600万美金训出击败GPT-4o大模型,竟被中国团队实现了!
01
国产开源模型刷爆全球科技圈
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
近日,国产开源大模型DeepSeek-V3凭借其卓越的性能和极低的训练成本,在全球科技圈引发了广泛关注和热议。这款由中国深度求索公司推出的AI大模型,不仅在技术上取得了突破性进展,更以开源的形式,为全球开发者提供了强大的工具,标志着中国在人工智能领域的崛起。
12月26日晚,幻方量化旗下AI公司深度求索(DeepSeek)宣布,全新系列模型DeepSeek-V3上线并同步开源,API服务已同步更新,接口配置无需改动,登录官网(chat.deepseek.com)即可与最新版 V3 模型对话。当前版本的 DeepSeek-V3 暂不支持多模态输入输出。

具体来说,DeepSeek-V3是一个具有6710亿总参数的MoE(混合专家)模型,每token激活参数为370亿,在14.8万亿token上进行了预训练。
官方给出的数据显示,DeepSeek-V3多项评测成绩超越了阿里通义的Qwen2.5-72B 和meta的Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及Claude-3.5-Sonnet 不分伯仲。

Deepseek的中文名是“深度求索”,为量化巨头幻方量化的子公司。在硅谷,DeepSeek则被称作“来自东方的神秘力量”。
这一次,幻方量化究竟为大模型赛道带来了一款怎样的产品?
02
性能匹敌OpenAI GPT-4o
对于任何一个想要在大模型赛道上冒头的新人而言,OpenAI GPT-4o、meta Llama-3.1-405B等成名许久的前辈都是需要挑战的对象,DeepSeek-V3能够快速引爆全球科技圈关注,正是得益于其不输前辈的性能。
DeepSeek-V3拥有6710亿参数的自研MoE(Mixture of Experts)架构,经过14.8万亿token的预训练,在多项基准测试中表现优异,甚至超越了包括Qwen2.5-72B和Llama-3.1-405B在内的其他开源模型,与世界顶尖的闭源模型GPT-4o和Claude-3.5-Sonnet不相上下。

据最新发布的DeepSeek-V3技术报告,在英语、代码、数学、汉语以及多语言任务上,基础模型 DeepSeek-V3 base的表现非常出色,在 AGIeval、CMath、MMMLU-non-English 等一些任务上甚至远远超过其它开源大模型。就算与 GPT-4o 和 Claude 3.5 Sonnet 这两大领先的闭源模型相比,DeepSeek-V3 也毫不逊色,并且在 MATH 500、AIME 2024、Codeforces 上都有明显优势——
·百科知识:DeepSeek-V3 在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代 DeepSeek-V2.5 显著提升,接近当前表现最好的模型 Claude-3.5-Sonnet-1022。
·长文本:在长文本测评中,DROP、frameS 和 LongBench v2 上,DeepSeek-V3 平均表现超越其他模型。
·代码:DeepSeek-V3 在算法类代码场景(Codeforces),远远领先于市面上已有的全部非 o1 类模型;并在工程类代码场景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
·数学:在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3 大幅超过了所有开源闭源模型。
·中文能力:DeepSeek-V3 与 Qwen2.5-72B 在教育类测评 C-eval 和代词消歧等评测集上表现相近,但在事实知识 C-SimpleQA 上更为领先。
非常有意思的是DeepSeek-V3虽然拥有高达6710亿的参数量,但每次推理仅激活370亿参数,这种设计使得它在保持高性能的同时,也具备了高效性。这一特点在全球范围内都极为罕见,使得DeepSeek-V3一经发布,便受到了技术社区的高度关注。

DeepSeek-V3之所以能取得如此优异的成绩,得益于其多项创新技术。
DeepSeek-V3采用了混合专家(MoE)架构,这是一种机器学习架构,通过组合多个专家模型,在处理复杂任务时能够显著提升效率和准确度。DeepSeek-V3的MoE架构包含256个专家,每次计算时动态选择前8个最相关的专家参与,这种设计既提高了计算效率,又确保了模型的准确性。
与此同时,DeepSeek-V3采用了无辅助损失的负载平衡策略,并设定了多token预测训练目标,提高了数据效率和模型的生成速度,使其生成吐字速度从20TPS大幅提升至60TPS,相比上代实现了3倍的提升。其预训练数据达到了14.8万亿,并且在数据处理流程上进行了改进,进一步提升了数据质量和模型性能。
此外,DeepSeek-V3还采用了创新的知识蒸馏方法,将推理能力迁移到标准LLM中,同时保留输出风格和长度控制,这种技术不仅提高了模型的推理性能,还使得模型在应用上更加灵活。
03
超低训练成本惊呆AI圈
单看性能,DeepSeek-V3作为大模型赛道“新人”,其上演“长江后浪推前浪”的戏码并没啥问题,事实上,真正让DeepSeek-V3刷爆科技圈的也并非性能,而是成本!
每一款大模型的诞生和成长,都离不开训练。
深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,meta的大模型Llama-3.1的训练投资超过了5亿美元。

这意味着DeepSeek-V3拥有极高的性价比,具体到GPU小时上的话,DeepSeek-V3训练仅需266.4万H800 GPU小时,加上上下文扩展与后训练,总计也不过278.8万GPU小时。与之对比,Llama3-405B的训练数据则高达3080万H100 GPU小时,DeepSeek-V3的训练成本优势可见一斑。这使得更多的企业和开发者能够承担起使用这一模型的成本,进一步推动了AI技术的普及和应用。
尤其是因为美国的出口管制限制,DeepSeek-V3无法使用最顶尖的NVIDIA GPU集群,但开发者们通过优化训练方法,在2048个带宽缩减版NVIDIA H800 GPU集群上实现了同样的效果。这种创新不仅展示了中国团队的技术实力,也打破了国际科技巨头对高端硬件资源的垄断。
OpenAI创始成员Karpathy甚至对此称赞道 :“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
较低的训练成本,让DeepSeek-V3能够提供极具性价比的API价格。
目前,DeepSeek-V3正式定价为每百万输入tokens 0.5元(缓存命中)/2元(未命中),输出tokens每百万8元。这一价格远低于市场上其他大型语言模型的API价格,如Claude 3.5 Sonnet的输入价格为3美元/百万,输出价格为15美元/百万。DeepSeek-V3的优惠价格使得更多用户能够负担得起使用大型语言模型的费用。

为了回馈用户,DeepSeek-V3还推出了45天的限时优惠活动。在优惠期间,API使用费最高直降80%,即每百万输入tokens 0.1元(缓存命中)/1元(未命中),输出tokens每百万仅2元。这一活动进一步降低了用户的使用成本,使得更多用户能够体验到DeepSeek-V3的强大功能。
事实上,早在DeepSeek-V2时期,深度求索就打出了API“价格战”。
2024年5月6日,幻方旗下深度求索(Deepseek)发布最新MoE模型DeepSeek-V2,并将模型的 API定价为:每百万tokens输入 1元、输出2元(32K 上下文),价格仅为 GPT-4-Turbo 的近百分之一,刷新了大模型 API 的低价记录。随后,部分国内大模型初创公司、互联网厂商、科技公司等陆续宣布模型 AP| 降价,有些甚至将 API 免费提供。
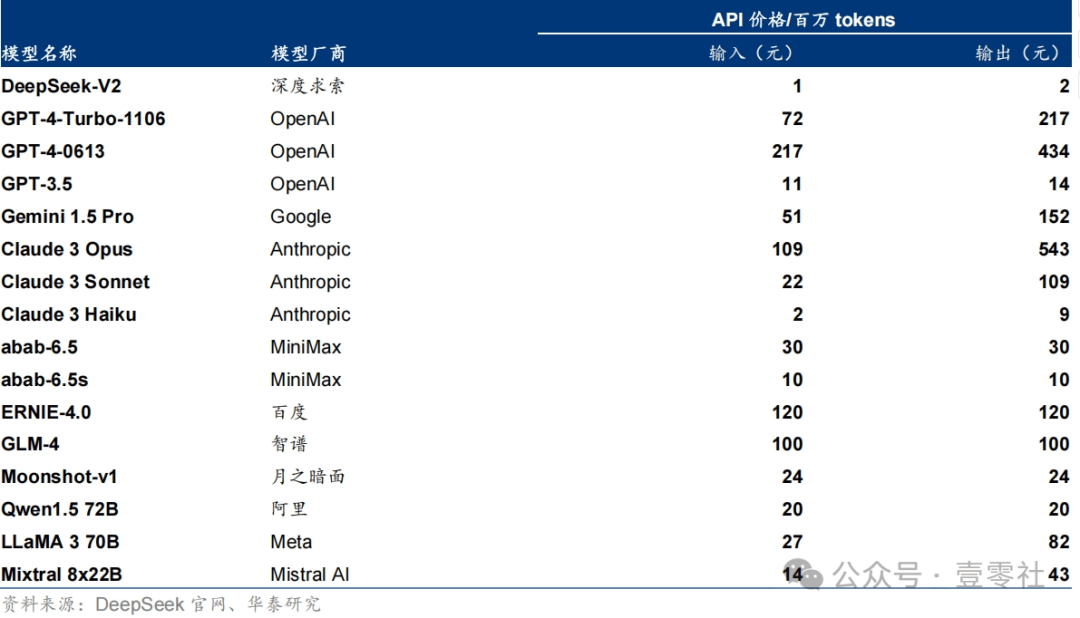
幻方 DeepSeek V2 价格仅为 GPT-4-Turbo 的近百分之一
而实现这一切的关键在于“技术降价”。
技术上看,确实能够通过优化 Transformer 架构中的各个部件,实现推理成本的降低。DeepSeek V2 本身就是典型的实践,其降本逻辑在于:改进的 MOE 架构,降低训练成本;优化的 KV cache 机制,大幅降低推理成本。
如果其他国内模型厂商,同样在底层应用了类似的优化技术,那么降本就是已经发生的过去式,DeepSeekV2 在5月的降价或是激发各厂家拿出“技术降本”结果。字节火山引擎总裁谭待在 5月豆包发布会上也指明,降价的背后主要原因是技术,未来还有很多手段继续降低成本,并不亏损。
从DeepSeek V2开始,深度求索就引入MLA多头隐注意力机制,大幅降低了KV cache的大小。而DeepSeek-V3对于成本的降低主要可分训练成本和推理成本两个方面。
在降低训练成本上,DeepSeek-V3引入了FP8混合精度训练框架,首次验证了FP8训练在超大规模模型上的可行性和有效性。通过使用低精度数据格式进行训练,加速了训练过程并减少了内存使用,从而降低了训练成本,并引入DualPipe双向流水线,通过重叠前向和后向计算与通信来减少流水线气泡,提高了训练效率。高效的跨节点通信内核利用IB和NVlink带宽,进一步减少了通信开销。
而在降低推理成本上,DeepSeek-V3采用了混合专家模型(MoE)架构,每个专家模型只处理部分输入,提高了模型的效率和扩展性。通过优化MoE架构中的专家负载均衡,进一步降低了推理成本。MLA(Multi-Head Latent Attention)机制则通过低秩压缩减少KV缓存,提高了推理效率。这种机制减少了推理过程中的计算量,从而降低了推理成本。
此外,DeepSeek-V3将DeepSeek-R1的推理模式融入其中,提高了模型的推理性能,借助提炼和优化推理能力,进一步降低了推理成本。
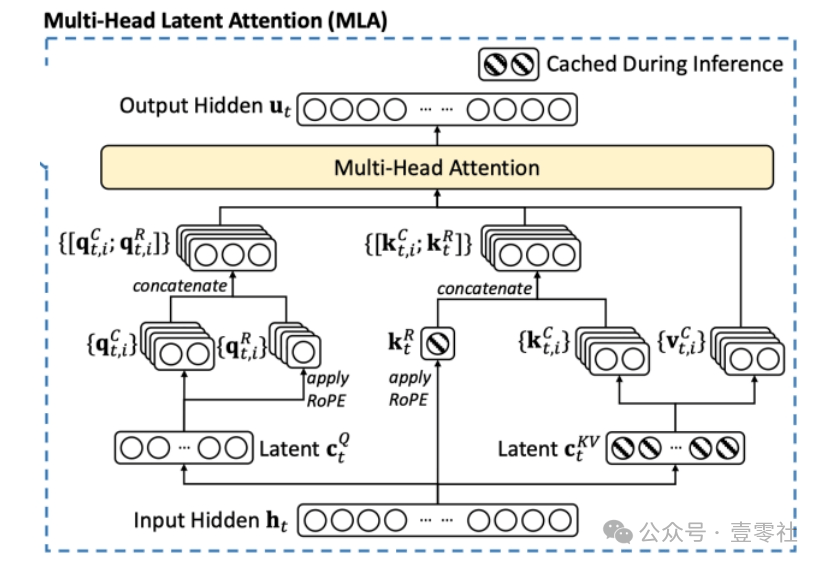
MLA 注意力机制示意图
值得一提的是降价并不是国内“特色”,OpenAl已经进行了多次降价。OpenAl的 GPT-3.5 turbo 系列从 23年3月问世以来,已经经历了三次降价,最新价格与最初价格相比,输入价格降低了75%,输出价格降低了 25%,上下文长度提升 4x;GPT-4 系列的 turbo 与 40 版本出现后也在屡次刷新 OpenAl 模型的价格底线。
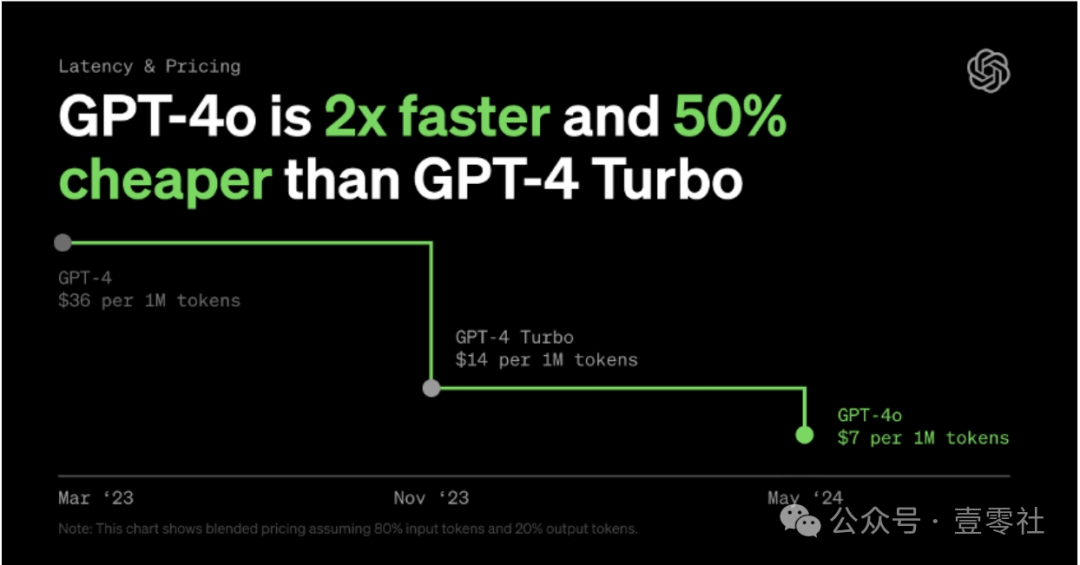
GPT-4 系列价格也在逐渐降低
在这种情况下,借 DeepSeek“技术降价”引起的大模型降本浪潮,通过压低价格吸引应用开发者,或是培养自身开发者生态的重要举措。开发者生态的繁荣,是形成“数据和场景→模型迭代→模型性能提升→更多开发者→更多数据”正向反馈的重要基础,短期牺牲部分成本,长期看或仍然划算。
04
国产大模型的转折点
自20年初GPT-4发布以来,在1年左右时间内基本稳定处于大模型最强位置。2024年海外大模型迭代速度有所加快,龙头竞争格局悄然发生变化。
5月,0penAl发布新的旗舰模型GPT-40:实现跨模态即时响应,相比GPT-4 Turbo,刷新SOTA实现性能飞跃。同月,Google发布Gemini1.5 Pro进阶版,实现200万tokens上下文,具备更强大的推理和理解能力。6月,Antropic发布Claude 3.5 Sonnet,具备更强的代码和视觉能力,基准测试结果全方位碾压Gemini 1.5 Pro和Llama-400b,大部分优于 GPT-4o,一定程度上暂时代表着当前大模型性能最高水平。

海外龙头竞相抢占大模型第一宝座
整体比较而言,国内大模型与GPT-4(官网)尚存在明显差距,但个别能力上已展现出优势,尤其是在长文本理解和应用上,国内长文本能力赶超了部分国外大模型。

国内外大模型的长文本能力比较
抢占长文本这样的细分赛道外,降价抢占API调用量,撬动大模型“飞轮迭代”也成为国内大模型企业崛起的关键。
随着技术进步和市场竞争,大模型训练&推理成本降低,国内大模型厂商纷纷降价,以吸引用户和提高市场份额。这里要提一句的是,降价不等于恶性竟争和模型缺陷,更多的是在技术支持下商业逻辑的打磨与模型能力的完善,与其是DeepSeek“技术降价”,更成为国内大模型企业崛起的关键。
短期来看大模型性能提升遇到瓶颈,同质化严重,包括0penAl的用户增速陷入了低迷期,降价是吸引更多开发者参与进来最直接的方法。
调用量提升能够抢夺更多的开发者→激活更多的应用场景与生态→验证大模型业务价值→加速送代打磨出更好的模型→增强开发者粘性。对于大模型企业而言,只有吸引越多的开发者,才能缔造更繁荣的应用生态、催生更多的应用创新。应用生态越完善,使用场景越多,用户规模越大,生成的新数据会反哺大模型性能提升。

在这过程中,开发者是核心角色。既可能通过反复调用模型打造出应用生态并提供了模型优化建议,而且可能在开发出应用后与大模型生态捆绑,从而增强大模型粘性。
此次DeepSeek-V3的推出被视为中国AI技术从“追赶”到“领先”的转折点。它不仅在技术上实现了对国际顶尖模型的超越,还通过低成本和高性能的商业模式,为全球AI应用的推广提供了新的路径。未来,随着技术的进一步优化和硬件成本的降低,DeepSeek-V3有望在教育、医疗、金融等多个领域发挥更大的作用。
从某种意义上讲,DeepSeek-V3的成功不仅是技术上的胜利,更是中国在AI领域的一次重要突破。它不仅展示了中国团队在技术创新和开源精神上的卓越能力,也为全球AI技术的发展提供了新的思路和方向。这场“国产之光”的盛宴,无疑将激励更多的开发者和研究者投身于AI技术的探索与创新之中。









 京公网安备 11011402013531号
京公网安备 11011402013531号