渡方案,像是R1-Zero那种自学习的路线图才是理想,目前来看OpenAI的护城河还是很深,上个月它的Web流量达到了有史以来的最高值,DeepSeek的火爆客观上会为全行业拉新,但meta会比较难受,LLaMa 3实际没有架构层的创新,也完全没有预料到DeepSeek对开源市场的冲击,meta的人才储备非常强大,但组织架构没有把这些资源转化成技术成果。
再说Ben Thompson的播客,他在很多地方交叉验证了潘家怡的判断,比如R1-Zero在RLHF里去掉了HF(人类反馈)的技术亮点,但更多的论述则是放在了地缘竞争和大厂往事,叙事的观赏性非常流畅:
- 硅谷过度重视AI安全的动机之一在于可以借此把封闭行为合理化,早在GPT-2的协议里就以避免大语言模型被利用拿去生成「欺骗性、带偏见」的内容,但「欺骗性、带偏见」远未达到人类灭绝级别的风险,这本质上是文化战争的延续,而且基于一个「仓廪实而知礼节」的假设上,即美国的科技公司在技术上拥有绝对的优势,所以我们才有资格分心去讨论AI有没有种族歧视;
- 就像OpenAI决定隐藏o1思维链时说得义正辞严——原始思维链可能存在没有对齐的现象,用户看到后可能会感觉到被冒犯,所以我们决定一刀切,就不给用户展示了——但DeepSeek-R1一举证伪了上面的迷之自信,是的,在AI行业,硅谷并没有那么稳固的领先地位,是的,暴露的思维链可以成为用户体验的一部分,让人看了之后更加信任模型的思考能力;
- Reddit的前CEO认为把DeepSeek描述为斯普特尼克时刻——苏联先于美国发射第一颗人造卫星——是一个强行赋予的政治化解读,他更确定DeepSeek位于2004年的Google时刻,在那一年,Google在招股书里向全世界展示了分布式算法是如何把计算机网络连接在一起,并实现了价格和性能的最优解,这和当时所有的科技公司都不一样,它们只是购买越来越贵的主机,并甘愿身处成本曲线最昂贵的前端;
- DeepSeek开源R1模型并透明的解释了它是怎么做到这一点的,这是一个巨大的善意,若是按照继续煽动地缘政治的路数,中国公司本来应该对自己的成果保密的,Google时刻也确实为Sun这样的专业服务器制造商划定了终点线,推动竞争移动到商品层;
- OpenAI的研究员roon认为DeepSeek为了克服H800芯片所作出的降级优化——工程师用不了英伟达的CUDA,只能选择更低端的PTX——是错误的示范,因为这意味着他们浪费在这上面的时间无法弥补,而美国的工程师可以毫无顾虑的申请H100,削弱硬件无法带来真正的创新;
- 如果2004年的Google听取了roon的建议,不去「浪费」宝贵的研究人员构建更经济性的数据中心,那么也许美国的互联网公司今天都在租用阿里巴巴的云服务器,在财富涌入的这二十年里,硅谷已经失去了优化基础设施的原动力,大厂小厂也都习惯了资本密集型的生产模式,乐于提交预算表格去换取投资,甚至把英伟达的芯片干成了抵押物,至于如何在有限的资源里尽可能多的交付价值,没人在乎;
- AI公司当然会支持杰文斯悖论,也就是更便宜的计算创造更大量的使用,但过去几年里的实际行为却是出心口不一的,因为每家公司都在表现出研究大于成本的偏好,直到DeepSeek把杰文斯悖论真正带到了大家的眼皮底下;
- 英伟达的公司变得更有价值,和英伟达的股价变得更有风险,这是可以同时存在时发展,如果DeepSeek能在高度受限的芯片上达到如此成就,那么想象一下,如果当他们获得全功率的算力资源后,技术进步会有多大,这对整个行业都是激励性的启示,但英伟达的股价建立在它是唯一供给方这个假设上,这可能会被证伪;
- 中国和美国的科技公司在AI商品的价值判断上出现了显性分歧,中国这边认为差异化在于实现更优越的成本结构,这和它在其他产业的成果是一脉相承的,美国这边相信差异化来自产品本身以及基于这种差异化创造的更高利润率,但美国需要反思通过否定创新——比如限制中国公司取得AI研究所需的芯片——来赢得竞争的心态;
- Claude在旧金山的口碑再怎么好,也很难改变它在销售API这种模式上的天然弱点,那就是太容易被替换掉了,而ChatGPT让OpenAI作为一家消费科技公司拥有更大的抗风险能力,不过从长远来看,DeepSeek会让卖AI的和用AI的都有受益,我们应该感谢这份丰厚的礼物。
嗯,差不多就是这些,希望这篇作业可以帮你们更好的理解DeepSeek出圈之后对AI行业产生的真实意义。







 京公网安备 11011402013531号
京公网安备 11011402013531号