此内容来自复旦-达观金融垂域应用大模型校企联合研究中心研究成果
近期,大型语言模型如GPT-4和LLaMa等,在自然语言处理领域各项任务中展现了惊人的实力。这些模型凭借其强大的知识存储和上下文理解能力,其优异性能已广泛渗透至金融、法律、医疗等多个专业领域。在构建这些大模型的过程中,指令微调技术扮演了核心角色,它通过利用有监督的数据集对模型进行精调,助力模型从简单的文本续写向复杂任务解答的跃迁。
然而,受制于特定领域的数据量和计算资源限制,指令微调往往需要借助参数高效的微调策略,LoRA(低秩适配器)方法应运而生,它通过为原始模型引入可分解的低参数旁路,实现了模块化改造及性能的全面提升,并具备了简便易用的“即插即用”特性。与此同时,来自不同来源的数据在多样性和质量上存在差异,而如何合理配置不同数据量的比例在先前的研究中并未得到充分探讨。这进一步加剧了LoRA适配器选择和数据选择的问题,使其成为一个亟待解决的关键挑战。因此,探索一种能够同时优化LoRA选择和数据选择策略的方法,以保持数据在语义空间中的连续性和关联性,成为了提升混合专家模型性能的重要研究方向。这要求我们不仅要关注适配器的训练过程,还要重视数据预处理和选择机制,以确保模型能够在面对复杂多变的任务时,依然能够保持高效和准确的性能表现。
为了填补现有研究的空白,我们提出了自适应语义空间学习框架(Adaptive Semantic Space Learning, ASSL),并通过金融多任务数据集训练了一个名为“银瞳” (SilverSight) 的金融多任务大语言模型,模型在推理阶段能够根据问题自适应选择最优专家进行回答,如图1所示。
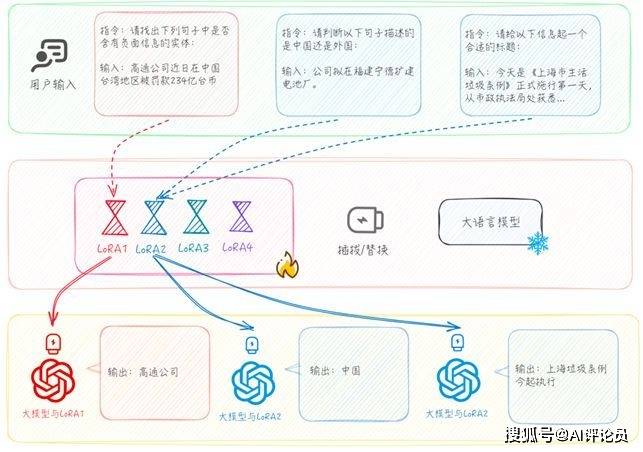
图1 “银瞳”金融多任务大模型流程示意
ASSL框架利用多任务训练数据在语义空间中的相似性进行聚类,从而摒弃了对训练数据任务类型的预定义。实验结果表明,与基于预设任务类型的分类方法相比,我们的方法具有较为显著的优势,确保了每个专家模型能够被分配到与其最相关的下游任务中。此外,通过利用语义空间的相似性,我们的方法能够聚合互补任务的多种数据,从而在相关任务上提升模型性能。
在ASSL框架下,我们在每个聚类中采用基于模型自我进化的数据重分布策略,进行自适应的数据挑选。通过两阶段的数据自适应筛选,我们确保了用于训练每个LoRA专家的少量数据具备高质量、高覆盖率以及高必要性。在原始数据质量及数量分布不均的情况下,ASSL框架通过考虑语义空间分布密度和模型自反馈机制,对每个LoRA的训练数据进行自适应筛选。这种方法使得模型能够对长尾分布中的头部相似性数据和尾部小样本数据进行更均衡的拟合,从而提高了模型在多样任务上的泛化能力和性能表现。
我们从金融领域的23个不同来源收集了22万条中文金融微调数据,并将这些数据分类为情感分析、金融问答、文本生成、金融选择题等多个任务类型。基于这些实验数据,我们得出以下主要发现:
01
通过利用语义空间中的相似性进行聚类,我们能够识别出相互促进和存在冲突的训练任务。采用多个专家模型分别针对特定领域任务进行学习,可以使得每个专家专注于其擅长的领域,实现“各司其职”的效果。
02
结合数据在语义空间中的密度分布和模型自身对训练数据的需求,我们能够有效地对数据进行语义平滑重分布。这种方法使得整个系统能够在仅使用10%的数据进行微调的情况下,达到与使用全量数据进行微调相似的效果。
03
通过对聚类内部的数据进行分布平滑处理,我们利用聚类内数据嵌入的质心作为LoRA专家的嵌入,从而实现了LoRA选择的最优化。
核心算法模型
自适应语义空间学习框架
我们提出了一种名为ASSL (自适应语义空间学习) 的框架,该框架旨在实现对LoRA专家及 其数据自适应选择的功能。框架示意如图2所示,它确保了每个专家能够发挥最佳性能,并使整个系统在多任务集合上拥有卓越的表现。本节将详细阐述框架的两个核心组 成部分,即如何通过数据在语义空间的重新分布来统一实现专家以及数据之间的自适应选择。
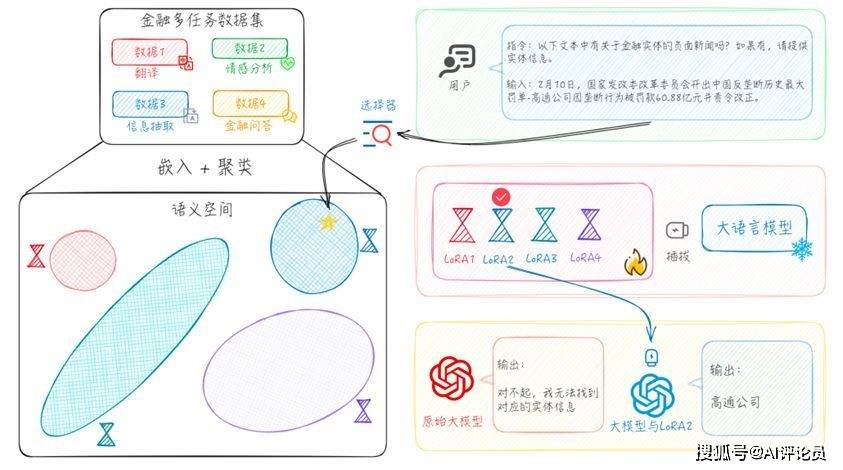
图2 自适应语义空间学习框架
1.1 LoRA专家的自适应选择
在处理LoRA专家的自适应选择时,我们的目标是优化数据划分以避免任务间的潜在冲突,并确保对于每个输入,都能匹配到最擅长处理该类问题的专家。这一目标主要分为两个方面:(1)如何更有效地训练多任务指令;(2)如何根据用户输入选择最合适的LoRA专家。
首先,使用句子编码器Emb(·)对每条指令及其输入数据的拼接Ins ⊕ Inp 进行编码,获得所有数据在同一语义空间中的嵌入向量。我们采用K-Means聚类方法将语义空间中相近的句子聚集成K 类,以此来优化任务的数据划分。聚类过程可以通过以下公式表示:
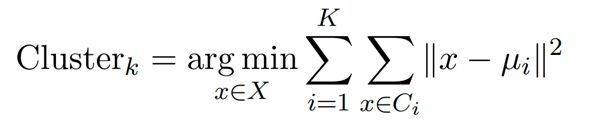
其中,X表示所有数据点的集合,Ci 是第i 个聚类中的数据点集合,而µi是第i 个聚类的质心。通过实验证明,与混合任务训练以及按预定义标签进行划分训练的方式相比,这种基于语义的聚类训练法能够显著提升系统性能。针对每个LoRA专家,我们选择其聚类的质心作为该专家的语义嵌入,每个聚类的质心µi 是聚类中所有点语义嵌入的平均位置,计算公式如下: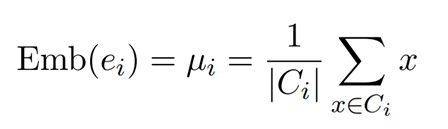
其中,Ci 是第i 个聚类中的数据点集合,而|Ci| 表示集合Ci 中元素的数量。µi 代表聚类i中所有点的均值,即该聚类的质心。每当有用户输入时,系统通过以下公式寻找与用户输入语义嵌入最接近的专家进行响应: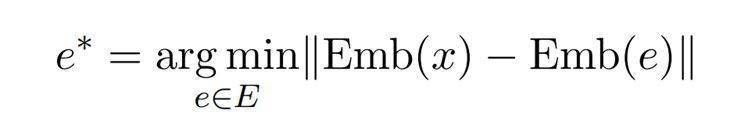
这里,Emb(x) 是用户输入的嵌入向量,Emb(e) 是专家的语义嵌入向量,而e ∗ 则是被选中的专家。通过此种匹配方式,系统能够在语义空间中找到与训练任务最匹配的专家。
1.2 多源异构数据的自适应选择
在本章中,我们讨论如何对多任务有监督数据进行聚类,以隔离相互冲突的任务并聚集相互增强的任务。虽然这种方法有效地解决了任务间的冲突,但它也引入了新的挑战,如数据配比失衡和质量不一,特别是长尾数据分布的问题。为了解决这些问题,我们为每个聚类设计了一个两阶段的数据重分布操作,目的是在保持少量数据集上进行有效微调的同时,达到比拟全数据集微调的效果,具体流程见图3。
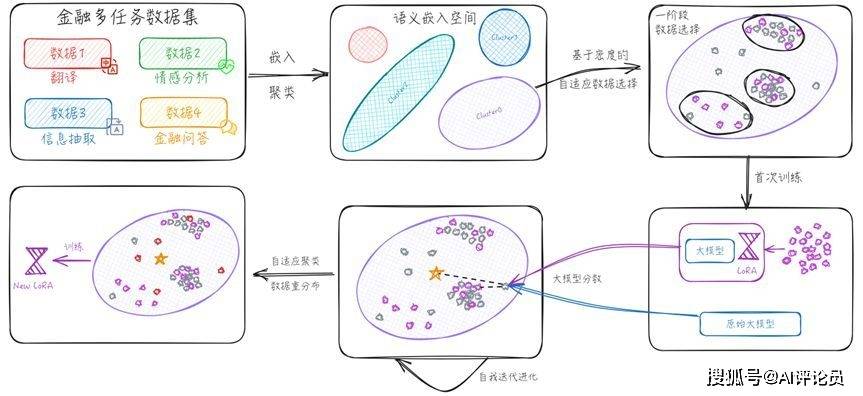
图3 自适应语义空间数据重分布流程
在第一阶段,针对聚类簇中数据失衡的问题,我们基于DBSCAN算法设计了一种自适应调整的A-DBSCAN算法,对每个聚类中的数据进行嵌套聚类。该算法可以根据数据密度在不同区域中动态调整连通数量。具体实现步骤如下:首先,算法通过K-最近邻算法(K-Nearest Neighbor, KNN) (Peterson,2009)距离计算框架来评估数据点在语义空间中的局部密度。每个数据点的局部密度为其至最近的k个邻居的平均距离的倒数,其数学表达式为:
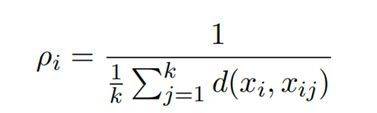
其中,d(xi, xij )表示数据点xi与其第j个最近邻居xij之间的距离。随后,算法根据计算得到的局部密度值将数据点进行排序,形成一个优先队列,优先处理局部密度较高的数据点。在每次迭代中,选取队列中局部密度最高的点作为起始点,围绕此点进行簇的生成。在自适应过程中,算法利用队列中所有数据点KNN距离的中位数定义邻域半径ε。同时,启发式地将邻域节点数MinPts的初始值设置为:

其中,ρmax表示全局最大局部密度,即初始优先队列中第一个数据点的局部密度。在每个簇形成后,MinPts根据以下公式进行更新,以适应当前的局部密度环境: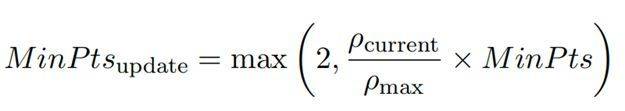 此处,ρcurrent表示当前优先队列中第一个点的局部密度。这种动态调整策略使得算法能够更灵活地适应不同密度的数据分布,提高聚类的准确性和效率。同时,这一策略允许我们在每个子簇中平均选取数据量,同时过滤掉不连通的噪声点,有效地对高密度数据进行下采样,对低密度数据进行上采样,从而避免过拟合和欠拟合。在第二阶段,我们利用第一阶段筛选出的少量数据对模型进行初步的LoRA微调。参考先前的研究,大语言模型在微调阶段主要学习新的语言风格分布,而难以获得新的领域知识。因此,我们考虑数据与大模型自身知识的冲突情况,根据初步训练前后大模型对未选数据的得分差异,设计了两种得分机制来评估每条数据对当前模型的价值。差异得分和比例得分分别定义为:
此处,ρcurrent表示当前优先队列中第一个点的局部密度。这种动态调整策略使得算法能够更灵活地适应不同密度的数据分布,提高聚类的准确性和效率。同时,这一策略允许我们在每个子簇中平均选取数据量,同时过滤掉不连通的噪声点,有效地对高密度数据进行下采样,对低密度数据进行上采样,从而避免过拟合和欠拟合。在第二阶段,我们利用第一阶段筛选出的少量数据对模型进行初步的LoRA微调。参考先前的研究,大语言模型在微调阶段主要学习新的语言风格分布,而难以获得新的领域知识。因此,我们考虑数据与大模型自身知识的冲突情况,根据初步训练前后大模型对未选数据的得分差异,设计了两种得分机制来评估每条数据对当前模型的价值。差异得分和比例得分分别定义为: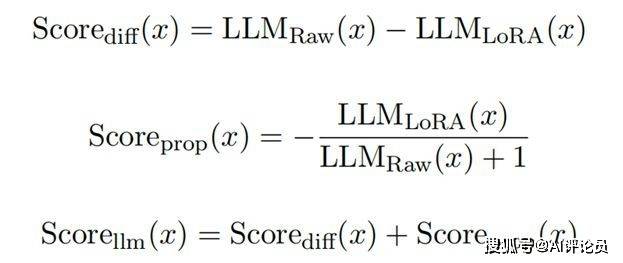 其中,ScoreRaw(x)以及ScoreLoRA(x)通过Rouge方法计算。此外,为了确保 新选数据的质量和对整个聚类簇的覆盖度,受启发于MMR公式,我们设计了训练数据的效用函数:
其中,ScoreRaw(x)以及ScoreLoRA(x)通过Rouge方法计算。此外,为了确保 新选数据的质量和对整个聚类簇的覆盖度,受启发于MMR公式,我们设计了训练数据的效用函数: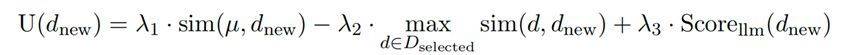 其中,µ 代表聚类中心点,dnew 代表待加入的数据点,Dselected 表示已经被选中的数据点集合,λ1,λ2 和λ3 是三个可设定的权重参数,用于调整相似度、多样性和模型得分对最终数据点效用值的贡献。经过两阶段的数据筛选,每个聚类中的数据将在语义空间中进行重分布,从而促使模型学习那些罕见但有益的数据,避免在常见数据集上产生过拟合现象。
其中,µ 代表聚类中心点,dnew 代表待加入的数据点,Dselected 表示已经被选中的数据点集合,λ1,λ2 和λ3 是三个可设定的权重参数,用于调整相似度、多样性和模型得分对最终数据点效用值的贡献。经过两阶段的数据筛选,每个聚类中的数据将在语义空间中进行重分布,从而促使模型学习那些罕见但有益的数据,避免在常见数据集上产生过拟合现象。
实验
实验数据
我们从金融领域23个不同的来源收集了约22万条中文金融微调数据,并将这些数据分类为情感分析、金融问答、金融问答等7类任务,具体介绍如下表。同时,我们使用CFLEB和Fineval 评测集作为评估工具,旨在评估大语言模型在金融领域的知识储备、指令跟随及任务执行能力。
CFLEB评测集是利用公开的研报及新闻等项目构建的高质量、高实用性的评测基准,包含了六种自然语言处理任务,衡量金融领域模型在情感分析、问答、摘要生成、信息抽取、语义匹配等方面理解与生成的全面能力。
Fineval评测集是针对金融领域知识评估而设计的一套全面数据集,包含了共4661道选择题。这些题目覆盖了34个不同的学术领域,如金融学、保险学、宏观经济学和税法等,主要分为四大类别:金融、经济、会计以及资格证考试,以全面测试大型模型对金融领域通用知识的掌握程度,评估其在金融专业领域内的先进知识与实际应用能力。
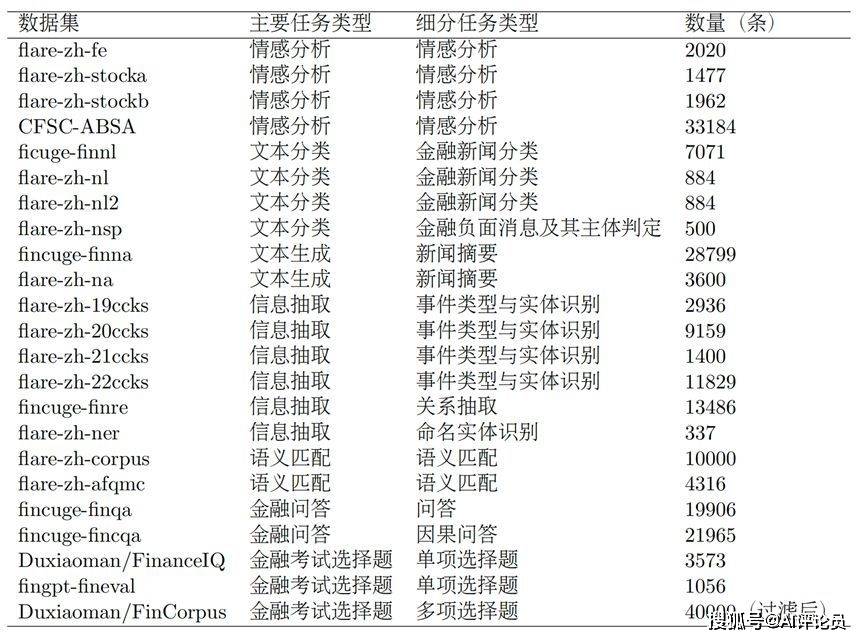
表1 微调数据集统计
实验结果
DATAGRAND表2与表3展示了我们对“银瞳”大型模型进行的评测实验结果。在针对CFLEB数据集的评测中,我们注意到FinFE、FinQA、FinNA、FinRE的指标与FinNSP1、FinNSP2的指标之间存在一定的矛盾,往往表现出此消彼长的趋势。然而,我们采用的多专家方法有效地缓解了这种偏差,几乎所有指标都超越了采用混合数据训练的SilverSight-mix模型。此外,我们的方法仅使用总量10%的数据,就能达到与全数据微调模型相媲美的测试成绩,在平均分数上只有1%的差距,在FinNSP2任务上的F1指标甚至为全数据微调模型的2倍。同时,我们发现对每个聚类进行全数据微调的模型,在CFLEB数据集上的表现相较于全数据微调模型有所提升,这充分证明了ASSL框架的有效性。
为验证该LoRA自适应挑选算法的有效性,我们对于聚类后的六个LoRA专家逐一在CFLEB数据集和Fineval数据集上进行测试,如表2与表3所示。实验结果显示,LoRA自适应挑选算法在每个任务上的表现和在该任务上表现最出色的单个LoRA专家相近,证明大多数时候这种LoRA自适应挑选算法均能挑选到最合适的LoRA专家回答问题。
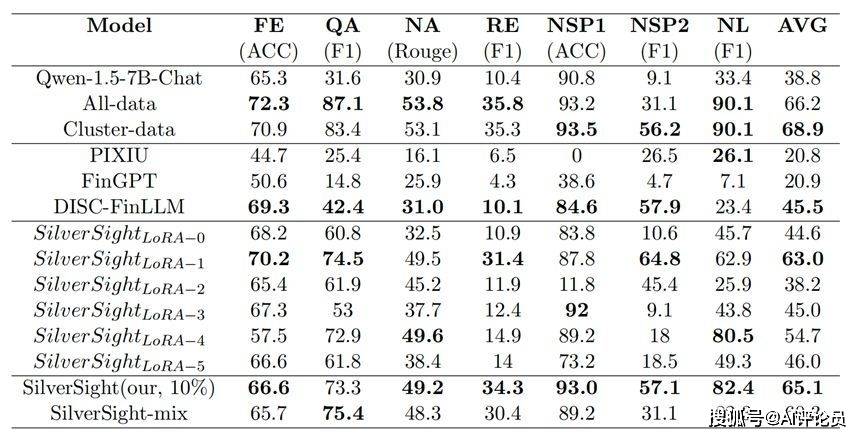
表2 CFLEB的评估结果:All-data表示使用我们收集的所有数据训练的单个模型,Clusterdata表示使用所有聚类数据训练的多专家系统,SilverSight-mix表示使用所有过滤数据训练的单一模型。
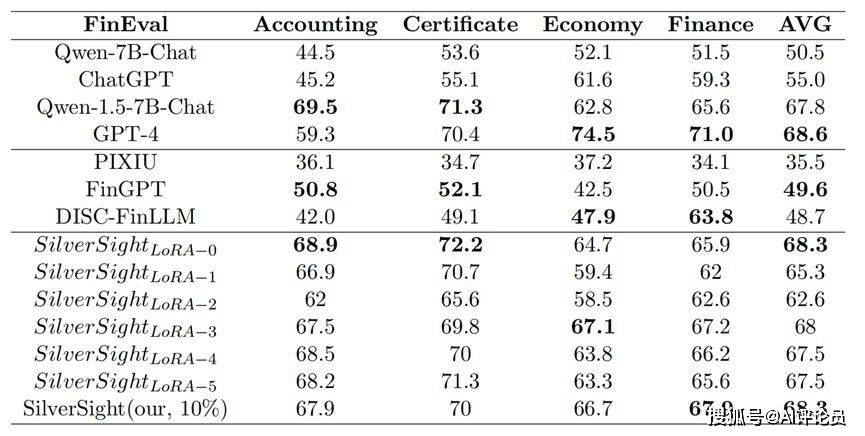
表3Fineval的评估结果:泛化性验证







 京公网安备 11011402013531号
京公网安备 11011402013531号