金磊 发自 凹非寺
| 公众号 QbitAI
万万没想到,能把一家公司网站给搞宕机的元凶,竟然是OpenAI疯狂爬虫的机器人—— GPTBot。
(GPTBot是OpenAI早年前推出的一款工具,用来自动抓取整个互联网的数据。)
就在这两天,一家7人团队公司 (Triplegangers)的网站突然宕机,CEO和员工们赶忙排查问题到底出在的哪里。
不查不知道,一查吓一跳。
罪魁祸首正是OpenAI的GPTBot。
从CEO的描述中来看,OpenAI爬虫的“攻势”是有点疯狂在身上的:
我们有超过65000种产品,每种产品都有一个页面,然后每个页面还都有至少三张图片。
OpenAI正在发送数以万计的服务器请求, 试图下载所有内容,包括数十万张照片及其详细描述。
在分析了公司上周的日志之后,团队进一步发现,OpenAI使用了 不止600个IP地址抓取数据。
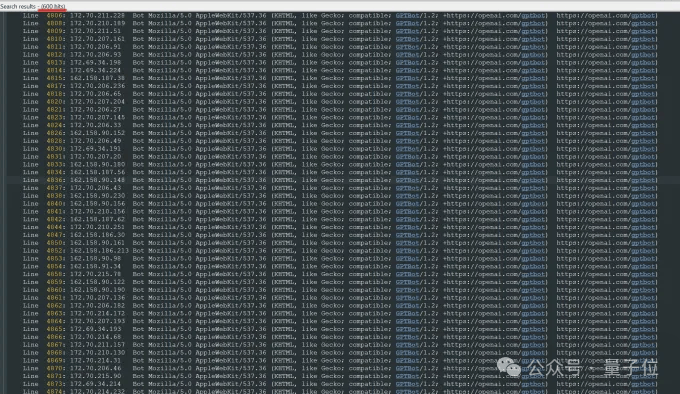
△Triplegangers服务器日志:OpenAI机器人未经许可疯狂爬虫
如此规模的爬虫,就导致这家公司网站的宕机,CEO甚至无奈地表示:
这基本上就是一场 DDoS攻击。
更重要的一点是,由于OpenAI疯狂地爬虫,还会引发了大量的CPU使用和数据下载活动,从而导致网站在云计算服务 (AWS)方面的资源消耗剧增, 开销就会大幅增长……
嗯,AI大公司疯狂爬虫,却由小公司来买单。
这家小型团队的遭遇,也是引发了不少网友们的讨论,有人认为GPTBot的做法并不是抓取,更像是 “偷窃”的委婉说法:
也有网友现身表示有类似的经历,自从阻止了大公司的批量AI爬虫, 省了一大笔钱:
被爬虫到宕机,还不知道被爬走了什么
那么OpenAI为什么要爬虫这家初创企业的数据?
简单来说,它家的数据确实属于高质量的那种。
据了解,Triplegangers的7名成员花费了十多年的时间,打造了号称 最大“人类数字孪生”数据库
网站包含从实际人类模型扫描的3D图像文件,并且照片还带有详细的标签,涵盖种族、年龄、纹身与疤痕、各种体型等信息。
这对于需要数字化再现真实人类特征的3D艺术家、游戏制作者等,无疑具有重要价值。
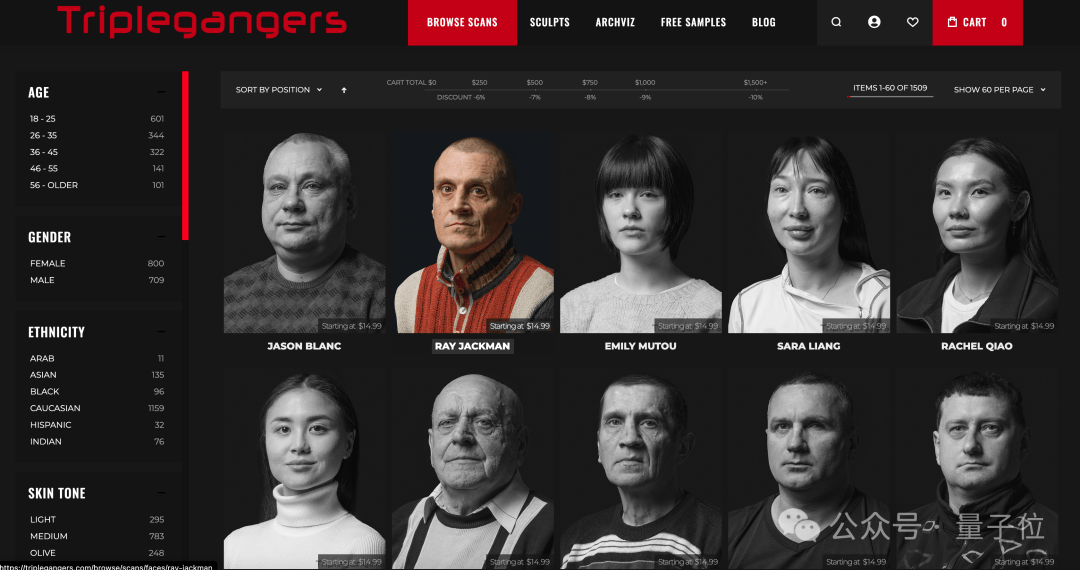
虽然Triplegangers网站上有一个服务条款页面,里面明确写了禁止未经许可的AI抓取他们家的图片。
但从目前的结果上来看,这完全没有起到任何作用。
重点在于,Triplegangers没有正确配置一个文件—— Robot.txt。
Robot.txt也称为机器人排除协议,是为了告诉搜索引擎网站在索引网络时不要爬取哪些内容而创建的。
也就是说,一个网站要是不想被OpenAI爬虫,那就必须正确配置Robot.txt文件,并带有特定标签,明确告诉GPTBot不要访问该网站。
但OpenAI除了GPTBot之外,还有 ChatGPT-User和 OAI-SearchBot,它俩也有各自对应的标签:

而且根据OpenAI官方发布的爬虫信息来看,即便你立即正确设置了Robot.txt文件,也不会立即生效。
CEO老哥对此表示:
如果一个网站没有正确配置Robot.txt文件,那么OpenAI和其它公司会认为他们可以随心所欲地抓取内容。
这不是一个可选的系统。
正因如此,也就有了Triplegangers在工作时间段网站被搞宕机,还搭上了高额的AWS费用。
截至美东时间的本周三,Triplegangers已经按照要求配置了正确的Robot.txt文件。
以防万一,团队还设置了一个Cloudflare账户来阻止其它的AI爬虫,如Barkrowler和Bytespider。

虽然到了周四开工的时候,Triplegangers没有再出现宕机的情况,但CEO老哥还有个悬而未决的困惑——
不知道OpenAI都从网站中爬了些什么数据,也联系不上OpenAI……
而且令CEO老哥更加深表担忧的一点是:
如果不是GPTBot“贪婪”到让我们的网站宕机,我们可能不知道它一直在爬取我们的数据。
这个过程是有bug的,即便你们AI大公司说了可以配置Robot.txt来防止爬虫,但你们把责任推到了我们身上。
最后,CEO老哥也呼吁众多在线企业,要想防止大公司未经允许爬虫,一定要主动、积极地去查找问题。
并不是第一例
但Triplegangers并不是第一个因为OpenAI疯狂爬虫导致宕机的公司。
在此之前,还有 Game UI Database这家公司。
它收录了超56000张游戏用户界面截图的在线数据库,用于供游戏设计师参考。
有一天,团队发现网站加载速度变慢,页面加载时间延长三倍,用户频繁遭遇502错误,首页每秒被重新加载200次。
他们一开始也以为是遭到了DDoS攻击,结果一查日志……是OpenAI,每秒查询2次,导致网站几乎瘫痪。
但你以为如此疯狂爬虫的只有OpenAI吗?
非也,非也。
例如 Anthropic此前也被曝出来过类似的事情。
数字产品工作室 Planetary的创始人Joshua Gross曾表示过,他们给客户重新设计的网站上线后,流量激增,导致客户云成本翻倍。
经审计发现,大量流量来自抓取机器人,主要是Anthropic导致的无意义流量,大量请求都返回404错误。

针对这一现象,来自数字广告公司DoubleVerify的一份新研究显示,AI爬虫在2024 年导致“一般无效流量” (不是来自真实用户的流量)增加了86%。
那么AI公司,尤其是大模型公司,为什么要如此疯狂地“吸食”网络上的数据?
一言蔽之,就是他们太缺用来训练的高质量数据了。
有研究估计过,到2032年全球可用的AI训练数据可能就会耗尽,这就让AI公司加快了数据收集的速度。
而且连价格都标好了,如果是为YouTube、Instagram和TikTok准备的未发布视频, 每分钟出价为1~2美元(总体一般是1~4美元),且根据视频质量和格式的不同,价格还能再涨涨。

那么你对这一现象有什么看法呢?欢迎在评论区留言讨论~
参考链接:
[1] https://techcrunch.com/2025/01/10/how-openais-bot-crushed-this-seven-person-companys-web-site-like-a-ddos-attack/
[2]https://www.reddit.com/r/webscraping/comments/1bapx0j/how_did_openai_scrap_the_entire_internet_for/
[3]https://www.marktechpost.com/2023/08/10/openai-introduces-gptbot-a-web-crawler-designed-to-scrape-data-from-the-entire-internet-automatically/
[4]https://platform.openai.com/docs/bots/overview-of-openai-crawlers
[5]https://www.businessinsider.com/openai-anthropic-ai-bots-havoc-raise-cloud-costs-websites-2024-9
— 完—
年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用, 365行AI落地方案
或与我们分享你在 寻找的AI产品,或发现的 AI新动向








 京公网安备 11011402013531号
京公网安备 11011402013531号