1月15日讯(记者 朱俊熹)国产开源大模型再添一员强将。1月15日,大模型独角兽MiniMax发布并开源了MiniMax-01全新系列模型,包含基础语言大模型和视觉多模态大模型两个模型。
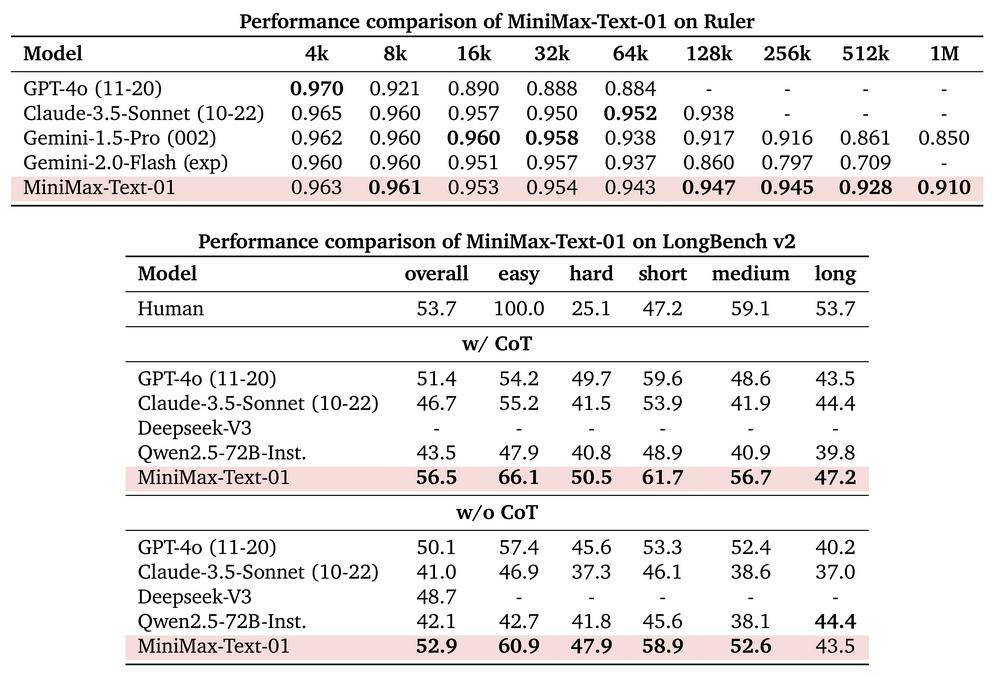
据MiniMax介绍,其基础语言大模型MiniMax-Text-01在多数任务上,追平了GPT-4o、Claude 3.5 Sonnet这两个海外公认最先进的闭源模型。在评估模型指令遵循能力的IFeval和C-SimpleQA中文评测集中,该基础语言大模型的得分也超过了另一国产开源模型DeepSeek-V3。
与DeepSeek模型类似,MiniMax的新系列模型也对传统的Transformer架构进行了创新。MiniMax称,在模型中首次大规模实现了线性注意力机制,每8层中有7个是基于Lightning Attention的线性注意力,有一层是传统的SoftMax注意力。
通俗来讲,如果比喻成要在一群人中找到最重要的那个,传统注意力需要每个人跟其他人都单独聊一遍,逐一比较所有人的重要性。而线性注意力只用查看每个人手中的名片,快速统计出哪些人持有的信息是最重要的。因此,传统注意力机制精准但计算繁重,适合短输入或复杂任务,而线性注意力以其高效更适合超长输入、需要快速处理的任务。
MiniMax在技术报告中提到,正在研究更高效的模型架构,希望能够完全去除SoftMax注意机制,从而实现无限长的上下文窗口,而不会增加计算开销。
幻方量化旗下AI公司DeepSeek在12月底发布了V3开源模型,采用的是创新的多头潜在注意力机制(MLA)和DeepSeekMoE混合专家架构。在节省内存占用和计算资源的同时,确保资源被高效利用。DeepSeek-V3以极低的训练成本实现了对齐领军闭源模型的性能,引发国内外科技社区热议。不仅被前OpenAI联创Andrej Karpathy赞为“在资源受限的情况下对研究和工程的一次令人印象深刻的展示”,也被OpenAI列作中国AI技术快速发展的范例。
围绕线性注意力机制,MiniMax对模型的训练和推理系统进行了重构。其模型包含4560亿个参数,单次推理激活459亿个。能够高效处理最长400万token的上下文,是GPT-4o的32倍,Claude 3.5 Sonnet的20倍。在长上下文的测评集上,MiniMax-Text-01的表现显著领先于其他开闭源模型。
图片MiniMax官网
MiniMax表示,01系列模型将能够支持未来一年内智能体应用的大幅增长需求,因为智能体系统越来越需要更长的上下文处理能力和持续的记忆。“我们相信2025年会是Agent(智能体)高速发展的一年。”该公司称,“在这个模型中,我们走出了第一步,并希望使用这个架构持续建立复杂Agent所需的基础能力。”
智能体正成为国内外AI公司竞相押注的赛道。OpenAI CEO Sam Altman本月初发文称,到2025年,将可能看到第一批AI智能体“加入劳动力队伍”,并实质性地改变公司的产出。谷歌在推出新一代Gemini 2.0大模型时也表示,这是为智能体时代构建的。该模型主打支持多模态输入和输出,以构建出更接近通用助手愿景的智能体。
MiniMax在阐述为何选择将模型开源时提到,一是认为这有可能启发更多长上下文的研究和应用,从而更快促进智能体时代的到来。二是通过开源促使其努力做更多创新,更高质量地开展后续的模型研发工作。
MiniMax成立于2021年12月,被普遍称为国内“大模型六小龙”之一。旗下拥有AI陪伴应用星野,以及集成了对话、视频、音乐功能的海螺AI等代表性产品,在海外市场积累了一定热度。其最新披露的一轮融资还是在去年3月,由阿里领投的6亿美元B轮融资,公司估值达25亿美元。此前腾讯、米哈游、高瓴创投等机构也参投了MiniMax。
六小龙中,各公司的大模型开源进度不一。其中,百川智能、智谱AI、零一万物开源了多款模型,涵盖大语言模型、多模态模型等。而月之暗面、阶跃星辰仅开源了部分技术,例如月之暗面联合清华大学等机构开源的大模型推理架构Mooncake,以及阶跃星辰专注提升光学字符识别(OCR)技术的GOT-OCR2.0模型。








 京公网安备 11011402013531号
京公网安备 11011402013531号